 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
Evolution of Optimization Algorithms for Global Placement via Large Language Models
Apr 18, 2025Optimization algorithms are widely employed to tackle complex problems, but designing them manually is often labor-intensive and requires significant expertise. Global placement is a fundamental step in electronic design automation (EDA). While analytical approaches represent the state-of-the-art (SOTA) in global placement, their core optimization algorithms remain heavily dependent on heuristics and customized components, such as initialization strategies, preconditioning methods, and line search techniques. This paper presents an automated framework that leverages large language models (LLM) to evolve optimization algorithms for global placement. We first generate diverse candidate algorithms using LLM through carefully crafted prompts. Then we introduce an LLM-based genetic flow to evolve selected candidate algorithms. The discovered optimization algorithms exhibit substantial performance improvements across many benchmarks. Specifically, Our design-case-specific discovered algorithms achieve average HPWL improvements of \textbf{5.05\%}, \text{5.29\%} and \textbf{8.30\%} on MMS, ISPD2005 and ISPD2019 benchmarks, and up to \textbf{17\%} improvements on individual cases. Additionally, the discovered algorithms demonstrate good generalization ability and are complementary to existing parameter-tuning methods.
AnalogXpert: Automating Analog Topology Synthesis by Incorporating Circuit Design Expertise into Large Language Models
Dec 17, 2024Analog circuits are crucial in modern electronic systems, and automating their design has attracted significant research interest. One of major challenges is topology synthesis, which determines circuit components and their connections. Recent studies explore large language models (LLM) for topology synthesis. However, the scenarios addressed by these studies do not align well with practical applications. Specifically, existing work uses vague design requirements as input and outputs an ideal model, but detailed structural requirements and device-level models are more practical. Moreover, current approaches either formulate topology synthesis as graph generation or Python code generation, whereas practical topology design is a complex process that demands extensive design knowledge. In this work, we propose AnalogXpert, a LLM-based agent aiming at solving practical topology synthesis problem by incorporating circuit design expertise into LLMs. First, we represent analog topology as SPICE code and introduce a subcircuit library to reduce the design space, in the same manner as experienced designers. Second, we decompose the problem into two sub-task (i.e., block selection and block connection) through the use of CoT and incontext learning techniques, to mimic the practical design process. Third, we introduce a proofreading strategy that allows LLMs to incrementally correct the errors in the initial design, akin to human designers who iteratively check and adjust the initial topology design to ensure accuracy. Finally, we construct a high-quality benchmark containing both real data (30) and synthetic data (2k). AnalogXpert achieves 40% and 23% success rates on the synthetic dataset and real dataset respectively, which is markedly better than those of GPT-4o (3% on both the synthetic dataset and the real dataset).
EasyACIM: An End-to-End Automated Analog CIM with Synthesizable Architecture and Agile Design Space Exploration
Apr 12, 2024Analog Computing-in-Memory (ACIM) is an emerging architecture to perform efficient AI edge computing. However, current ACIM designs usually have unscalable topology and still heavily rely on manual efforts. These drawbacks limit the ACIM application scenarios and lead to an undesired time-to-market. This work proposes an end-to-end automated ACIM based on a synthesizable architecture (EasyACIM). With a given array size and customized cell library, EasyACIM can generate layouts for ACIMs with various design specifications end-to-end automatically. Leveraging the multi-objective genetic algorithm (MOGA)-based design space explorer, EasyACIM can obtain high-quality ACIM solutions based on the proposed synthesizable architecture, targeting versatile application scenarios. The ACIM solutions given by EasyACIM have a wide design space and competitive performance compared to the state-of-the-art (SOTA) ACIMs.
PDNNet: PDN-Aware GNN-CNN Heterogeneous Network for Dynamic IR Drop Prediction
Mar 27, 2024
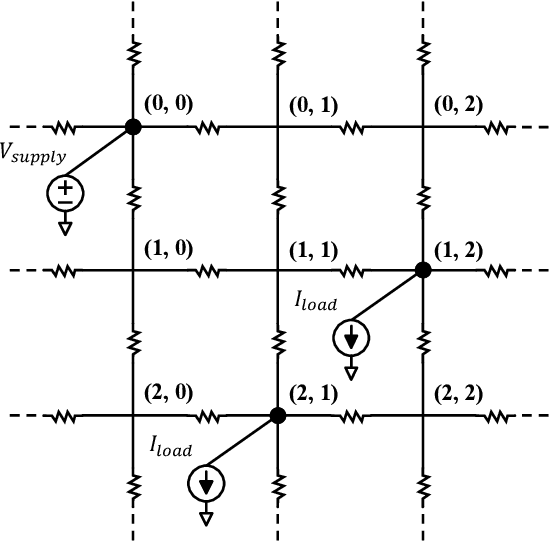
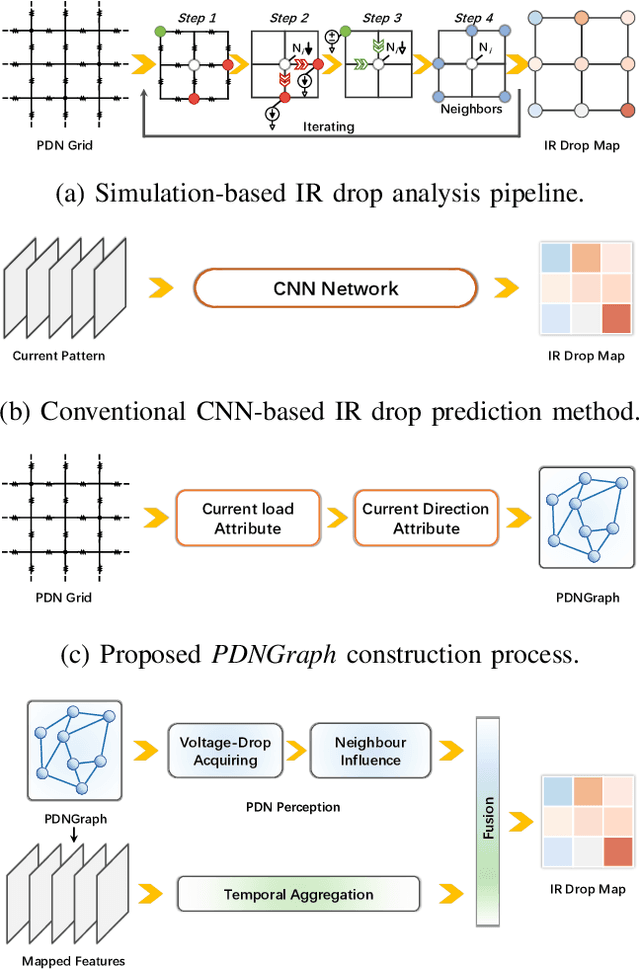
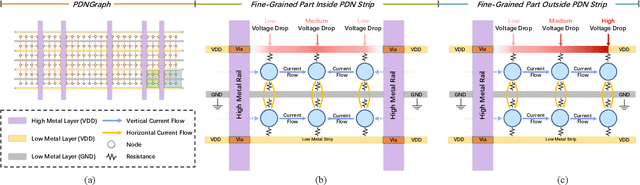
IR drop on the power delivery network (PDN) is closely related to PDN's configuration and cell current consumption. As the integrated circuit (IC) design is growing larger, dynamic IR drop simulation becomes computationally unaffordable and machine learning based IR drop prediction has been explored as a promising solution. Although CNN-based methods have been adapted to IR drop prediction task in several works, the shortcomings of overlooking PDN configuration is non-negligible. In this paper, we consider not only how to properly represent cell-PDN relation, but also how to model IR drop following its physical nature in the feature aggregation procedure. Thus, we propose a novel graph structure, PDNGraph, to unify the representations of the PDN structure and the fine-grained cell-PDN relation. We further propose a dual-branch heterogeneous network, PDNNet, incorporating two parallel GNN-CNN branches to favorably capture the above features during the learning process. Several key designs are presented to make the dynamic IR drop prediction highly effective and interpretable. We are the first work to apply graph structure to deep-learning based dynamic IR drop prediction method. Experiments show that PDNNet outperforms the state-of-the-art CNN-based methods by up to 39.3% reduction in prediction error and achieves 545x speedup compared to the commercial tool, which demonstrates the superiority of our method.
Imbalanced Large Graph Learning Framework for FPGA Logic Elements Packing Prediction
Aug 07, 2023Packing is a required step in a typical FPGA CAD flow. It has high impacts to the performance of FPGA placement and routing. Early prediction of packing results can guide design optimization and expedite design closure. In this work, we propose an imbalanced large graph learning framework, ImLG, for prediction of whether logic elements will be packed after placement. Specifically, we propose dedicated feature extraction and feature aggregation methods to enhance the node representation learning of circuit graphs. With imbalanced distribution of packed and unpacked logic elements, we further propose techniques such as graph oversampling and mini-batch training for this imbalanced learning task in large circuit graphs. Experimental results demonstrate that our framework can improve the F1 score by 42.82% compared to the most recent Gaussian-based prediction method. Physical design results show that the proposed method can assist the placer in improving routed wirelength by 0.93% and SLICE occupation by 0.89%.
HybridNet: Dual-Branch Fusion of Geometrical and Topological Views for VLSI Congestion Prediction
May 07, 2023Accurate early congestion prediction can prevent unpleasant surprises at the routing stage, playing a crucial character in assisting designers to iterate faster in VLSI design cycles. In this paper, we introduce a novel strategy to fully incorporate topological and geometrical features of circuits by making several key designs in our network architecture. To be more specific, we construct two individual graphs (geometry-graph, topology-graph) with distinct edge construction schemes according to their unique properties. We then propose a dual-branch network with different encoder layers in each pathway and aggregate representations with a sophisticated fusion strategy. Our network, named HybridNet, not only provides a simple yet effective way to capture the geometric interactions of cells, but also preserves the original topological relationships in the netlist. Experimental results on the ISPD2015 benchmarks show that we achieve an improvement of 10.9% compared to previous methods.
CircuitNet: An Open-Source Dataset for Machine Learning Applications in Electronic Design Automation
Aug 04, 2022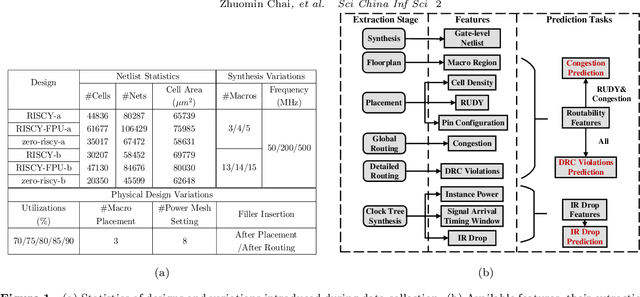
The electronic design automation (EDA) community has been actively exploring machine learning for very-large-scale-integrated computer aided design (VLSI CAD). Many studies have explored learning based techniques for cross-stage prediction tasks in the design flow to achieve faster design convergence. Although building machine learning (ML) models usually requires a large amount of data, most studies can only generate small internal datasets for validation due to the lack of large public datasets. In this essay, we present the first open-source dataset for machine learning tasks in VLSI CAD called CircuitNet. The dataset consists of more than 10K samples extracted from versatile runs of commercial design tools based on 6 open-source RISC-V designs.
LHNN: Lattice Hypergraph Neural Network for VLSI Congestion Prediction
Mar 24, 2022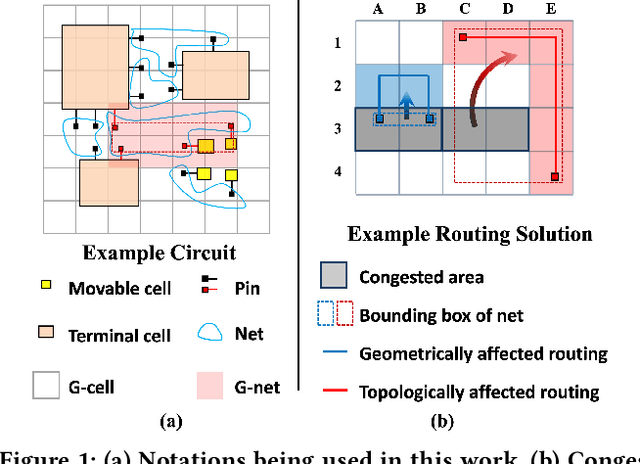
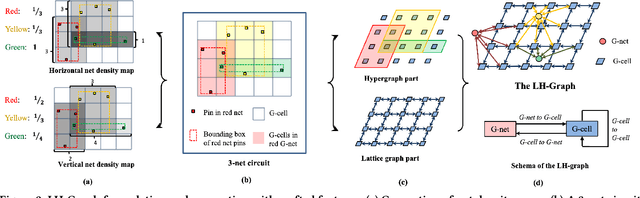
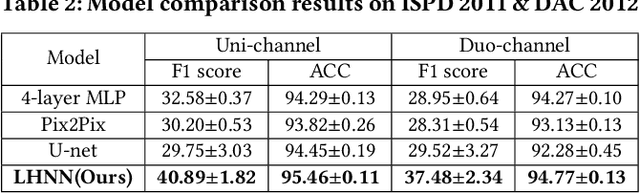
Precise congestion prediction from a placement solution plays a crucial role in circuit placement. This work proposes the lattice hypergraph (LH-graph), a novel graph formulation for circuits, which preserves netlist data during the whole learning process, and enables the congestion information propagated geometrically and topologically. Based on the formulation, we further developed a heterogeneous graph neural network architecture LHNN, jointing the routing demand regression to support the congestion spot classification. LHNN constantly achieves more than 35% improvements compared with U-nets and Pix2Pix on the F1 score. We expect our work shall highlight essential procedures using machine learning for congestion prediction.
Towards Machine Learning for Placement and Routing in Chip Design: a Methodological Overview
Feb 28, 2022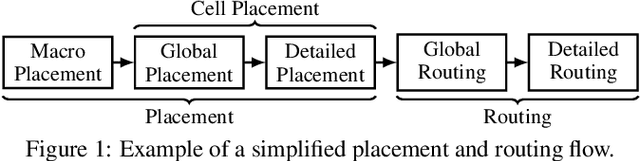
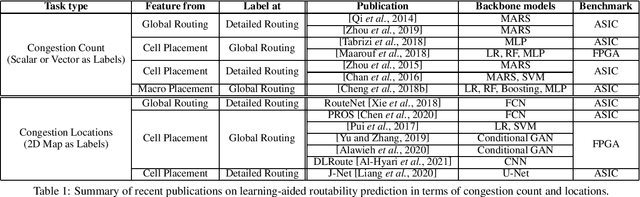
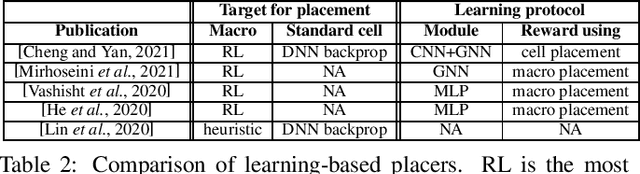
Placement and routing are two indispensable and challenging (NP-hard) tasks in modern chip design flows. Compared with traditional solvers using heuristics or expert-well-designed algorithms, machine learning has shown promising prospects by its data-driven nature, which can be of less reliance on knowledge and priors, and potentially more scalable by its advanced computational paradigms (e.g. deep networks with GPU acceleration). This survey starts with the introduction of basics of placement and routing, with a brief description on classic learning-free solvers. Then we present detailed review on recent advance in machine learning for placement and routing. Finally we discuss the challenges and opportunities for future research.