 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collaborate in Multi-Module Recommendation via Multi-Agent Reinforcement Learning without Communication
Aug 29, 2020
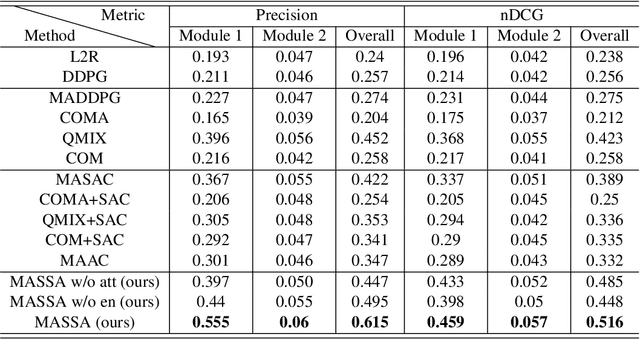
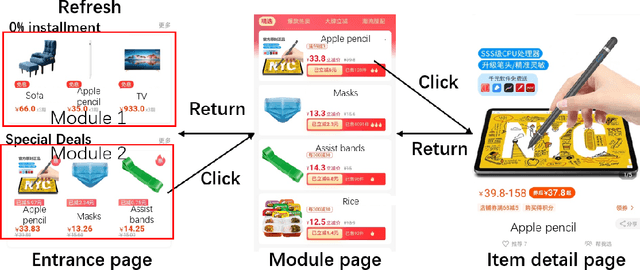
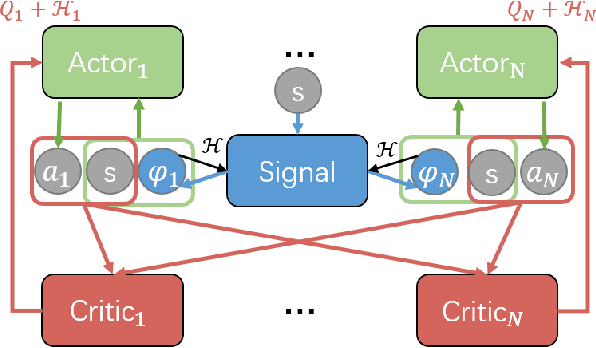
With the rise of online e-commerce platforms, more and more customers prefer to shop online. To sell more products, online platforms introduce various modules to recommend items with different properties such as huge discounts. A web page often consists of different independent modules. The ranking policies of these modules are decided by different teams and optimized individually without cooperation, which might result in competition between modules. Thus, the global policy of the whole page could be sub-optimal. In this paper, we propose a novel multi-agent cooperative reinforcement learning approach with the restriction that different modules cannot communicate. Our contributions are three-fold. Firstly, inspired by a solution concept in game theory named correlated equilibrium, we design a signal network to promote cooperation of all modules by generating signals (vectors) for different modules. Secondly, an entropy-regularized version of the signal network is proposed to coordinate agents' exploration of the optimal global policy. Furthermore, experiments based on real-world e-commerce data demonstrate that our algorithm obtains superior performance over baselines.
Contextual User Browsing Bandits for Large-Scale Online Mobile Recommendation
Aug 21, 2020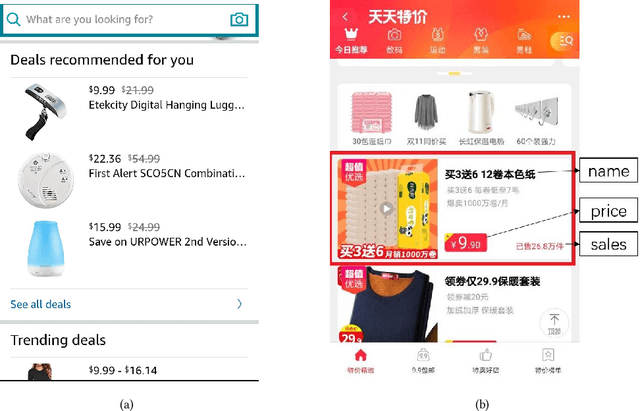
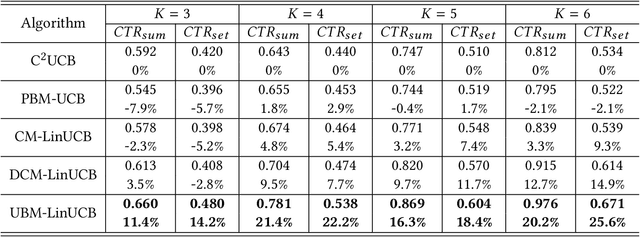
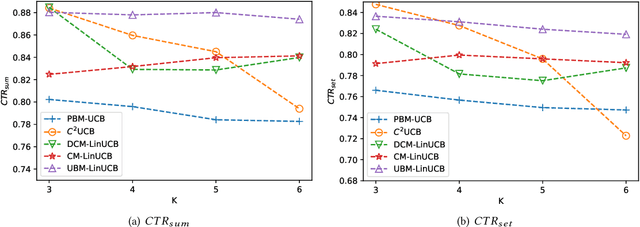
Online recommendation services recommend multiple commodities to users. Nowadays, a considerable proportion of users visit e-commerce platforms by mobile devices. Due to the limited screen size of mobile devices, positions of items have a significant influence on clicks: 1) Higher positions lead to more clicks for one commodity. 2) The 'pseudo-exposure' issue: Only a few recommended items are shown at first glance and users need to slide the screen to browse other items. Therefore, some recommended items ranked behind are not viewed by users and it is not proper to treat this kind of items as negative samples. While many works model the online recommendation as contextual bandit problems, they rarely take the influence of positions into consideration and thus the estimation of the reward function may be biased. In this paper, we aim at addressing these two issues to improve the performance of online mobile recommendation. Our contributions are four-fold. First, since we concern the reward of a set of recommended items, we model the online recommendation as a contextual combinatorial bandit problem and define the reward of a recommended set. Second, we propose a novel contextual combinatorial bandit method called UBM-LinUCB to address two issues related to positions by adopting the User Browsing Model (UBM), a click model for web search. Third, we provide a formal regret analysis and prove that our algorithm achieves sublinear regret independent of the number of items. Finally, we evaluate our algorithm on two real-world datasets by a novel unbiased estimator. An online experiment is also implemented in Taobao, one of the most popular e-commerce platforms in the world. Results on two CTR metrics show that our algorithm outperforms the other contextual bandit algorithms.
Single-Layer Graph Convolutional Networks For Recommendation
Jun 07, 2020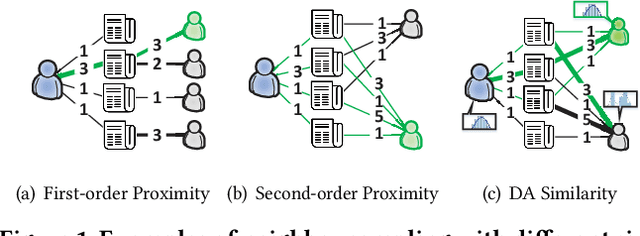
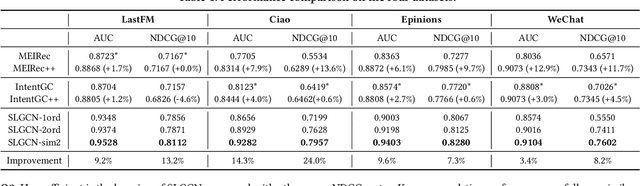
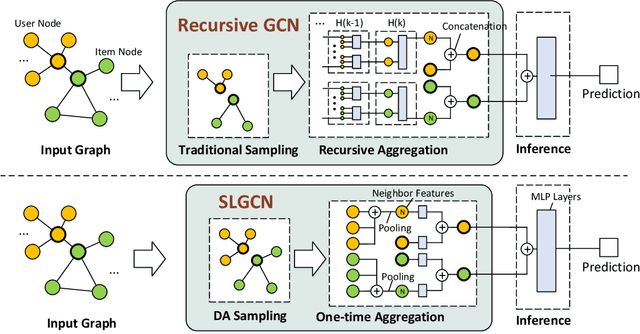
Graph Convolutional Networks (GCNs) and their variants have received significant attention and achieved start-of-the-art performances on various recommendation tasks. However, many existing GCN models tend to perform recursive aggregations among all related nodes, which arises severe computational burden. Moreover, they favor multi-layer architectures in conjunction with complicated modeling techniques. Though effective, the excessive amount of model parameters largely hinder their applications in real-world recommender systems. To this end, in this paper, we propose the single-layer GCN model which is able to achieve superior performance along with remarkably less complexity compared with existing models. Our main contribution is three-fold. First, we propose a principled similarity metric named distribution-aware similarity (DA similarity), which can guide the neighbor sampling process and evaluate the quality of the input graph explicitly. We also prove that DA similarity has a positive correlation with the final performance, through both theoretical analysis and empirical simulations. Second, we propose a simplified GCN architecture which employs a single GCN layer to aggregate information from the neighbors filtered by DA similarity and then generates the node representations. Moreover, the aggregation step is a parameter-free operation, such that it can be done in a pre-processing manner to further reduce red the training and inference costs. Third, we conduct extensive experiments on four datasets. The results verify that the proposed model outperforms existing GCN models considerably and yields up to a few orders of magnitude speedup in training, in terms of the recommendation performance.
Contextual-Bandit Based Personalized Recommendation with Time-Varying User Interests
Feb 29, 2020
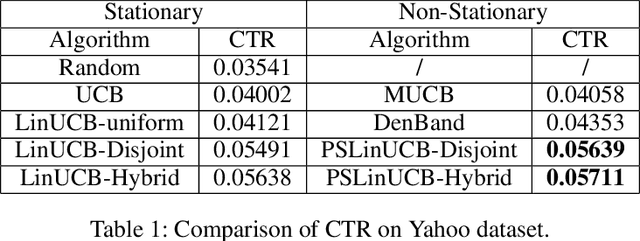
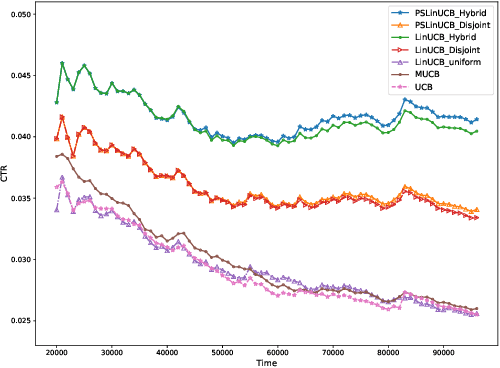
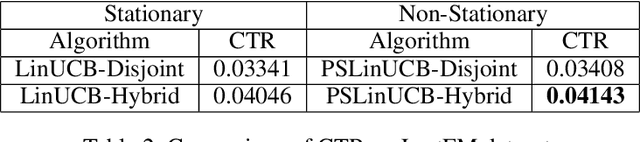
A contextual bandit problem is studied in a highly non-stationary environment, which is ubiquitous in various recommender systems due to the time-varying interests of users. Two models with disjoint and hybrid payoffs are considered to characterize the phenomenon that users' preferences towards different items vary differently over time. In the disjoint payoff model, the reward of playing an arm is determined by an arm-specific preference vector, which is piecewise-stationary with asynchronous and distinct changes across different arms. An efficient learning algorithm that is adaptive to abrupt reward changes is proposed and theoretical regret analysis is provided to show that a sublinear scaling of regret in the time length $T$ is achieved. The algorithm is further extended to a more general setting with hybrid payoffs where the reward of playing an arm is determined by both an arm-specific preference vector and a joint coefficient vector shared by all arms. Empirical experiments are conducted on real-world datasets to verify the advantages of the proposed learning algorithms against baseline ones in both settings.