 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPQVAR: Floating Point Quantization for Visual Autoregressive Model with FPGA Hardware Co-design
May 22, 2025Visual autoregressive (VAR) modeling has marked a paradigm shift in image generation from next-token prediction to next-scale prediction. VAR predicts a set of tokens at each step from coarse to fine scale, leading to better image quality and faster inference speed compared to existing diffusion models. However, the large parameter size and computation cost hinder its deployment on edge devices. To reduce the memory and computation cost, we propose FPQVAR, an efficient post-training floating-point (FP) quantization framework for VAR featuring algorithm and hardware co-design. At the algorithm level, we first identify the challenges of quantizing VAR. To address them, we propose Dual Format Quantization for the highly imbalanced input activation. We further propose Group-wise Hadamard Transformation and GHT-Aware Learnable Transformation to address the time-varying outlier channels. At the hardware level, we design the first low-bit FP quantizer and multiplier with lookup tables on FPGA and propose the first FPGA-based VAR accelerator featuring low-bit FP computation and an elaborate two-level pipeline. Extensive experiments show that compared to the state-of-the-art quantization method, our proposed FPQVAR significantly improves Fr\'echet Inception Distance (FID) from 10.83 to 3.58, Inception Score (IS) from 175.9 to 241.5 under 4-bit quantization. FPQVAR also significantly improves the performance of 6-bit quantized VAR, bringing it on par with the FP16 model. Our accelerator on AMD-Xilinx VCK190 FPGA achieves a throughput of 1.1 image/s, which is 3.1x higher than the integer-based accelerator. It also demonstrates 3.6x and 2.8x higher energy efficiency compared to the integer-based accelerator and GPU baseline, respectively.
LightMamba: Efficient Mamba Acceleration on FPGA with Quantization and Hardware Co-design
Feb 21, 2025State space models (SSMs) like Mamba have recently attracted much attention. Compared to Transformer-based large language models (LLMs), Mamba achieves linear computation complexity with the sequence length and demonstrates superior performance. However, Mamba is hard to accelerate due to the scattered activation outliers and the complex computation dependency, rendering existing LLM accelerators inefficient. In this paper, we propose LightMamba that co-designs the quantization algorithm and FPGA accelerator architecture for efficient Mamba inference. We first propose an FPGA-friendly post-training quantization algorithm that features rotation-assisted quantization and power-of-two SSM quantization to reduce the majority of computation to 4-bit. We further design an FPGA accelerator that partially unrolls the Mamba computation to balance the efficiency and hardware costs. Through computation reordering as well as fine-grained tiling and fusion, the hardware utilization and memory efficiency of the accelerator get drastically improved. We implement LightMamba on Xilinx Versal VCK190 FPGA and achieve 4.65x to 6.06x higher energy efficiency over the GPU baseline. When evaluated on Alveo U280 FPGA, LightMamba reaches 93 tokens/s, which is 1.43x that of the GPU baseline.
HG-PIPE: Vision Transformer Acceleration with Hybrid-Grained Pipeline
Jul 25, 2024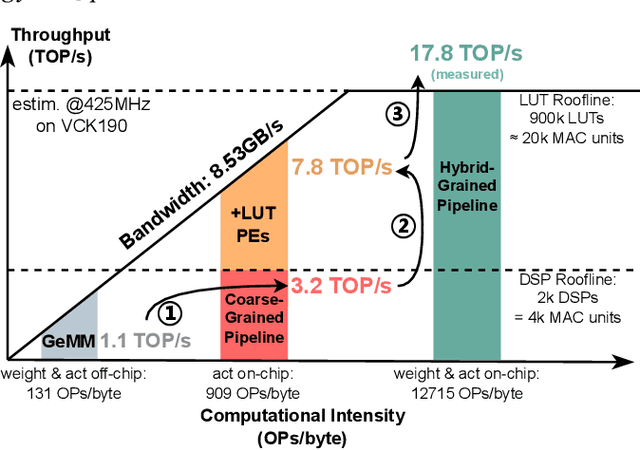
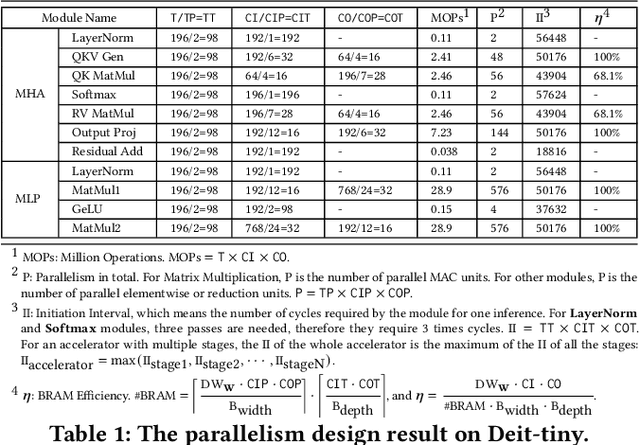
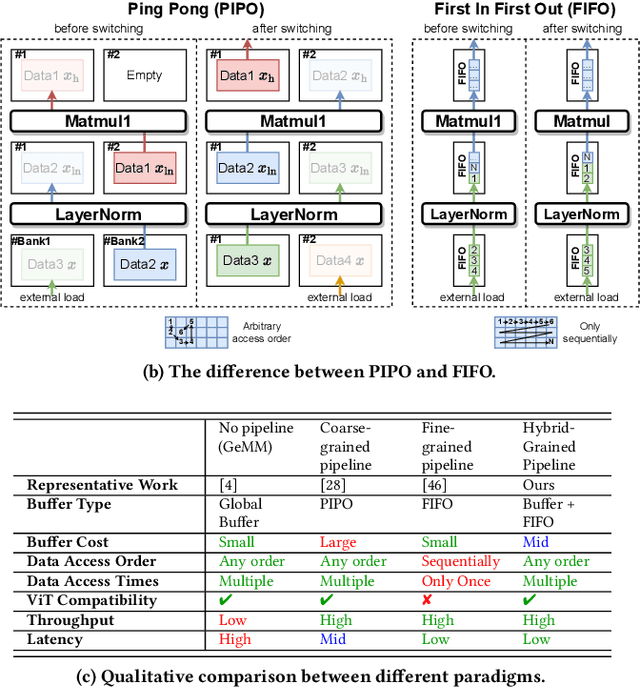
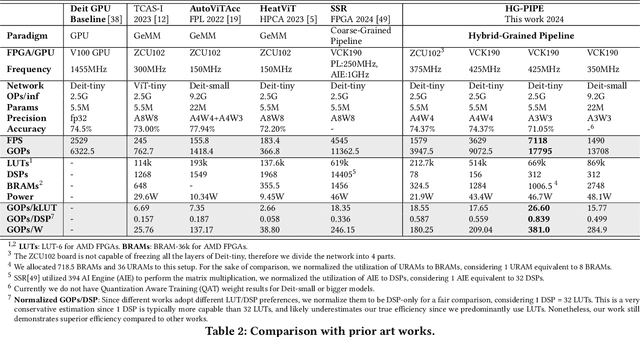
Vision Transformer (ViT) acceleration with field programmable gate array (FPGA) is promising but challenging. Existing FPGA-based ViT accelerators mainly rely on temporal architectures, which process different operators by reusing the same hardware blocks and suffer from extensive memory access overhead. Pipelined architectures, either coarse-grained or fine-grained, unroll the ViT computation spatially for memory access efficiency. However, they usually suffer from significant hardware resource constraints and pipeline bubbles induced by the global computation dependency of ViT. In this paper, we introduce HG-PIPE, a pipelined FPGA accelerator for high-throughput and low-latency ViT processing. HG-PIPE features a hybrid-grained pipeline architecture to reduce on-chip buffer cost and couples the computation dataflow and parallelism design to eliminate the pipeline bubbles. HG-PIPE further introduces careful approximations to implement both linear and non-linear operators with abundant Lookup Tables (LUTs), thus alleviating resource constraints. On a ZCU102 FPGA, HG-PIPE achieves 2.78 times better throughput and 2.52 times better resource efficiency than the prior-art accelerators, e.g., AutoViTAcc. With a VCK190 FPGA, HG-PIPE realizes end-to-end ViT acceleration on a single device and achieves 7118 images/s, which is 2.81 times faster than a V100 GPU.
Integer-Only Neural Network Quantization Scheme Based on Shift-Batch-Normalization
May 28, 2021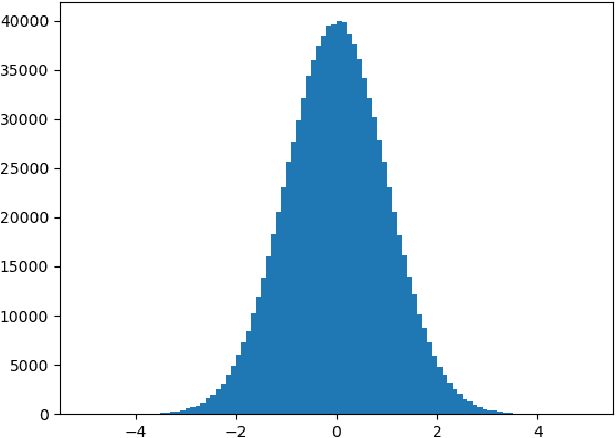
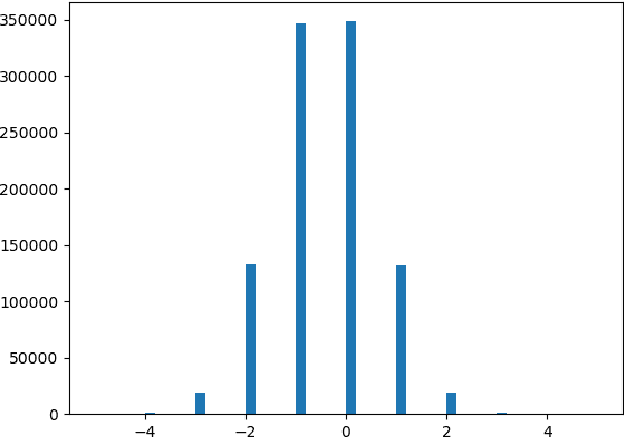
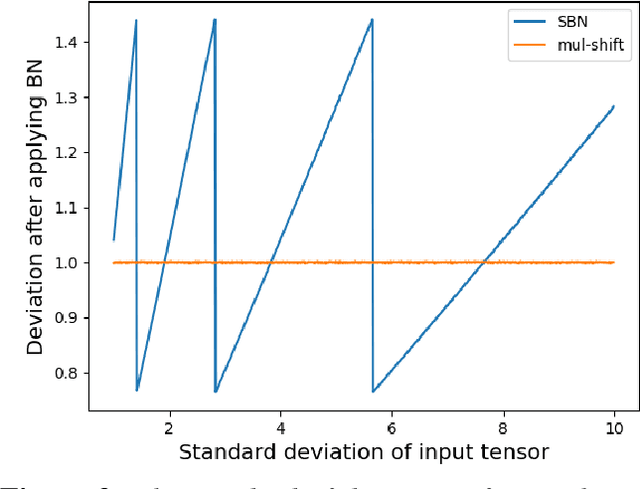
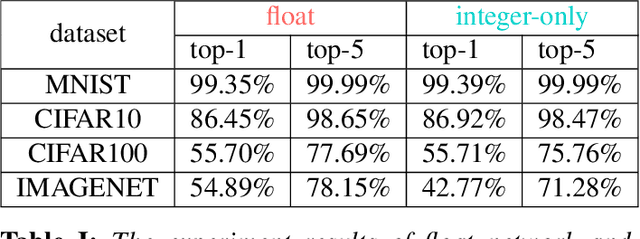
Neural networks are very popular in many areas, but great computing complexity makes it hard to run neural networks on devices with limited resources. To address this problem, quantization methods are used to reduce model size and computation cost, making it possible to use neural networks on embedded platforms or mobile devices. In this paper, an integer-only-quantization scheme is introduced. This scheme uses one layer that combines shift-based batch normalization and uniform quantization to implement 4-bit integer-only inference. Without big integer multiplication(which is used in previous integer-only-quantization methods), this scheme can achieve good power and latency efficiency, and is especially suitable to be deployed on co-designed hardware platforms. Tests have proved that this scheme works very well for easy tasks. And for tough tasks, performance loss can be tolerated for its inference efficiency. Our work is available on github: https://github.com/hguq/IntegerNet.
Contextual User Browsing Bandits for Large-Scale Online Mobile Recommendation
Aug 21, 2020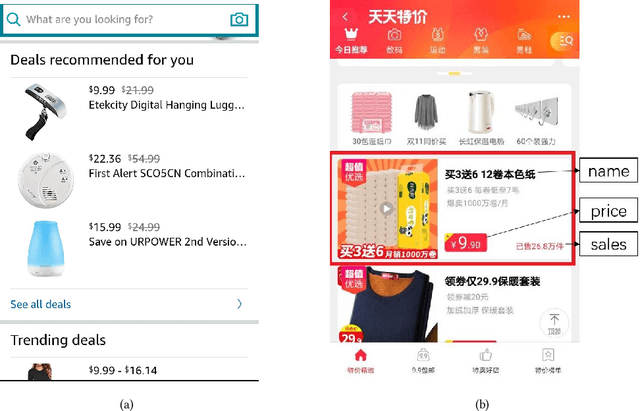
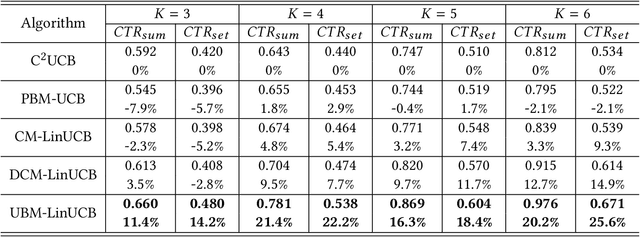
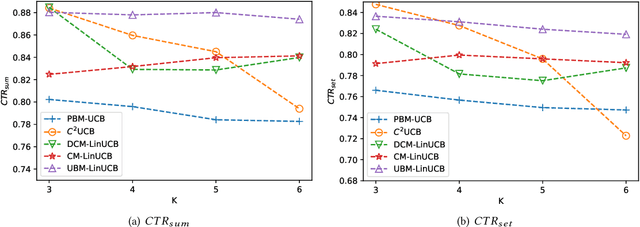
Online recommendation services recommend multiple commodities to users. Nowadays, a considerable proportion of users visit e-commerce platforms by mobile devices. Due to the limited screen size of mobile devices, positions of items have a significant influence on clicks: 1) Higher positions lead to more clicks for one commodity. 2) The 'pseudo-exposure' issue: Only a few recommended items are shown at first glance and users need to slide the screen to browse other items. Therefore, some recommended items ranked behind are not viewed by users and it is not proper to treat this kind of items as negative samples. While many works model the online recommendation as contextual bandit problems, they rarely take the influence of positions into consideration and thus the estimation of the reward function may be biased. In this paper, we aim at addressing these two issues to improve the performance of online mobile recommendation. Our contributions are four-fold. First, since we concern the reward of a set of recommended items, we model the online recommendation as a contextual combinatorial bandit problem and define the reward of a recommended set. Second, we propose a novel contextual combinatorial bandit method called UBM-LinUCB to address two issues related to positions by adopting the User Browsing Model (UBM), a click model for web search. Third, we provide a formal regret analysis and prove that our algorithm achieves sublinear regret independent of the number of items. Finally, we evaluate our algorithm on two real-world datasets by a novel unbiased estimator. An online experiment is also implemented in Taobao, one of the most popular e-commerce platforms in the world. Results on two CTR metrics show that our algorithm outperforms the other contextual bandit algorithms.
A Survey on Knowledge Graph-Based Recommender Systems
Feb 28, 2020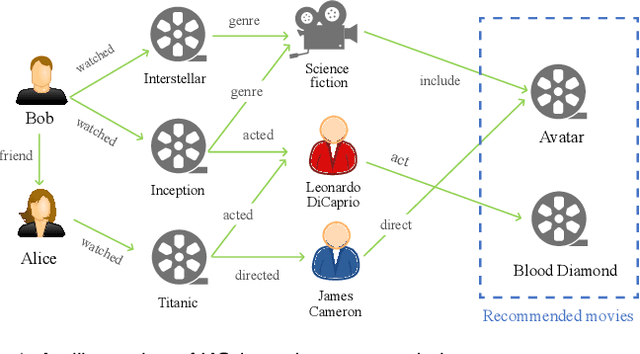
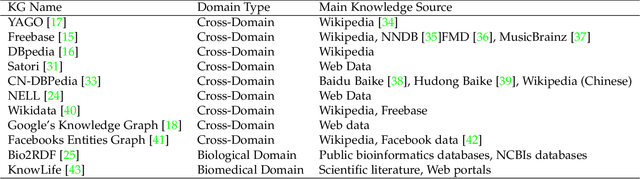

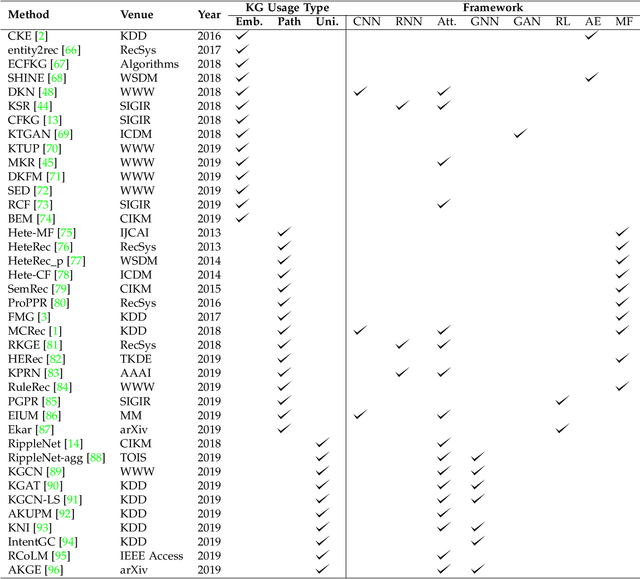
To solve the information explosion problem and enhance user experience in various online applications, recommender systems have been developed to model users preferences. Although numerous efforts have been made toward more personalized recommendations, recommender systems still suffer from several challenges, such as data sparsity and cold start. In recent years, generating recommendations with the knowledge graph as side information has attracted considerable interest. Such an approach can not only alleviate the abovementioned issues for a more accurate recommendation, but also provide explanations for recommended items. In this paper, we conduct a systematical survey of knowledge graph-based recommender systems. We collect recently published papers in this field and summarize them from two perspectives. On the one hand, we investigate the proposed algorithms by focusing on how the papers utilize the knowledge graph for accurate and explainable recommendation. On the other hand, we introduce datasets used in these works. Finally, we propose several potential research directions in this field.
Manipulating a Learning Defender and Ways to Counteract
May 28, 2019
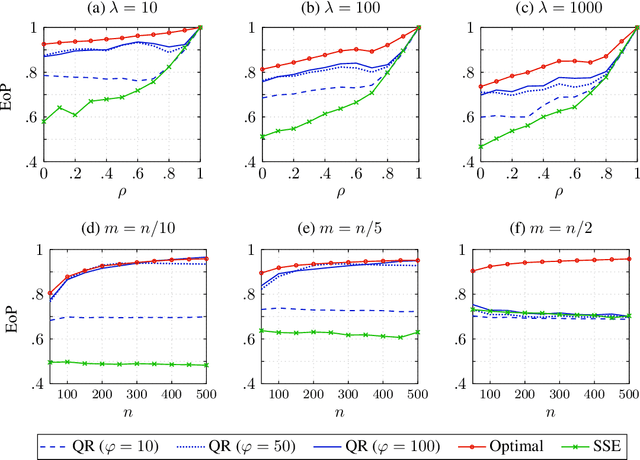
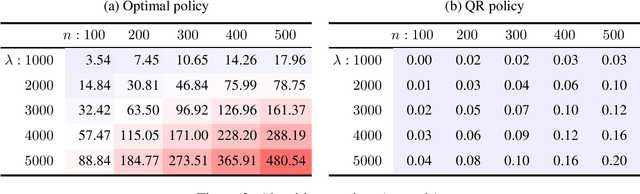
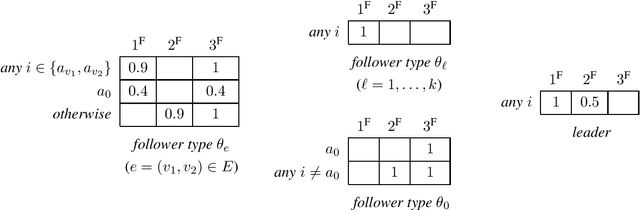
In Stackelberg security games, information about the attacker's type (i.e., payoff parameters) are essential for computing the optimal strategy for the defender to commit to. While such information can be incomplete or uncertain in practice, algorithms have been proposed to learn the optimal defender commitment from the attacker's best responses during the defender's interaction with the follower. In this paper, we show that, however, such algorithms might be easily manipulated by a strategic attacker, who intentionally sends fake best responses to mislead the learning algorithm into producing a strategy that benefits the attacker but, very likely, hurts the defender. As a key finding in this paper, attacker manipulation normally leads to the defender playing only her maximin strategy, which effectively renders the learning algorithm useless as to compute the maximin strategy requires no information about the other player at all. To address this issue, we propose a game-theoretic framework at a higher level, in which the defender commits to a policy that allows her to specify a particular strategy to play conditioned on the learned attacker type. We then provide a polynomial-time algorithm to compute the optimal defender policy, and in addition, a heuristic approach that applies even when the attacker type space is infinite or completely unknown. It is shown through simulations that our approaches can improve in the defender's utility significantly as compared to the situation when attacker manipulations are ignored.
Multi-Scale Quasi-RNN for Next Item Recommendation
Feb 26, 2019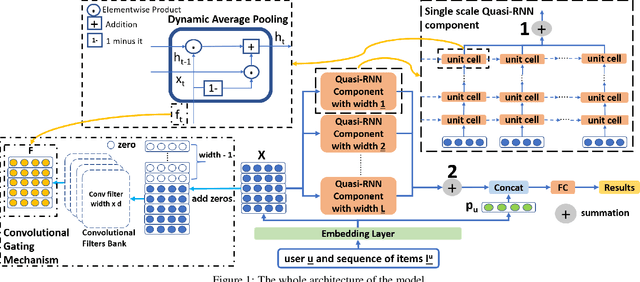
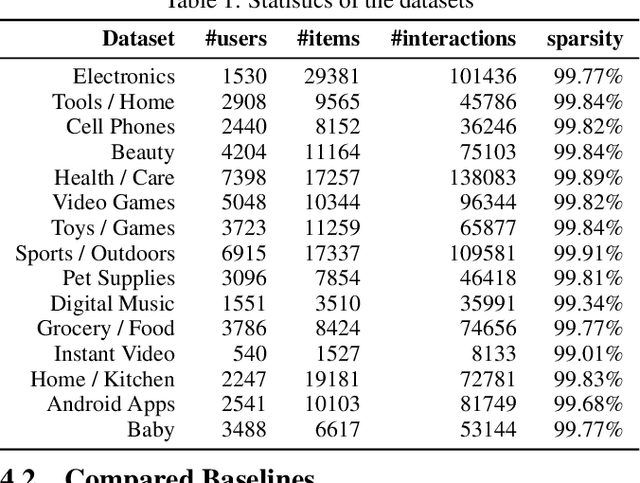
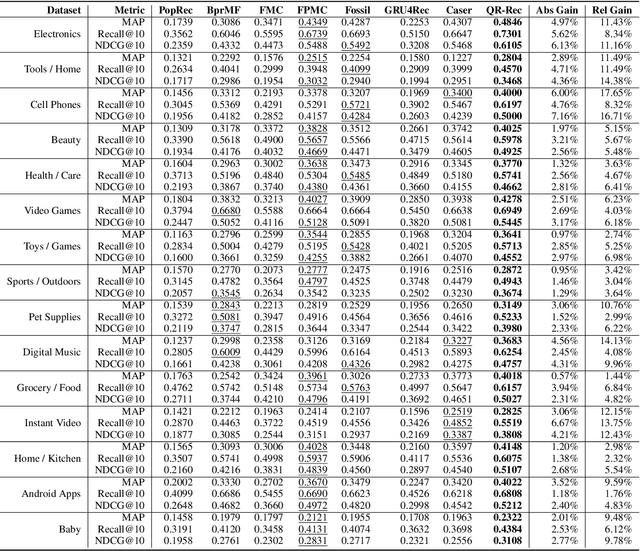
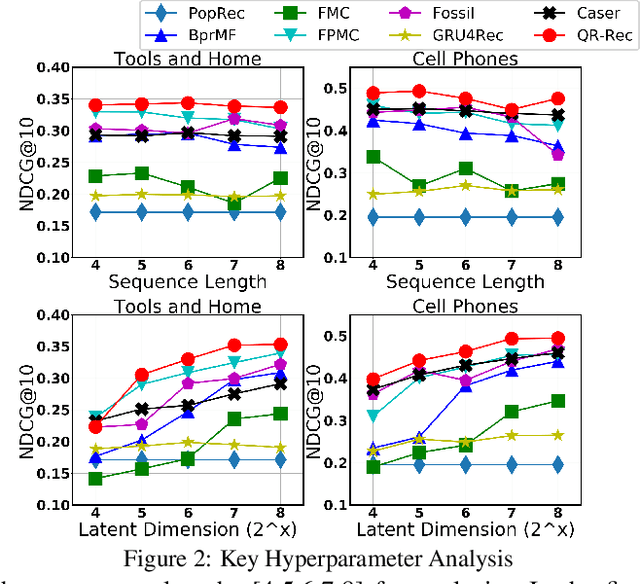
How to better utilize sequential information has been extensively studied in the setting of recommender systems. To this end, architectural inductive biases such as Markov-Chains, Recurrent models, Convolutional networks and many others have demonstrated reasonable success on this task. This paper proposes a new neural architecture, multi-scale Quasi-RNN for next item Recommendation (QR-Rec) task. Our model provides the best of both worlds by exploiting multi-scale convolutional features as the compositional gating functions of a recurrent cell. The model is implemented in a multi-scale fashion, i.e., convolutional filters of various widths are implemented to capture different union-level features of input sequences which influence the compositional encoder. The key idea aims to capture the recurrent relations between different kinds of local features, which has never been studied previously in the context of recommendation. Through extensive experiments, we demonstrate that our model achieves state-of-the-art performance on 15 well-established datasets, outperforming strong competitors such as FPMC, Fossil and Caser absolutely by 0.57%-7.16% and relatively by 1.44%-17.65% in terms of MAP, Recall@10 and NDCG@10.