 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
Cobra: Efficient Line Art COlorization with BRoAder References
Apr 16, 2025The comic production industry requires reference-based line art colorization with high accuracy, efficiency, contextual consistency, and flexible control. A comic page often involves diverse characters, objects, and backgrounds, which complicates the coloring process. Despite advancements in diffusion models for image generation, their application in line art colorization remains limited, facing challenges related to handling extensive reference images, time-consuming inference, and flexible control. We investigate the necessity of extensive contextual image guidance on the quality of line art colorization. To address these challenges, we introduce Cobra, an efficient and versatile method that supports color hints and utilizes over 200 reference images while maintaining low latency. Central to Cobra is a Causal Sparse DiT architecture, which leverages specially designed positional encodings, causal sparse attention, and Key-Value Cache to effectively manage long-context references and ensure color identity consistency. Results demonstrate that Cobra achieves accurate line art colorization through extensive contextual reference, significantly enhancing inference speed and interactivity, thereby meeting critical industrial demands. We release our codes and models on our project page: https://zhuang2002.github.io/Cobra/.
FullDiT: Multi-Task Video Generative Foundation Model with Full Attention
Mar 25, 2025Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.
VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control
Mar 07, 2025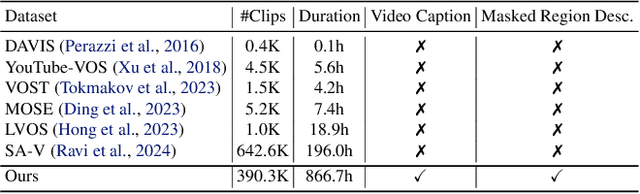
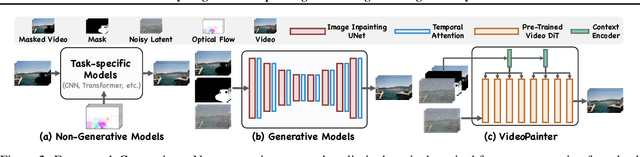
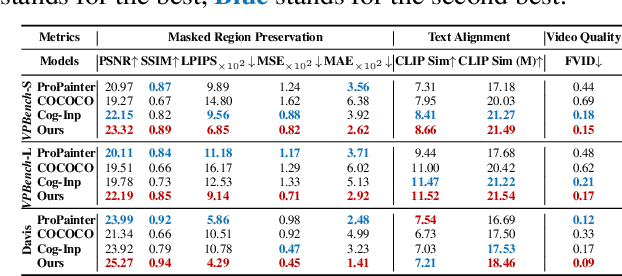
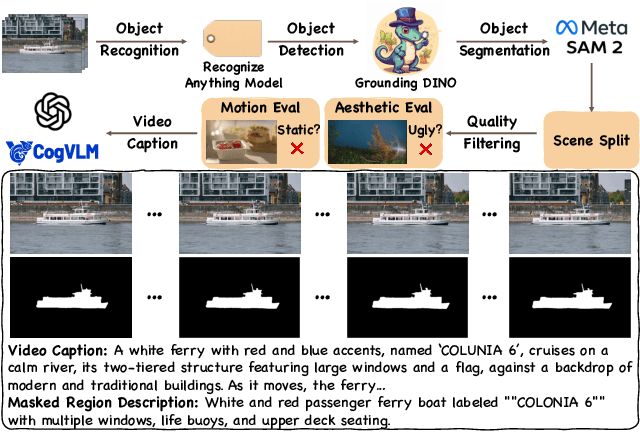
Video inpainting, which aims to restore corrupted video content, has experienced substantial progress. Despite these advances, existing methods, whether propagating unmasked region pixels through optical flow and receptive field priors, or extending image-inpainting models temporally, face challenges in generating fully masked objects or balancing the competing objectives of background context preservation and foreground generation in one model, respectively. To address these limitations, we propose a novel dual-stream paradigm VideoPainter that incorporates an efficient context encoder (comprising only 6% of the backbone parameters) to process masked videos and inject backbone-aware background contextual cues to any pre-trained video DiT, producing semantically consistent content in a plug-and-play manner. This architectural separation significantly reduces the model's learning complexity while enabling nuanced integration of crucial background context. We also introduce a novel target region ID resampling technique that enables any-length video inpainting, greatly enhancing our practical applicability. Additionally, we establish a scalable dataset pipeline leveraging current vision understanding models, contributing VPData and VPBench to facilitate segmentation-based inpainting training and assessment, the largest video inpainting dataset and benchmark to date with over 390K diverse clips. Using inpainting as a pipeline basis, we also explore downstream applications including video editing and video editing pair data generation, demonstrating competitive performance and significant practical potential. Extensive experiments demonstrate VideoPainter's superior performance in both any-length video inpainting and editing, across eight key metrics, including video quality, mask region preservation, and textual coherence.
ColorFlow: Retrieval-Augmented Image Sequence Colorization
Dec 16, 2024Automatic black-and-white image sequence colorization while preserving character and object identity (ID) is a complex task with significant market demand, such as in cartoon or comic series colorization. Despite advancements in visual colorization using large-scale generative models like diffusion models, challenges with controllability and identity consistency persist, making current solutions unsuitable for industrial application.To address this, we propose ColorFlow, a three-stage diffusion-based framework tailored for image sequence colorization in industrial applications. Unlike existing methods that require per-ID finetuning or explicit ID embedding extraction, we propose a novel robust and generalizable Retrieval Augmented Colorization pipeline for colorizing images with relevant color references. Our pipeline also features a dual-branch design: one branch for color identity extraction and the other for colorization, leveraging the strengths of diffusion models. We utilize the self-attention mechanism in diffusion models for strong in-context learning and color identity matching. To evaluate our model, we introduce ColorFlow-Bench, a comprehensive benchmark for reference-based colorization. Results show that ColorFlow outperforms existing models across multiple metrics, setting a new standard in sequential image colorization and potentially benefiting the art industry. We release our codes and models on our project page: https://zhuang2002.github.io/ColorFlow/.
BrushEdit: All-In-One Image Inpainting and Editing
Dec 13, 2024



Image editing has advanced significantly with the development of diffusion models using both inversion-based and instruction-based methods. However, current inversion-based approaches struggle with big modifications (e.g., adding or removing objects) due to the structured nature of inversion noise, which hinders substantial changes. Meanwhile, instruction-based methods often constrain users to black-box operations, limiting direct interaction for specifying editing regions and intensity. To address these limitations, we propose BrushEdit, a novel inpainting-based instruction-guided image editing paradigm, which leverages multimodal large language models (MLLMs) and image inpainting models to enable autonomous, user-friendly, and interactive free-form instruction editing. Specifically, we devise a system enabling free-form instruction editing by integrating MLLMs and a dual-branch image inpainting model in an agent-cooperative framework to perform editing category classification, main object identification, mask acquisition, and editing area inpainting. Extensive experiments show that our framework effectively combines MLLMs and inpainting models, achieving superior performance across seven metrics including mask region preservation and editing effect coherence.
MotionCLR: Motion Generation and Training-free Editing via Understanding Attention Mechanisms
Oct 24, 2024This research delves into the problem of interactive editing of human motion generation. Previous motion diffusion models lack explicit modeling of the word-level text-motion correspondence and good explainability, hence restricting their fine-grained editing ability. To address this issue, we propose an attention-based motion diffusion model, namely MotionCLR, with CLeaR modeling of attention mechanisms. Technically, MotionCLR models the in-modality and cross-modality interactions with self-attention and cross-attention, respectively. More specifically, the self-attention mechanism aims to measure the sequential similarity between frames and impacts the order of motion features. By contrast, the cross-attention mechanism works to find the fine-grained word-sequence correspondence and activate the corresponding timesteps in the motion sequence. Based on these key properties, we develop a versatile set of simple yet effective motion editing methods via manipulating attention maps, such as motion (de-)emphasizing, in-place motion replacement, and example-based motion generation, etc. For further verification of the explainability of the attention mechanism, we additionally explore the potential of action-counting and grounded motion generation ability via attention maps. Our experimental results show that our method enjoys good generation and editing ability with good explainability.
Adding Multimodal Controls to Whole-body Human Motion Generation
Aug 04, 2024
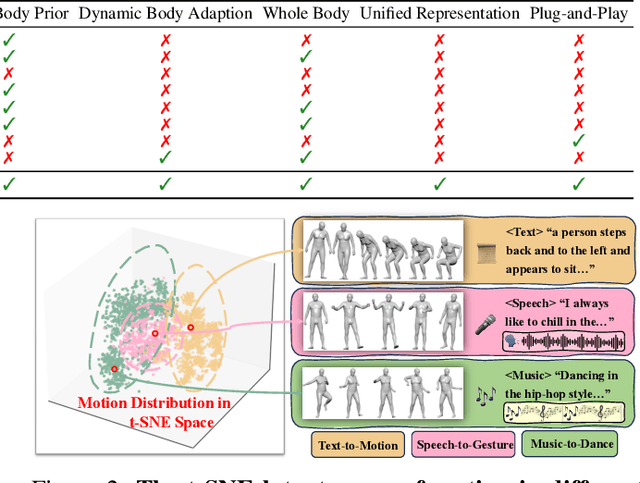
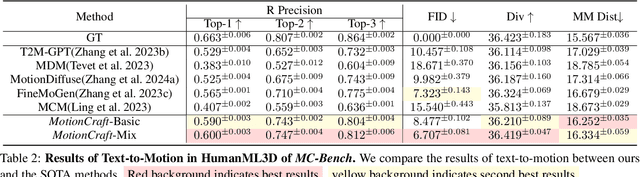
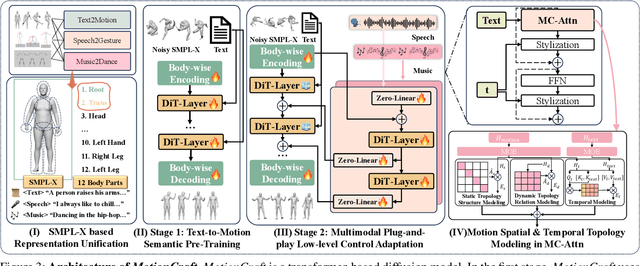
Whole-body multimodal motion generation, controlled by text, speech, or music, has numerous applications including video generation and character animation. However, employing a unified model to accomplish various generation tasks with different condition modalities presents two main challenges: motion distribution drifts across different generation scenarios and the complex optimization of mixed conditions with varying granularity. Furthermore, inconsistent motion formats in existing datasets further hinder effective multimodal motion generation. In this paper, we propose ControlMM, a unified framework to Control whole-body Multimodal Motion generation in a plug-and-play manner. To effectively learn and transfer motion knowledge across different motion distributions, we propose ControlMM-Attn, for parallel modeling of static and dynamic human topology graphs. To handle conditions with varying granularity, ControlMM employs a coarse-to-fine training strategy, including stage-1 text-to-motion pre-training for semantic generation and stage-2 multimodal control adaptation for conditions of varying low-level granularity. To address existing benchmarks' varying motion format limitations, we introduce ControlMM-Bench, the first publicly available multimodal whole-body human motion generation benchmark based on the unified whole-body SMPL-X format. Extensive experiments show that ControlMM achieves state-of-the-art performance across various standard motion generation tasks. Our website is at https://yxbian23.github.io/ControlMM.