 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-VISTA: Benchmarking Continual Learning in Video Large Language Models
Apr 01, 2026Video Large Language Models (Video-LLMs) require continual learning to adapt to non-stationary real-world data. However, existing benchmarks fall short of evaluating modern foundation models: many still rely on models without large-scale pre-training, and prevailing benchmarks typically partition a single dataset into sub-tasks, resulting in high task redundancy and negligible forgetting on pre-trained Video-LLMs. To address these limitations, we propose CL-VISTA, a benchmark tailored for continual video understanding of Video-LLMs. By curating 8 diverse tasks spanning perception, understanding, and reasoning, CL-VISTA induces substantial distribution shifts that effectively expose catastrophic forgetting. To systematically assess CL methods, we establish a comprehensive evaluation framework comprising 6 distinct protocols across 3 critical dimensions: performance, computational efficiency, and memory footprint. Notably, the performance dimension incorporates a general video understanding assessment to assess whether CL methods genuinely enhance foundational intelligence or merely induce task-specific overfitting. Extensive benchmarking of 10 mainstream CL methods reveals a fundamental trade-off: no single approach achieves universal superiority across all dimensions. Methods that successfully mitigate catastrophic forgetting tend to compromise generalization or incur prohibitive computational and memory overheads. We hope CL-VISTA provides critical insights for advancing continual learning in multimodal foundation models.
Scaling Laws for Educational AI Agents
Mar 12, 2026While scaling laws for Large Language Models (LLMs) have been extensively studied along dimensions of model parameters, training data, and compute, the scaling behavior of LLM-based educational agents remains unexplored. We propose that educational agent capability scales not merely with the underlying model size, but through structured dimensions that we collectively term the Agent Scaling Law: role definition clarity, skill depth, tool completeness, runtime capability, and educator expertise injection. Central to this framework is AgentProfile, a structured JSON-based specification that serves as the mechanism enabling systematic capability growth of educational agents. We present EduClaw, a profile-driven multi-agent platform that operationalizes this scaling law, demonstrating its effectiveness through the construction and deployment of 330+ educational agent profiles encompassing 1,100+ skill modules across K-12 subjects. Our empirical observations suggest that educational agent performance scales predictably with profile structural richness. We identify two complementary scaling axes -- Tool Scaling and Skill Scaling -- as future directions, arguing that the path to more capable educational AI lies not solely in larger models, but in stronger structured capability systems.
Automating Skill Acquisition through Large-Scale Mining of Open-Source Agentic Repositories: A Framework for Multi-Agent Procedural Knowledge Extraction
Mar 12, 2026The transition from monolithic large language models (LLMs) to modular, skill-equipped agents represents a fundamental architectural shift in artificial intelligence deployment. While general-purpose models demonstrate remarkable breadth in declarative knowledge, their utility in autonomous workflows is frequently constrained by insufficient specialized procedural expertise. This report investigates a systematic framework for automated acquisition of high-quality agent skills through mining of open-source repositories on platforms such as GitHub. We focus on the extraction of visualization and educational capabilities from state-of-the-art systems including TheoremExplainAgent and Code2Video, both utilizing the Manim mathematical animation engine. The framework encompasses repository structural analysis, semantic skill identification through dense retrieval, and translation to the standardized SKILL.md format. We demonstrate that systematic extraction from agentic repositories, combined with rigorous security governance and multi-dimensional evaluation metrics, enables scalable acquisition of procedural knowledge that augments LLM capabilities without requiring model retraining. Our analysis reveals that agent-generated educational content can achieve 40\% gains in knowledge transfer efficiency while maintaining pedagogical quality comparable to human-crafted tutorials.
Reward Prediction with Factorized World States
Mar 10, 2026Agents must infer action outcomes and select actions that maximize a reward signal indicating how close the goal is to being reached. Supervised learning of reward models could introduce biases inherent to training data, limiting generalization to novel goals and environments. In this paper, we investigate whether well-defined world state representations alone can enable accurate reward prediction across domains. To address this, we introduce StateFactory, a factorized representation method that transforms unstructured observations into a hierarchical object-attribute structure using language models. This structured representation allows rewards to be estimated naturally as the semantic similarity between the current state and the goal state under hierarchical constraint. Overall, the compact representation structure induced by StateFactory enables strong reward generalization capabilities. We evaluate on RewardPrediction, a new benchmark dataset spanning five diverse domains and comprising 2,454 unique action-observation trajectories with step-wise ground-truth rewards. Our method shows promising zero-shot results against both VLWM-critic and LLM-as-a-Judge reward models, achieving 60% and 8% lower EPIC distance, respectively. Furthermore, this superior reward quality successfully translates into improved agent planning performance, yielding success rate gains of +21.64% on AlfWorld and +12.40% on ScienceWorld over reactive system-1 policies and enhancing system-2 agent planning. Project Page: https://statefactory.github.io
Two-Stream Interactive Joint Learning of Scene Parsing and Geometric Vision Tasks
Feb 14, 2026Inspired by the human visual system, which operates on two parallel yet interactive streams for contextual and spatial understanding, this article presents Two Interactive Streams (TwInS), a novel bio-inspired joint learning framework capable of simultaneously performing scene parsing and geometric vision tasks. TwInS adopts a unified, general-purpose architecture in which multi-level contextual features from the scene parsing stream are infused into the geometric vision stream to guide its iterative refinement. In the reverse direction, decoded geometric features are projected into the contextual feature space for selective heterogeneous feature fusion via a novel cross-task adapter, which leverages rich cross-view geometric cues to enhance scene parsing. To eliminate the dependence on costly human-annotated correspondence ground truth, TwInS is further equipped with a tailored semi-supervised training strategy, which unleashes the potential of large-scale multi-view data and enables continuous self-evolution without requiring ground-truth correspondences. Extensive experiments conducted on three public datasets validate the effectiveness of TwInS's core components and demonstrate its superior performance over existing state-of-the-art approaches. The source code will be made publicly available upon publication.
VTCBench: Can Vision-Language Models Understand Long Context with Vision-Text Compression?
Dec 23, 2025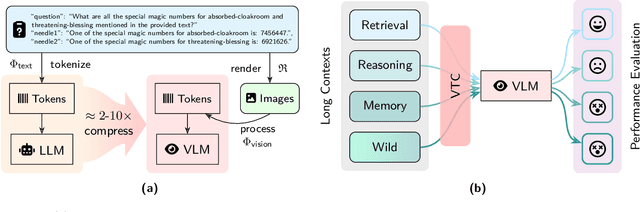

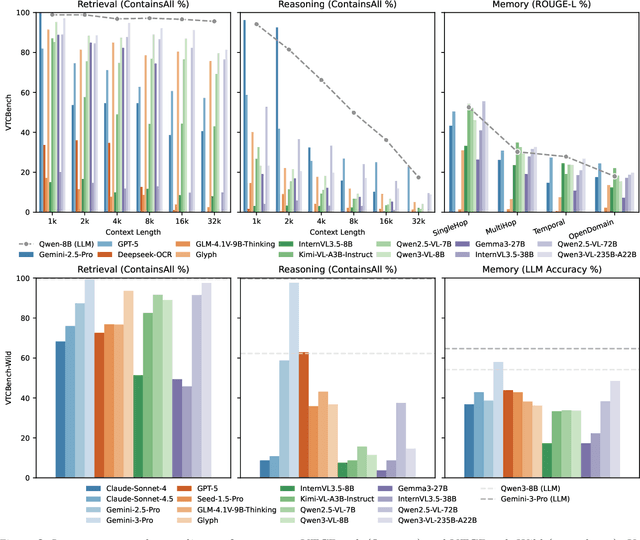
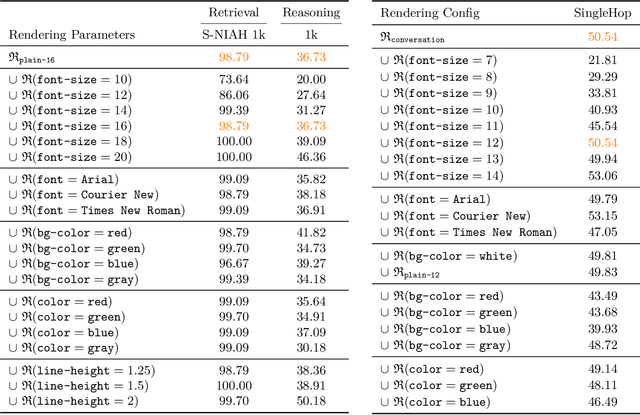
The computational and memory overheads associated with expanding the context window of LLMs severely limit their scalability. A noteworthy solution is vision-text compression (VTC), exemplified by frameworks like DeepSeek-OCR and Glyph, which convert long texts into dense 2D visual representations, thereby achieving token compression ratios of 3x-20x. However, the impact of this high information density on the core long-context capabilities of vision-language models (VLMs) remains under-investigated. To address this gap, we introduce the first benchmark for VTC and systematically assess the performance of VLMs across three long-context understanding settings: VTC-Retrieval, which evaluates the model's ability to retrieve and aggregate information; VTC-Reasoning, which requires models to infer latent associations to locate facts with minimal lexical overlap; and VTC-Memory, which measures comprehensive question answering within long-term dialogue memory. Furthermore, we establish the VTCBench-Wild to simulate diverse input scenarios.We comprehensively evaluate leading open-source and proprietary models on our benchmarks. The results indicate that, despite being able to decode textual information (e.g., OCR) well, most VLMs exhibit a surprisingly poor long-context understanding ability with VTC-processed information, failing to capture long associations or dependencies in the context.This study provides a deep understanding of VTC and serves as a foundation for designing more efficient and scalable VLMs.
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.
MLLM-CL: Continual Learning for Multimodal Large Language Models
Jun 05, 2025



Recent Multimodal Large Language Models (MLLMs) excel in vision-language understanding but face challenges in adapting to dynamic real-world scenarios that require continuous integration of new knowledge and skills. While continual learning (CL) offers a potential solution, existing benchmarks and methods suffer from critical limitations. In this paper, we introduce MLLM-CL, a novel benchmark encompassing domain and ability continual learning, where the former focuses on independently and identically distributed (IID) evaluation across evolving mainstream domains, whereas the latter evaluates on non-IID scenarios with emerging model ability. Methodologically, we propose preventing catastrophic interference through parameter isolation, along with an MLLM-based routing mechanism. Extensive experiments demonstrate that our approach can integrate domain-specific knowledge and functional abilities with minimal forgetting, significantly outperforming existing methods.
Restoring Real-World Images with an Internal Detail Enhancement Diffusion Model
May 24, 2025Restoring real-world degraded images, such as old photographs or low-resolution images, presents a significant challenge due to the complex, mixed degradations they exhibit, such as scratches, color fading, and noise. Recent data-driven approaches have struggled with two main challenges: achieving high-fidelity restoration and providing object-level control over colorization. While diffusion models have shown promise in generating high-quality images with specific controls, they often fail to fully preserve image details during restoration. In this work, we propose an internal detail-preserving diffusion model for high-fidelity restoration of real-world degraded images. Our method utilizes a pre-trained Stable Diffusion model as a generative prior, eliminating the need to train a model from scratch. Central to our approach is the Internal Image Detail Enhancement (IIDE) technique, which directs the diffusion model to preserve essential structural and textural information while mitigating degradation effects. The process starts by mapping the input image into a latent space, where we inject the diffusion denoising process with degradation operations that simulate the effects of various degradation factors. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art models in both qualitative assessments and perceptual quantitative evaluations. Additionally, our approach supports text-guided restoration, enabling object-level colorization control that mimics the expertise of professional photo editing.