 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Loop of Thought: Reversible Hierarchical Markov Chain for Efficient Mathematical Reasoning
Apr 08, 2026Multi-step Chain-of-Thought (CoT) has significantly advanced the mathematical reasoning capabilities of LLMs by leveraging explicit reasoning steps. However, the widespread adoption of Long CoT often results in sequence lengths that exceed manageable computational limits. While existing approaches attempt to alleviate this by reducing KV Cache redundancy via Markov chain-like structures, they introduce two critical limitations: inherent memorylessness (loss of context) and limited backward reasoning capability. To address these limitations, we propose a novel Chain-of-Thought framework based on Reversible Hierarchical Markov Chain, termed Cognitive Loop of Thought (CLoT), and a backward reasoning dataset CLoT-Instruct. In CLoT, problems are decomposed into sub-problems with hierarchical dependencies. Inspired by human cognitive processes, we introduce a backward verification mechanism at each hierarchical layer. Furthermore, we implement a pruning strategy: once higher-level sub-problems are verified, redundant lower-level sub-problems are pruned to maximize efficiency. This approach effectively mitigates error propagation and enhances reasoning robustness. Experiments on four mathematical benchmarks demonstrate the effectiveness of our method. Notably, on the AddSub dataset using GPT-4o-mini, CLoT achieves 99.0% accuracy, outperforming traditional CoT and CoT-SC by 4.1% and 2.9%, respectively.
Conformal Prediction Assessment: A Framework for Conditional Coverage Evaluation and Selection
Mar 28, 2026Conformal prediction provides rigorous distribution-free finite-sample guarantees for marginal coverage under the assumption of exchangeability, but may exhibit systematic undercoverage or overcoverage for specific subpopulations. Assessing conditional validity is challenging, as standard stratification methods suffer from the curse of dimensionality. We propose Conformal Prediction Assessment (CPA), a framework that reframes the evaluation of conditional coverage as a supervised learning task by training a reliability estimator that predicts instance-level coverage probabilities. Building on this estimator, we introduce the Conditional Validity Index (CVI), which decomposes reliability into safety (undercoverage risk) and efficiency (overcoverage cost). We establish convergence rates for the reliability estimator and prove the consistency of CVI-based model selection. Extensive experiments on synthetic and real-world datasets demonstrate that CPA effectively diagnoses local failure modes and that CC-Select, our CVI-based model selection algorithm, consistently identifies predictors with superior conditional coverage performance.
Think and Answer ME: Benchmarking and Exploring Multi-Entity Reasoning Grounding in Remote Sensing
Mar 13, 2026Recent advances in reasoning language models and reinforcement learning with verifiable rewards have significantly enhanced multi-step reasoning capabilities. This progress motivates the extension of reasoning paradigms to remote sensing visual grounding task. However, existing remote sensing grounding methods remain largely confined to perception-level matching and single-entity formulations, limiting the role of explicit reasoning and inter-entity modeling. To address this challenge, we introduce a new benchmark dataset for Multi-Entity Reasoning Grounding in Remote Sensing (ME-RSRG). Based on ME-RSRG, we reformulate remote sensing grounding as a multi-entity reasoning task and propose an Entity-Aware Reasoning (EAR) framework built upon visual-linguistic foundation models. EAR generates structured reasoning traces and subject-object grounding outputs. It adopts supervised fine-tuning for cold-start initialization and is further optimized via entity-aware reward-driven Group Relative Policy Optimization (GRPO). Extensive experiments on ME-RSRG demonstrate the challenges of multi-entity reasoning and verify the effectiveness of our proposed EAR framework. Our dataset, code, and models will be available at https://github.com/CV-ShuchangLyu/ME-RSRG.
Local-Global Feature Fusion for Subject-Independent EEG Emotion Recognition
Jan 13, 2026Subject-independent EEG emotion recognition is challenged by pronounced inter-subject variability and the difficulty of learning robust representations from short, noisy recordings. To address this, we propose a fusion framework that integrates (i) local, channel-wise descriptors and (ii) global, trial-level descriptors, improving cross-subject generalization on the SEED-VII dataset. Local representations are formed per channel by concatenating differential entropy with graph-theoretic features, while global representations summarize time-domain, spectral, and complexity characteristics at the trial level. These representations are fused in a dual-branch transformer with attention-based fusion and domain-adversarial regularization, with samples filtered by an intensity threshold. Experiments under a leave-one-subject-out protocol demonstrate that the proposed method consistently outperforms single-view and classical baselines, achieving approximately 40% mean accuracy in 7-class subject-independent emotion recognition. The code has been released at https://github.com/Danielz-z/LGF-EEG-Emotion.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Real, Fake, or Manipulated? Detecting Machine-Influenced Text
Sep 18, 2025Large Language Model (LLMs) can be used to write or modify documents, presenting a challenge for understanding the intent behind their use. For example, benign uses may involve using LLM on a human-written document to improve its grammar or to translate it into another language. However, a document entirely produced by a LLM may be more likely to be used to spread misinformation than simple translation (\eg, from use by malicious actors or simply by hallucinating). Prior works in Machine Generated Text (MGT) detection mostly focus on simply identifying whether a document was human or machine written, ignoring these fine-grained uses. In this paper, we introduce a HiErarchical, length-RObust machine-influenced text detector (HERO), which learns to separate text samples of varying lengths from four primary types: human-written, machine-generated, machine-polished, and machine-translated. HERO accomplishes this by combining predictions from length-specialist models that have been trained with Subcategory Guidance. Specifically, for categories that are easily confused (\eg, different source languages), our Subcategory Guidance module encourages separation of the fine-grained categories, boosting performance. Extensive experiments across five LLMs and six domains demonstrate the benefits of our HERO, outperforming the state-of-the-art by 2.5-3 mAP on average.
DiffHash: Text-Guided Targeted Attack via Diffusion Models against Deep Hashing Image Retrieval
Sep 16, 2025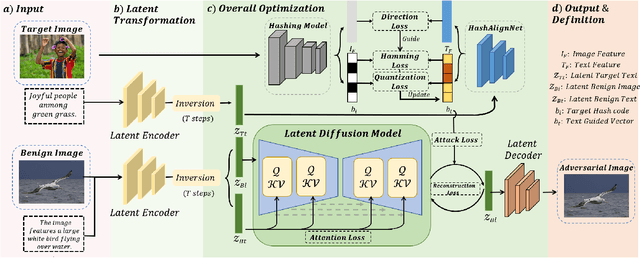
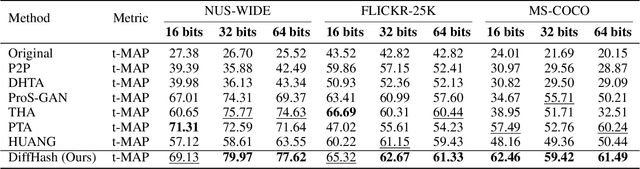
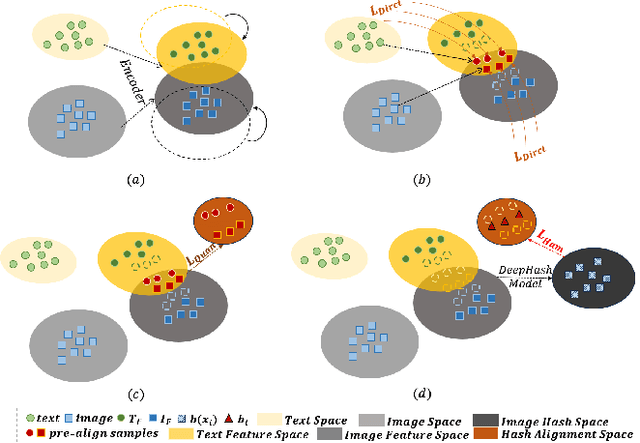
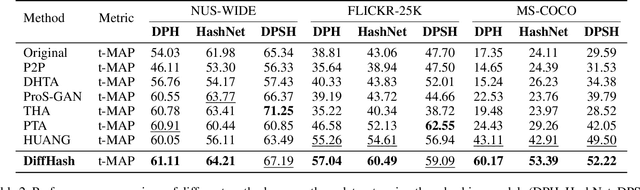
Deep hashing models have been widely adopted to tackle the challenges of large-scale image retrieval. However, these approaches face serious security risks due to their vulnerability to adversarial examples. Despite the increasing exploration of targeted attacks on deep hashing models, existing approaches still suffer from a lack of multimodal guidance, reliance on labeling information and dependence on pixel-level operations for attacks. To address these limitations, we proposed DiffHash, a novel diffusion-based targeted attack for deep hashing. Unlike traditional pixel-based attacks that directly modify specific pixels and lack multimodal guidance, our approach focuses on optimizing the latent representations of images, guided by text information generated by a Large Language Model (LLM) for the target image. Furthermore, we designed a multi-space hash alignment network to align the high-dimension image space and text space to the low-dimension binary hash space. During reconstruction, we also incorporated text-guided attention mechanisms to refine adversarial examples, ensuring them aligned with the target semantics while maintaining visual plausibility. Extensive experiments have demonstrated that our method outperforms state-of-the-art (SOTA) targeted attack methods, achieving better black-box transferability and offering more excellent stability across datasets.
Wavelet Mixture of Experts for Time Series Forecasting
Aug 12, 2025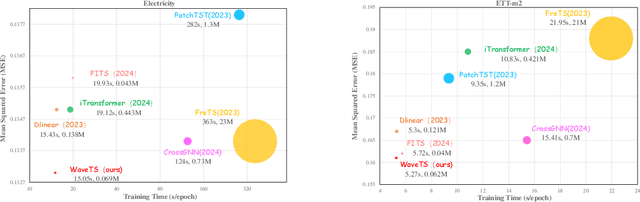
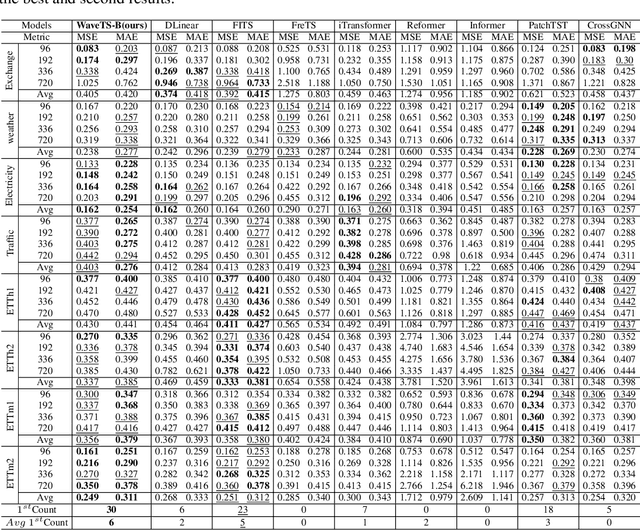
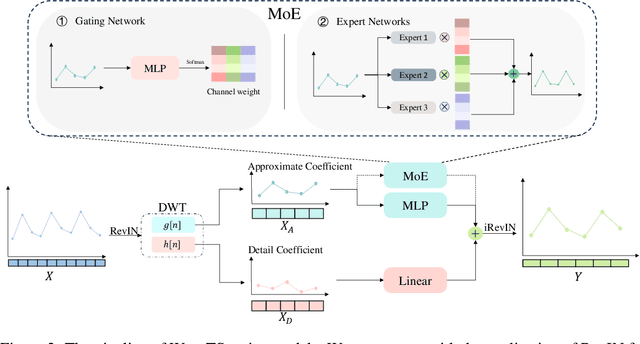
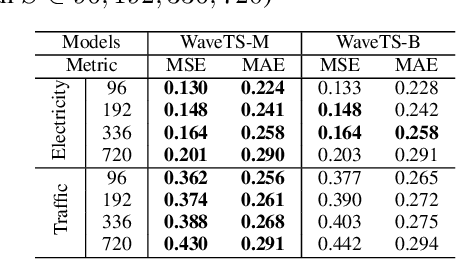
The field of time series forecasting is rapidly advancing, with recent large-scale Transformers and lightweight Multilayer Perceptron (MLP) models showing strong predictive performance. However, conventional Transformer models are often hindered by their large number of parameters and their limited ability to capture non-stationary features in data through smoothing. Similarly, MLP models struggle to manage multi-channel dependencies effectively. To address these limitations, we propose a novel, lightweight time series prediction model, WaveTS-B. This model combines wavelet transforms with MLP to capture both periodic and non-stationary characteristics of data in the wavelet domain. Building on this foundation, we propose a channel clustering strategy that incorporates a Mixture of Experts (MoE) framework, utilizing a gating mechanism and expert network to handle multi-channel dependencies efficiently. We propose WaveTS-M, an advanced model tailored for multi-channel time series prediction. Empirical evaluation across eight real-world time series datasets demonstrates that our WaveTS series models achieve state-of-the-art (SOTA) performance with significantly fewer parameters. Notably, WaveTS-M shows substantial improvements on multi-channel datasets, highlighting its effectiveness.
CausalDiffTab: Mixed-Type Causal-Aware Diffusion for Tabular Data Generation
Jun 17, 2025Training data has been proven to be one of the most critical components in training generative AI. However, obtaining high-quality data remains challenging, with data privacy issues presenting a significant hurdle. To address the need for high-quality data. Synthesize data has emerged as a mainstream solution, demonstrating impressive performance in areas such as images, audio, and video. Generating mixed-type data, especially high-quality tabular data, still faces significant challenges. These primarily include its inherent heterogeneous data types, complex inter-variable relationships, and intricate column-wise distributions. In this paper, we introduce CausalDiffTab, a diffusion model-based generative model specifically designed to handle mixed tabular data containing both numerical and categorical features, while being more flexible in capturing complex interactions among variables. We further propose a hybrid adaptive causal regularization method based on the principle of Hierarchical Prior Fusion. This approach adaptively controls the weight of causal regularization, enhancing the model's performance without compromising its generative capabilities. Comprehensive experiments conducted on seven datasets demonstrate that CausalDiffTab outperforms baseline methods across all metrics. Our code is publicly available at: https://github.com/Godz-z/CausalDiffTab.
GaussianCAD: Robust Self-Supervised CAD Reconstruction from Three Orthographic Views Using 3D Gaussian Splatting
Mar 07, 2025



The automatic reconstruction of 3D computer-aided design (CAD) models from CAD sketches has recently gained significant attention in the computer vision community. Most existing methods, however, rely on vector CAD sketches and 3D ground truth for supervision, which are often difficult to be obtained in industrial applications and are sensitive to noise inputs. We propose viewing CAD reconstruction as a specific instance of sparse-view 3D reconstruction to overcome these limitations. While this reformulation offers a promising perspective, existing 3D reconstruction methods typically require natural images and corresponding camera poses as inputs, which introduces two major significant challenges: (1) modality discrepancy between CAD sketches and natural images, and (2) difficulty of accurate camera pose estimation for CAD sketches. To solve these issues, we first transform the CAD sketches into representations resembling natural images and extract corresponding masks. Next, we manually calculate the camera poses for the orthographic views to ensure accurate alignment within the 3D coordinate system. Finally, we employ a customized sparse-view 3D reconstruction method to achieve high-quality reconstructions from aligned orthographic views. By leveraging raster CAD sketches for self-supervision, our approach eliminates the reliance on vector CAD sketches and 3D ground truth. Experiments on the Sub-Fusion360 dataset demonstrate that our proposed method significantly outperforms previous approaches in CAD reconstruction performance and exhibits strong robustness to noisy inputs.