 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
Mar 16, 2026Recent advancements extend Multimodal Large Language Models (MLLMs) beyond standard visual question answering to utilizing external tools for advanced visual tasks. Despite this progress, precisely executing and effectively composing diverse tools for complex tasks remain persistent bottleneck. Constrained by sparse tool-sets and simple tool-use trajectories, existing benchmarks fail to capture complex and diverse tool interactions, falling short in evaluating model performance under practical, real-world conditions. To bridge this gap, we introduce VisualToolChain-Bench~(VTC-Bench), a comprehensive benchmark designed to evaluate tool-use proficiency in MLLMs. To align with realistic computer vision pipelines, our framework features 32 diverse OpenCV-based visual operations. This rich tool-set enables extensive combinations, allowing VTC-Bench to rigorously assess multi-tool composition and long-horizon, multi-step plan execution. For precise evaluation, we provide 680 curated problems structured across a nine-category cognitive hierarchy, each with ground-truth execution trajectories. Extensive experiments on 19 leading MLLMs reveal critical limitations in current models' visual agentic capabilities. Specifically, models struggle to adapt to diverse tool-sets and generalize to unseen operations, with the leading model Gemini-3.0-Pro only achieving 51\% on our benchmark. Furthermore, multi-tool composition remains a persistent challenge. When facing complex tasks, models struggle to formulate efficient execution plans, relying heavily on a narrow, suboptimal subset of familiar functions rather than selecting the optimal tools. By identifying these fundamental challenges, VTC-Bench establishes a rigorous baseline to guide the development of more generalized visual agentic models.
QCAgent: An agentic framework for quality-controllable pathology report generation from whole slide image
Mar 02, 2026Recent methods for pathology report generation from whole-slide image (WSI) are capable of producing slide-level diagnostic descriptions but fail to ground fine-grained statements in localized visual evidence. Furthermore, they lack control over which diagnostic details to include and how to verify them. Inspired by emerging agentic analysis paradigms and the diagnostic workflow of pathologists,who selectively examine multiple fields of view, we propose QCAgent, an agentic framework for quality-controllable WSI report generation. The core innovations of this framework are as follows: (i) it incorporates a customized critique mechanism guided by a user-defined checklist specifying required diagnostic details and constraints; (ii) it re-identifies informative regions in the WSI based on the critique feedback and text-patch semantic retrieval, a process that iteratively enriches and reconciles the report. Experiments demonstrate that by making report requirements explicitly prompt-defined, constraint-aware, and verifiable through evidence-grounded refinement, QCAgent enables controllable generation of clinically meaningful and high-coverage pathology reports from WSI.
MLLM-CL: Continual Learning for Multimodal Large Language Models
Jun 05, 2025



Recent Multimodal Large Language Models (MLLMs) excel in vision-language understanding but face challenges in adapting to dynamic real-world scenarios that require continuous integration of new knowledge and skills. While continual learning (CL) offers a potential solution, existing benchmarks and methods suffer from critical limitations. In this paper, we introduce MLLM-CL, a novel benchmark encompassing domain and ability continual learning, where the former focuses on independently and identically distributed (IID) evaluation across evolving mainstream domains, whereas the latter evaluates on non-IID scenarios with emerging model ability. Methodologically, we propose preventing catastrophic interference through parameter isolation, along with an MLLM-based routing mechanism. Extensive experiments demonstrate that our approach can integrate domain-specific knowledge and functional abilities with minimal forgetting, significantly outperforming existing methods.
Synapse: Leveraging Few-Shot Exemplars for Human-Level Computer Control
Jun 13, 2023



This paper investigates the design of few-shot exemplars for computer automation through prompting large language models (LLMs). While previous prompting approaches focus on self-correction, we find that well-structured exemplars alone are sufficient for human-level performance. We present Synapse, an in-context computer control agent demonstrating human-level performance on the MiniWob++ benchmark. Synapse consists of three main components: 1) state-conditional decomposition, which divides demonstrations into exemplar sets based on the agent's need for new environment states, enabling temporal abstraction; 2) structured prompting, which filters states and reformulates task descriptions for each set to improve planning correctness; and 3) exemplar retrieval, which associates incoming tasks with corresponding exemplars in an exemplar database for multi-task adaptation and generalization. Synapse overcomes context length limits, reduces errors in multi-step control, and allows for more exemplars within the context. Importantly, Synapse complements existing prompting approaches that enhance LLMs' reasoning and planning abilities. Synapse outperforms previous methods, including behavioral cloning, reinforcement learning, finetuning, and prompting, with an average success rate of $98.5\%$ across 63 tasks in MiniWob++. Notably, Synapse relies on exemplars from only 47 tasks, demonstrating effective generalization to novel tasks. Our results highlight the potential of in-context learning to advance the integration of LLMs into practical tool automation.
Towards Effective and Interpretable Human-Agent Collaboration in MOBA Games: A Communication Perspective
Apr 23, 2023

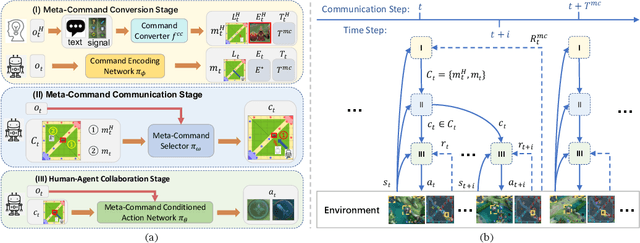

MOBA games, e.g., Dota2 and Honor of Kings, have been actively used as the testbed for the recent AI research on games, and various AI systems have been developed at the human level so far. However, these AI systems mainly focus on how to compete with humans, less on exploring how to collaborate with humans. To this end, this paper makes the first attempt to investigate human-agent collaboration in MOBA games. In this paper, we propose to enable humans and agents to collaborate through explicit communication by designing an efficient and interpretable Meta-Command Communication-based framework, dubbed MCC, for accomplishing effective human-agent collaboration in MOBA games. The MCC framework consists of two pivotal modules: 1) an interpretable communication protocol, i.e., the Meta-Command, to bridge the communication gap between humans and agents; 2) a meta-command value estimator, i.e., the Meta-Command Selector, to select a valuable meta-command for each agent to achieve effective human-agent collaboration. Experimental results in Honor of Kings demonstrate that MCC agents can collaborate reasonably well with human teammates and even generalize to collaborate with different levels and numbers of human teammates. Videos are available at https://sites.google.com/view/mcc-demo.
Towards Skilled Population Curriculum for Multi-Agent Reinforcement Learning
Feb 07, 2023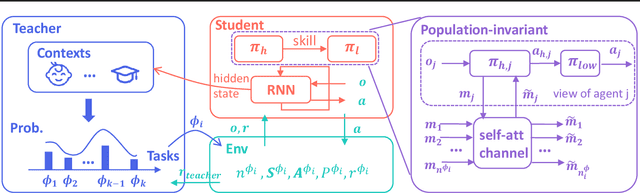


Recent advances in multi-agent reinforcement learning (MARL) allow agents to coordinate their behaviors in complex environments. However, common MARL algorithms still suffer from scalability and sparse reward issues. One promising approach to resolving them is automatic curriculum learning (ACL). ACL involves a student (curriculum learner) training on tasks of increasing difficulty controlled by a teacher (curriculum generator). Despite its success, ACL's applicability is limited by (1) the lack of a general student framework for dealing with the varying number of agents across tasks and the sparse reward problem, and (2) the non-stationarity of the teacher's task due to ever-changing student strategies. As a remedy for ACL, we introduce a novel automatic curriculum learning framework, Skilled Population Curriculum (SPC), which adapts curriculum learning to multi-agent coordination. Specifically, we endow the student with population-invariant communication and a hierarchical skill set, allowing it to learn cooperation and behavior skills from distinct tasks with varying numbers of agents. In addition, we model the teacher as a contextual bandit conditioned by student policies, enabling a team of agents to change its size while still retaining previously acquired skills. We also analyze the inherent non-stationarity of this multi-agent automatic curriculum teaching problem and provide a corresponding regret bound. Empirical results show that our method improves the performance, scalability and sample efficiency in several MARL environments.
Off-Beat Multi-Agent Reinforcement Learning
May 27, 2022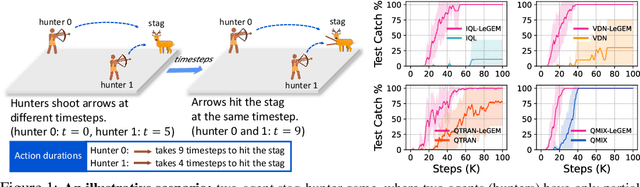
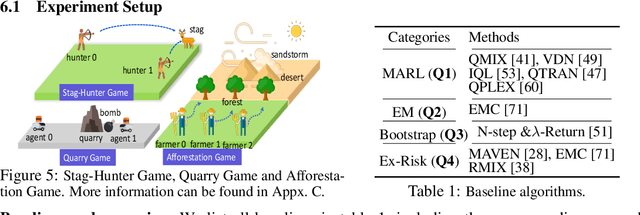

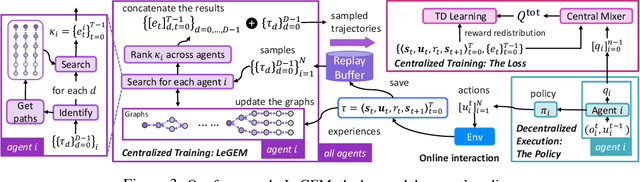
We investigate model-free multi-agent reinforcement learning (MARL) in environments where off-beat actions are prevalent, i.e., all actions have pre-set execution durations. During execution durations, the environment changes are influenced by, but not synchronised with, action execution. Such a setting is ubiquitous in many real-world problems. However, most MARL methods assume actions are executed immediately after inference, which is often unrealistic and can lead to catastrophic failure for multi-agent coordination with off-beat actions. In order to fill this gap, we develop an algorithmic framework for MARL with off-beat actions. We then propose a novel episodic memory, LeGEM, for model-free MARL algorithms. LeGEM builds agents' episodic memories by utilizing agents' individual experiences. It boosts multi-agent learning by addressing the challenging temporal credit assignment problem raised by the off-beat actions via our novel reward redistribution scheme, alleviating the issue of non-Markovian reward. We evaluate LeGEM on various multi-agent scenarios with off-beat actions, including Stag-Hunter Game, Quarry Game, Afforestation Game, and StarCraft II micromanagement tasks. Empirical results show that LeGEM significantly boosts multi-agent coordination and achieves leading performance and improved sample efficiency.
Attention over Self-attention:Intention-aware Re-ranking with Dynamic Transformer Encoders for Recommendation
Jan 14, 2022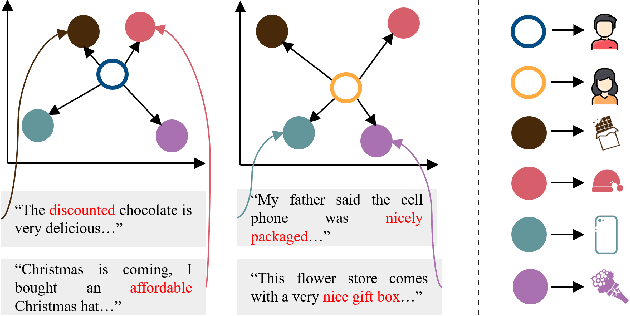
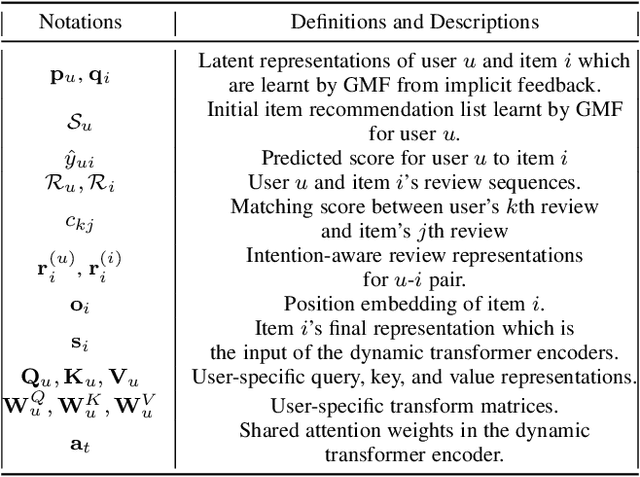
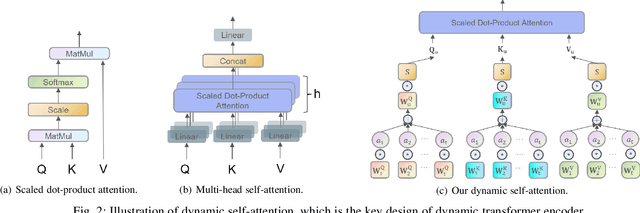
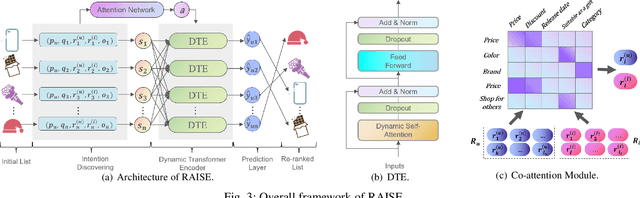
Re-ranking models refine the item recommendation list generated by the prior global ranking model with intra-item relationships. However, most existing re-ranking solutions refine recommendation list based on the implicit feedback with a shared re-ranking model, which regrettably ignore the intra-item relationships under diverse user intentions. In this paper, we propose a novel Intention-aware Re-ranking Model with Dynamic Transformer Encoder (RAISE), aiming to perform user-specific prediction for each target user based on her intentions. Specifically, we first propose to mine latent user intentions from text reviews with an intention discovering module (IDM). By differentiating the importance of review information with a co-attention network, the latent user intention can be explicitly modeled for each user-item pair. We then introduce a dynamic transformer encoder (DTE) to capture user-specific intra-item relationships among item candidates by seamlessly accommodating the learnt latent user intentions via IDM. As such, RAISE is able to perform user-specific prediction without increasing the depth (number of blocks) and width (number of heads) of the prediction model. Empirical study on four public datasets shows the superiority of our proposed RAISE, with up to 13.95%, 12.30%, and 13.03% relative improvements evaluated by Precision, MAP, and NDCG respectively.
DeepScalper: A Risk-Aware Deep Reinforcement Learning Framework for Intraday Trading with Micro-level Market Embedding
Dec 15, 2021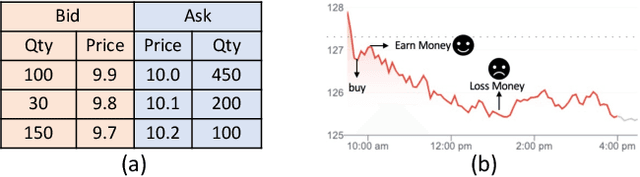
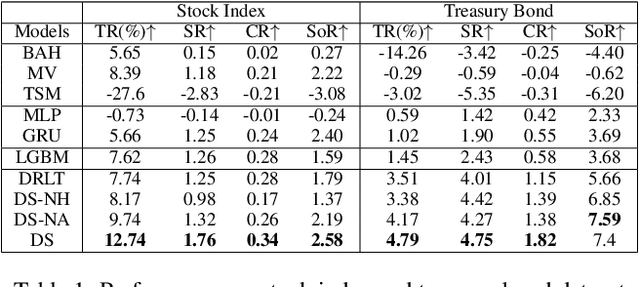
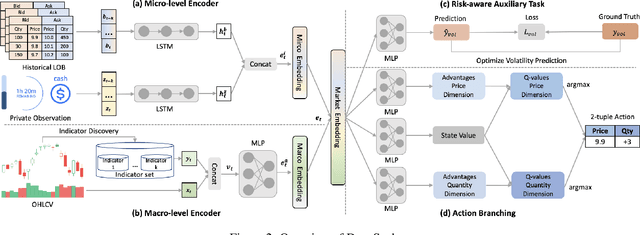
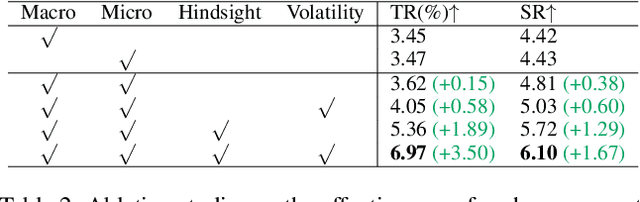
Reinforcement learning (RL) techniques have shown great success in quantitative investment tasks, such as portfolio management and algorithmic trading. Especially, intraday trading is one of the most profitable and risky tasks because of the intraday behaviors of the financial market that reflect billions of rapidly fluctuating values. However, it is hard to apply existing RL methods to intraday trading due to the following three limitations: 1) overlooking micro-level market information (e.g., limit order book); 2) only focusing on local price fluctuation and failing to capture the overall trend of the whole trading day; 3) neglecting the impact of market risk. To tackle these limitations, we propose DeepScalper, a deep reinforcement learning framework for intraday trading. Specifically, we adopt an encoder-decoder architecture to learn robust market embedding incorporating both macro-level and micro-level market information. Moreover, a novel hindsight reward function is designed to provide the agent a long-term horizon for capturing the overall price trend. In addition, we propose a risk-aware auxiliary task by predicting future volatility, which helps the agent take market risk into consideration while maximizing profit. Finally, extensive experiments on two stock index futures and four treasury bond futures demonstrate that DeepScalper achieves significant improvement against many state-of-the-art approaches.
Reinforcement Learning for Quantitative Trading
Sep 28, 2021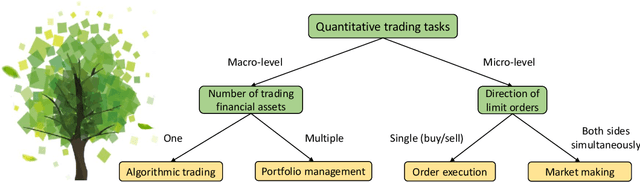
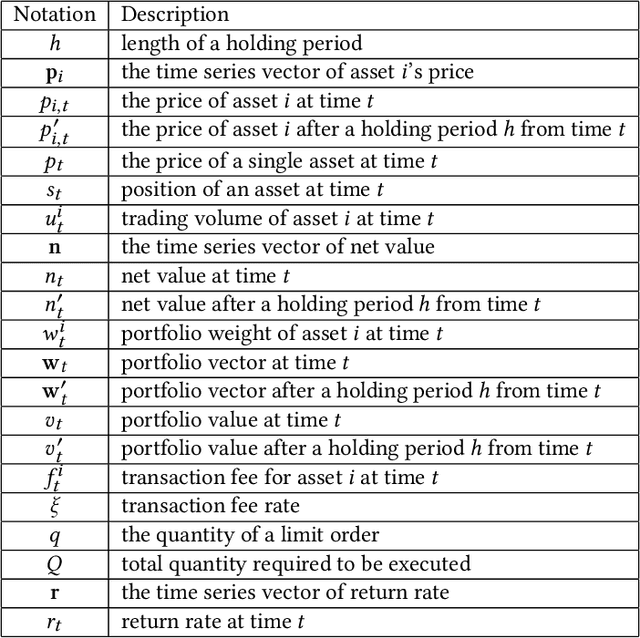
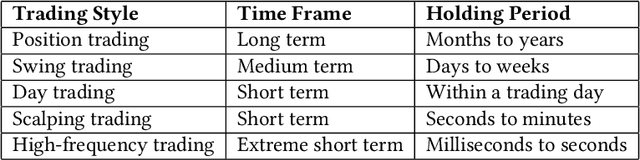
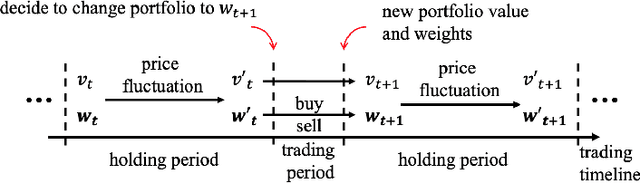
Quantitative trading (QT), which refers to the usage of mathematical models and data-driven techniques in analyzing the financial market, has been a popular topic in both academia and financial industry since 1970s. In the last decade, reinforcement learning (RL) has garnered significant interest in many domains such as robotics and video games, owing to its outstanding ability on solving complex sequential decision making problems. RL's impact is pervasive, recently demonstrating its ability to conquer many challenging QT tasks. It is a flourishing research direction to explore RL techniques' potential on QT tasks. This paper aims at providing a comprehensive survey of research efforts on RL-based methods for QT tasks. More concretely, we devise a taxonomy of RL-based QT models, along with a comprehensive summary of the state of the art. Finally, we discuss current challenges and propose future research directions in this exciting field.