 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Sink Forges Native MoE in Attention Layers: Sink-Aware Training to Address Head Collapse
Feb 01, 2026Large Language Models (LLMs) often assign disproportionate attention to the first token, a phenomenon known as the attention sink. Several recent approaches aim to address this issue, including Sink Attention in GPT-OSS and Gated Attention in Qwen3-Next. However, a comprehensive analysis of the relationship among these attention mechanisms is lacking. In this work, we provide both theoretical and empirical evidence demonstrating that the sink in Vanilla Attention and Sink Attention naturally construct a Mixture-of-Experts (MoE) mechanism within attention layers. This insight explains the head collapse phenomenon observed in prior work, where only a fixed subset of attention heads contributes to generation. To mitigate head collapse, we propose a sink-aware training algorithm with an auxiliary load balancing loss designed for attention layers. Extensive experiments show that our method achieves effective head load balancing and improves model performance across Vanilla Attention, Sink Attention, and Gated Attention. We hope this study offers a new perspective on attention mechanisms and encourages further exploration of the inherent MoE structure within attention layers.
ReactEMG Stroke: Healthy-to-Stroke Few-shot Adaptation for sEMG-Based Intent Detection
Jan 29, 2026Surface electromyography (sEMG) is a promising control signal for assist-as-needed hand rehabilitation after stroke, but detecting intent from paretic muscles often requires lengthy, subject-specific calibration and remains brittle to variability. We propose a healthy-to-stroke adaptation pipeline that initializes an intent detector from a model pretrained on large-scale able-bodied sEMG, then fine-tunes it for each stroke participant using only a small amount of subject-specific data. Using a newly collected dataset from three individuals with chronic stroke, we compare adaptation strategies (head-only tuning, parameter-efficient LoRA adapters, and full end-to-end fine-tuning) and evaluate on held-out test sets that include realistic distribution shifts such as within-session drift, posture changes, and armband repositioning. Across conditions, healthy-pretrained adaptation consistently improves stroke intent detection relative to both zero-shot transfer and stroke-only training under the same data budget; the best adaptation methods improve average transition accuracy from 0.42 to 0.61 and raw accuracy from 0.69 to 0.78. These results suggest that transferring a reusable healthy-domain EMG representation can reduce calibration burden while improving robustness for real-time post-stroke intent detection.
AIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM
Nov 06, 2025



SRAM Processing-in-Memory (PIM) has emerged as the most promising implementation for high-performance PIM, delivering superior computing density, energy efficiency, and computational precision. However, the pursuit of higher performance necessitates more complex circuit designs and increased operating frequencies, which exacerbate IR-drop issues. Severe IR-drop can significantly degrade chip performance and even threaten reliability. Conventional circuit-level IR-drop mitigation methods, such as back-end optimizations, are resource-intensive and often compromise power, performance, and area (PPA). To address these challenges, we propose AIM, comprehensive software and hardware co-design for architecture-level IR-drop mitigation in high-performance PIM. Initially, leveraging the bit-serial and in-situ dataflow processing properties of PIM, we introduce Rtog and HR, which establish a direct correlation between PIM workloads and IR-drop. Building on this foundation, we propose LHR and WDS, enabling extensive exploration of architecture-level IR-drop mitigation while maintaining computational accuracy through software optimization. Subsequently, we develop IR-Booster, a dynamic adjustment mechanism that integrates software-level HR information with hardware-based IR-drop monitoring to adapt the V-f pairs of the PIM macro, achieving enhanced energy efficiency and performance. Finally, we propose the HR-aware task mapping method, bridging software and hardware designs to achieve optimal improvement. Post-layout simulation results on a 7nm 256-TOPS PIM chip demonstrate that AIM achieves up to 69.2% IR-drop mitigation, resulting in 2.29x energy efficiency improvement and 1.152x speedup.
ReactEMG: Zero-Shot, Low-Latency Intent Detection via sEMG
Jun 24, 2025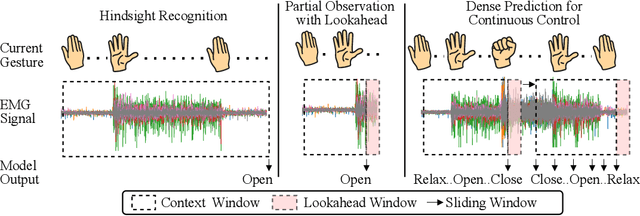
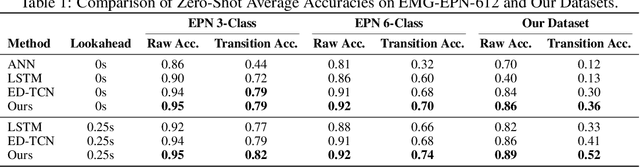
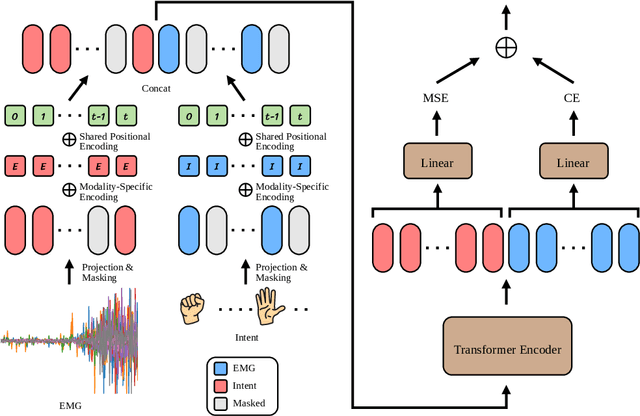
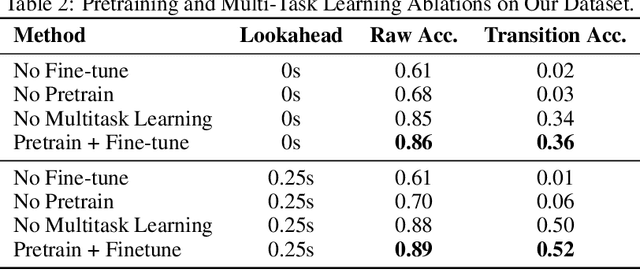
Surface electromyography (sEMG) signals show promise for effective human-computer interfaces, particularly in rehabilitation and prosthetics. However, challenges remain in developing systems that respond quickly and reliably to user intent, across different subjects and without requiring time-consuming calibration. In this work, we propose a framework for EMG-based intent detection that addresses these challenges. Unlike traditional gesture recognition models that wait until a gesture is completed before classifying it, our approach uses a segmentation strategy to assign intent labels at every timestep as the gesture unfolds. We introduce a novel masked modeling strategy that aligns muscle activations with their corresponding user intents, enabling rapid onset detection and stable tracking of ongoing gestures. In evaluations against baseline methods, considering both accuracy and stability for device control, our approach surpasses state-of-the-art performance in zero-shot transfer conditions, demonstrating its potential for wearable robotics and next-generation prosthetic systems. Our project page is available at: https://reactemg.github.io
HybriMoE: Hybrid CPU-GPU Scheduling and Cache Management for Efficient MoE Inference
Apr 08, 2025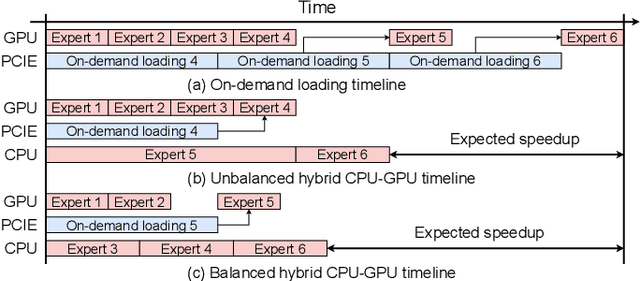
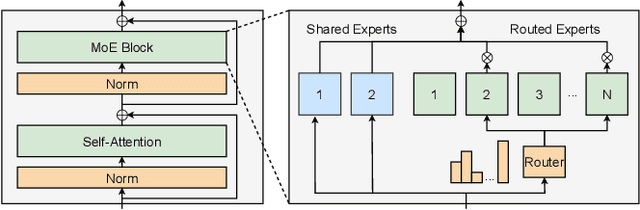
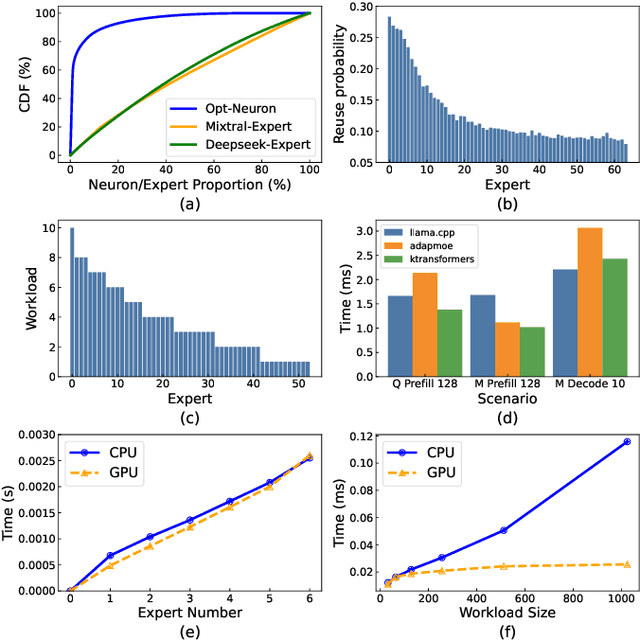
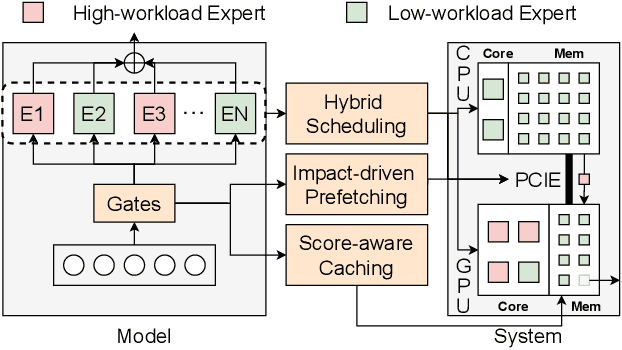
The Mixture of Experts (MoE) architecture has demonstrated significant advantages as it enables to increase the model capacity without a proportional increase in computation. However, the large MoE model size still introduces substantial memory demands, which usually requires expert offloading on resource-constrained platforms and incurs significant overhead. Hybrid CPU-GPU inference has been proposed to leverage CPU computation to reduce expert loading overhead but faces major challenges: on one hand, the expert activation patterns of MoE models are highly unstable, rendering the fixed mapping strategies in existing works inefficient; on the other hand, the hybrid CPU-GPU schedule for MoE is inherently complex due to the diverse expert sizes, structures, uneven workload distribution, etc. To address these challenges, in this paper, we propose HybriMoE, a hybrid CPU-GPU inference framework that improves resource utilization through a novel CPU-GPU scheduling and cache management system. HybriMoE introduces (i) a dynamic intra-layer scheduling strategy to balance workloads across CPU and GPU, (ii) an impact-driven inter-layer prefetching algorithm, and (iii) a score-based caching algorithm to mitigate expert activation instability. We implement HybriMoE on top of the kTransformers framework and evaluate it on three widely used MoE-based LLMs. Experimental results demonstrate that HybriMoE achieves an average speedup of 1.33$\times$ in the prefill stage and 1.70$\times$ in the decode stage compared to state-of-the-art hybrid MoE inference framework. Our code is available at: https://github.com/PKU-SEC-Lab/HybriMoE.
LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-design
Feb 21, 2025State space models (SSMs) like Mamba have recently attracted much attention. Compared to Transformer-based large language models (LLMs), Mamba achieves linear computation complexity with the sequence length and demonstrates superior performance. However, Mamba is hard to accelerate due to the scattered activation outliers and the complex computation dependency, rendering existing LLM accelerators inefficient. In this paper, we propose LightMamba that co-designs the quantization algorithm and FPGA accelerator architecture for efficient Mamba inference. We first propose an FPGA-friendly post-training quantization algorithm that features rotation-assisted quantization and power-of-two SSM quantization to reduce the majority of computation to 4-bit. We further design an FPGA accelerator that partially unrolls the Mamba computation to balance the efficiency and hardware costs. Through computation reordering as well as fine-grained tiling and fusion, the hardware utilization and memory efficiency of the accelerator get drastically improved. We implement LightMamba on Xilinx Versal VCK190 FPGA and achieve 4.65x to 6.06x higher energy efficiency over the GPU baseline. When evaluated on Alveo U280 FPGA, LightMamba reaches 93 tokens/s, which is 1.43x that of the GPU baseline.
AnalogXpert: Automating Analog Topology Synthesis by Incorporating Circuit Design Expertise into Large Language Models
Dec 17, 2024Analog circuits are crucial in modern electronic systems, and automating their design has attracted significant research interest. One of major challenges is topology synthesis, which determines circuit components and their connections. Recent studies explore large language models (LLM) for topology synthesis. However, the scenarios addressed by these studies do not align well with practical applications. Specifically, existing work uses vague design requirements as input and outputs an ideal model, but detailed structural requirements and device-level models are more practical. Moreover, current approaches either formulate topology synthesis as graph generation or Python code generation, whereas practical topology design is a complex process that demands extensive design knowledge. In this work, we propose AnalogXpert, a LLM-based agent aiming at solving practical topology synthesis problem by incorporating circuit design expertise into LLMs. First, we represent analog topology as SPICE code and introduce a subcircuit library to reduce the design space, in the same manner as experienced designers. Second, we decompose the problem into two sub-task (i.e., block selection and block connection) through the use of CoT and incontext learning techniques, to mimic the practical design process. Third, we introduce a proofreading strategy that allows LLMs to incrementally correct the errors in the initial design, akin to human designers who iteratively check and adjust the initial topology design to ensure accuracy. Finally, we construct a high-quality benchmark containing both real data (30) and synthetic data (2k). AnalogXpert achieves 40% and 23% success rates on the synthetic dataset and real dataset respectively, which is markedly better than those of GPT-4o (3% on both the synthetic dataset and the real dataset).
MCUBERT: Memory-Efficient BERT Inference on Commodity Microcontrollers
Oct 23, 2024



In this paper, we propose MCUBERT to enable language models like BERT on tiny microcontroller units (MCUs) through network and scheduling co-optimization. We observe the embedding table contributes to the major storage bottleneck for tiny BERT models. Hence, at the network level, we propose an MCU-aware two-stage neural architecture search algorithm based on clustered low-rank approximation for embedding compression. To reduce the inference memory requirements, we further propose a novel fine-grained MCU-friendly scheduling strategy. Through careful computation tiling and re-ordering as well as kernel design, we drastically increase the input sequence lengths supported on MCUs without any latency or accuracy penalty. MCUBERT reduces the parameter size of BERT-tiny and BERT-mini by 5.7$\times$ and 3.0$\times$ and the execution memory by 3.5$\times$ and 4.3$\times$, respectively. MCUBERT also achieves 1.5$\times$ latency reduction. For the first time, MCUBERT enables lightweight BERT models on commodity MCUs and processing more than 512 tokens with less than 256KB of memory.
PrivQuant: Communication-Efficient Private Inference with Quantized Network/Protocol Co-Optimization
Oct 12, 2024Private deep neural network (DNN) inference based on secure two-party computation (2PC) enables secure privacy protection for both the server and the client. However, existing secure 2PC frameworks suffer from a high inference latency due to enormous communication. As the communication of both linear and non-linear DNN layers reduces with the bit widths of weight and activation, in this paper, we propose PrivQuant, a framework that jointly optimizes the 2PC-based quantized inference protocols and the network quantization algorithm, enabling communication-efficient private inference. PrivQuant proposes DNN architecture-aware optimizations for the 2PC protocols for communication-intensive quantized operators and conducts graph-level operator fusion for communication reduction. Moreover, PrivQuant also develops a communication-aware mixed precision quantization algorithm to improve inference efficiency while maintaining high accuracy. The network/protocol co-optimization enables PrivQuant to outperform prior-art 2PC frameworks. With extensive experiments, we demonstrate PrivQuant reduces communication by $11\times, 2.5\times \mathrm{and}~ 2.8\times$, which results in $8.7\times, 1.8\times ~ \mathrm{and}~ 2.4\times$ latency reduction compared with SiRNN, COINN, and CoPriv, respectively.
AdapMoE: Adaptive Sensitivity-based Expert Gating and Management for Efficient MoE Inference
Aug 19, 2024
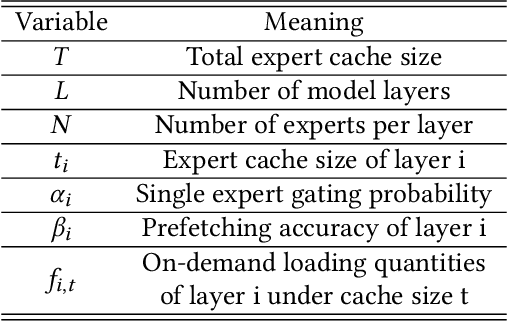
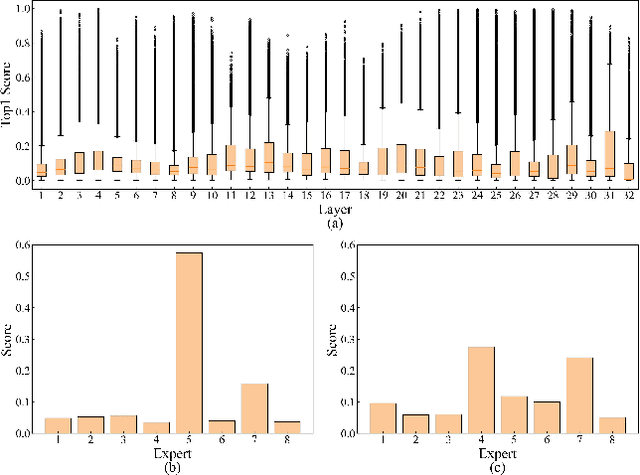
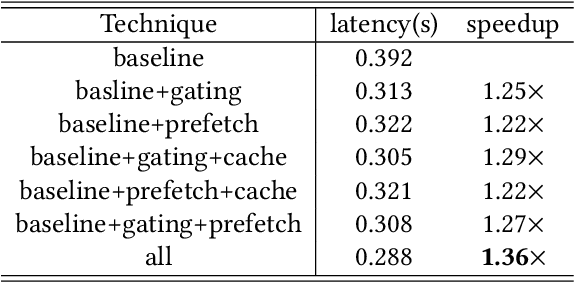
Mixture-of-Experts (MoE) models are designed to enhance the efficiency of large language models (LLMs) without proportionally increasing the computational demands. However, their deployment on edge devices still faces significant challenges due to high on-demand loading overheads from managing sparsely activated experts. This paper introduces AdapMoE, an algorithm-system co-design framework for efficient MoE inference. AdapMoE features adaptive expert gating and management to reduce the on-demand loading overheads. We observe the heterogeneity of experts loading across layers and tokens, based on which we propose a sensitivity-based strategy to adjust the number of activated experts dynamically. Meanwhile, we also integrate advanced prefetching and cache management techniques to further reduce the loading latency. Through comprehensive evaluations on various platforms, we demonstrate AdapMoE consistently outperforms existing techniques, reducing the average number of activated experts by 25% and achieving a 1.35x speedup without accuracy degradation. Code is available at: https://github.com/PKU-SEC-Lab/AdapMoE.