 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersusQ: Pairwise Margin Reasoning for Generalizable Video Quality Assessment
May 20, 2026Large Multimodal Models (LMMs) have shown promise for video quality assessment, but most methods still predict an absolute score for each video. Such pointwise supervision often mixes perceptual quality with dataset-specific calibration, including annotation protocols, rating habits, and score distributions. As a result, the learned scoring rule may work well within a benchmark but transfer poorly across unseen domains. We argue that relative comparisons alleviate the absolute-scale calibration bias by focusing purely on perceptual differences rather than dataset-specific rating habits. Consequently, we propose \textbf{VersusQ}, a pairwise margin reasoning framework driven entirely by direct comparisons. Specifically, VersusQ performs LMM-based comparison between two videos, reasons about their visual and temporal quality differences, and predicts a signed continuous margin that captures both the preferred choice and the degree of difference. Furthermore, to align interpretable comparison rationales with fine-grained numerical differences, we introduce Margin-Coupled GRPO, which jointly optimizes rollout-based relational reasoning and continuous margin regression. Extensive experiments on multiple public VQA benchmarks demonstrate that VersusQ achieves state-of-the-art performance, strong cross-domain generalization, and reliable fine-grained ranking under heterogeneous evaluation scenarios.
From Craft to Kernel: A Governance-First Execution Architecture and Semantic ISA for Agentic Computers
Apr 20, 2026The transition of agentic AI from brittle prototypes to production systems is stalled by a pervasive crisis of craft. We suggest that the prevailing orchestration paradigm-delegating the system control loop to large language models and merely patching with heuristic guardrails-is the root cause of this fragility. Instead, we propose Arbiter-K, a Governance-First execution architecture that reconceptualizes the underlying model as a Probabilistic Processing Unit encapsulated by a deterministic, neuro-symbolic kernel. Arbiter-K implements a Semantic Instruction Set Architecture (ISA) to reify probabilistic messages into discrete instructions. This allows the kernel to maintain a Security Context Registry and construct an Instruction Dependency Graph at runtime, enabling active taint propagation based on the data-flow pedigree of each reasoning node. By leveraging this mechanism, Arbiter-K precisely interdicts unsafe trajectories at deterministic sinks (e.g., high-risk tool calls or unauthorized network egress) and enables autonomous execution correction and architectural rollback when security policies are triggered. Evaluations on OpenClaw and NanoBot demonstrate that Arbiter-K enforces security as a microarchitectural property, achieving 76% to 95% unsafe interception for a 92.79% absolute gain over native policies. The code is publicly available at https://github.com/cure-lab/ArbiterOS.
DiffHLS: Differential Learning for High-Level Synthesis QoR Prediction with GNNs and LLM Code Embeddings
Apr 10, 2026High-Level Synthesis (HLS) compiles C/C++ into RTL, but exploring pragma-driven optimization choices remains expensive because each design point requires time-consuming synthesis. We propose \textbf{\DiffHLS}, a differential learning framework for HLS Quality-of-Result (QoR) prediction that learns from kernel--design pairs: a kernel baseline and a pragma-inserted design variant. \DiffHLS~encodes kernel and design intermediate-representation graphs with dedicated graph neural network (GNN) branches, and augments the delta pathway with code embeddings from a pretrained code large language model (LLM). Instead of regressing absolute targets directly, we jointly predict the kernel baseline and the design-induced delta, and compose them to obtain the design prediction. On PolyBench, \DiffHLS~attains lower average MAPE than GNN baselines under four GNN backbones, and LLM code embeddings consistently improve over a GNN-only ablation. We further validate scalability on the ForgeHLS dataset.
FBCIR: Balancing Cross-Modal Focuses in Composed Image Retrieval
Mar 12, 2026Composed image retrieval (CIR) requires multi-modal models to jointly reason over visual content and semantic modifications presented in text-image input pairs. While current CIR models achieve strong performance on common benchmark cases, their accuracies often degrades in more challenging scenarios where negative candidates are semantically aligned with the query image or text. In this paper, we attribute this degradation to focus imbalances, where models disproportionately attend to one modality while neglecting the other. To validate this claim, we propose FBCIR, a multi-modal focus interpretation method that identifies the most crucial visual and textual input components to a model's retrieval decisions. Using FBCIR, we report that focus imbalances are prevalent in existing CIR models, especially under hard negative settings. Building on the analyses, we further propose a CIR data augmentation workflow that facilitates existing CIR datasets with curated hard negatives designed to encourage balanced cross-modal reasoning. Extensive experiments across multiple CIR models demonstrate that the proposed augmentation consistently improves performance in challenging cases, while maintaining their capabilities on standard benchmarks. Together, our interpretation method and data augmentation workflow provide a new perspective on CIR model diagnosis and robustness improvements.
Position: Universal Time Series Foundation Models Rest on a Category Error
Feb 05, 2026This position paper argues that the pursuit of "Universal Foundation Models for Time Series" rests on a fundamental category error, mistaking a structural Container for a semantic Modality. We contend that because time series hold incompatible generative processes (e.g., finance vs. fluid dynamics), monolithic models degenerate into expensive "Generic Filters" that fail to generalize under distributional drift. To address this, we introduce the "Autoregressive Blindness Bound," a theoretical limit proving that history-only models cannot predict intervention-driven regime shifts. We advocate replacing universality with a Causal Control Agent paradigm, where an agent leverages external context to orchestrate a hierarchy of specialized solvers, from frozen domain experts to lightweight Just-in-Time adaptors. We conclude by calling for a shift in benchmarks from "Zero-Shot Accuracy" to "Drift Adaptation Speed" to prioritize robust, control-theoretic systems.
\textit{FocaLogic}: Logic-Based Interpretation of Visual Model Decisions
Jan 17, 2026Interpretability of modern visual models is crucial, particularly in high-stakes applications. However, existing interpretability methods typically suffer from either reliance on white-box model access or insufficient quantitative rigor. To address these limitations, we introduce FocaLogic, a novel model-agnostic framework designed to interpret and quantify visual model decision-making through logic-based representations. FocaLogic identifies minimal interpretable subsets of visual regions-termed visual focuses-that decisively influence model predictions. It translates these visual focuses into precise and compact logical expressions, enabling transparent and structured interpretations. Additionally, we propose a suite of quantitative metrics, including focus precision, recall, and divergence, to objectively evaluate model behavior across diverse scenarios. Empirical analyses demonstrate FocaLogic's capability to uncover critical insights such as training-induced concentration, increasing focus accuracy through generalization, and anomalous focuses under biases and adversarial attacks. Overall, FocaLogic provides a systematic, scalable, and quantitative solution for interpreting visual models.
GNN-based Path-aware multi-view Circuit Learning for Technology Mapping
Jan 14, 2026Traditional technology mapping suffers from systemic inaccuracies in delay estimation due to its reliance on abstract, technology-agnostic delay models that fail to capture the nuanced timing behavior behavior of real post-mapping circuits. To address this fundamental limitation, we introduce GPA(graph neural network (GNN)-based Path-Aware multi-view circuit learning), a novel GNN framework that learns precise, data-driven delay predictions by synergistically fusing three complementary views of circuit structure: And-Inverter Graphs (AIGs)-based functional encoding, post-mapping technology emphasizes critical timing paths. Trained exclusively on real cell delays extracted from critical paths of industrial-grade post-mapping netlists, GPA learns to classify cut delays with unprecedented accuracy, directly informing smarter mapping decisions. Evaluated on the 19 EPFL combinational benchmarks, GPA achieves 19.9%, 2.1% and 4.1% average delay reduction over the conventional heuristics methods (techmap, MCH) and the prior state-of-the-art ML-based approach SLAP, respectively-without compromising area efficiency.
Activations as Features: Probing LLMs for Generalizable Essay Scoring Representations
Dec 22, 2025Automated essay scoring (AES) is a challenging task in cross-prompt settings due to the diversity of scoring criteria. While previous studies have focused on the output of large language models (LLMs) to improve scoring accuracy, we believe activations from intermediate layers may also provide valuable information. To explore this possibility, we evaluated the discriminative power of LLMs' activations in cross-prompt essay scoring task. Specifically, we used activations to fit probes and further analyzed the effects of different models and input content of LLMs on this discriminative power. By computing the directions of essays across various trait dimensions under different prompts, we analyzed the variation in evaluation perspectives of large language models concerning essay types and traits. Results show that the activations possess strong discriminative power in evaluating essay quality and that LLMs can adapt their evaluation perspectives to different traits and essay types, effectively handling the diversity of scoring criteria in cross-prompt settings.
DynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025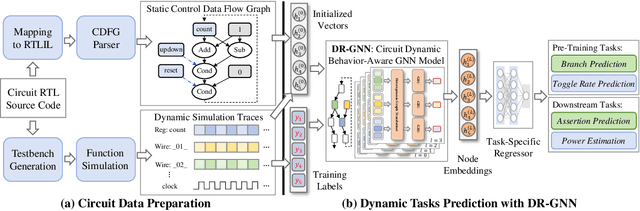

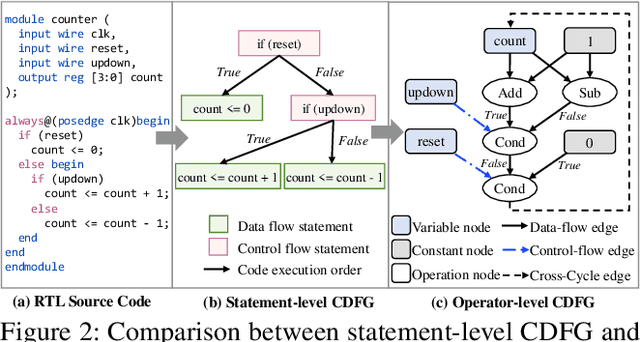

There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.
Concept-SAE: Active Causal Probing of Visual Model Behavior
Sep 26, 2025Standard Sparse Autoencoders (SAEs) excel at discovering a dictionary of a model's learned features, offering a powerful observational lens. However, the ambiguous and ungrounded nature of these features makes them unreliable instruments for the active, causal probing of model behavior. To solve this, we introduce Concept-SAE, a framework that forges semantically grounded concept tokens through a novel hybrid disentanglement strategy. We first quantitatively demonstrate that our dual-supervision approach produces tokens that are remarkably faithful and spatially localized, outperforming alternative methods in disentanglement. This validated fidelity enables two critical applications: (1) we probe the causal link between internal concepts and predictions via direct intervention, and (2) we probe the model's failure modes by systematically localizing adversarial vulnerabilities to specific layers. Concept-SAE provides a validated blueprint for moving beyond correlational interpretation to the mechanistic, causal probing of model behavior.