 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink and Answer ME: Benchmarking and Exploring Multi-Entity Reasoning Grounding in Remote Sensing
Mar 13, 2026Recent advances in reasoning language models and reinforcement learning with verifiable rewards have significantly enhanced multi-step reasoning capabilities. This progress motivates the extension of reasoning paradigms to remote sensing visual grounding task. However, existing remote sensing grounding methods remain largely confined to perception-level matching and single-entity formulations, limiting the role of explicit reasoning and inter-entity modeling. To address this challenge, we introduce a new benchmark dataset for Multi-Entity Reasoning Grounding in Remote Sensing (ME-RSRG). Based on ME-RSRG, we reformulate remote sensing grounding as a multi-entity reasoning task and propose an Entity-Aware Reasoning (EAR) framework built upon visual-linguistic foundation models. EAR generates structured reasoning traces and subject-object grounding outputs. It adopts supervised fine-tuning for cold-start initialization and is further optimized via entity-aware reward-driven Group Relative Policy Optimization (GRPO). Extensive experiments on ME-RSRG demonstrate the challenges of multi-entity reasoning and verify the effectiveness of our proposed EAR framework. Our dataset, code, and models will be available at https://github.com/CV-ShuchangLyu/ME-RSRG.
RAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection
Aug 06, 2025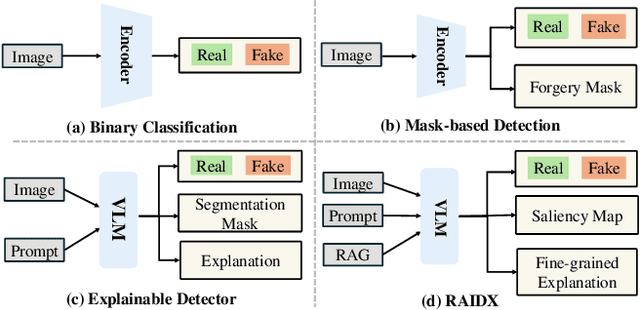
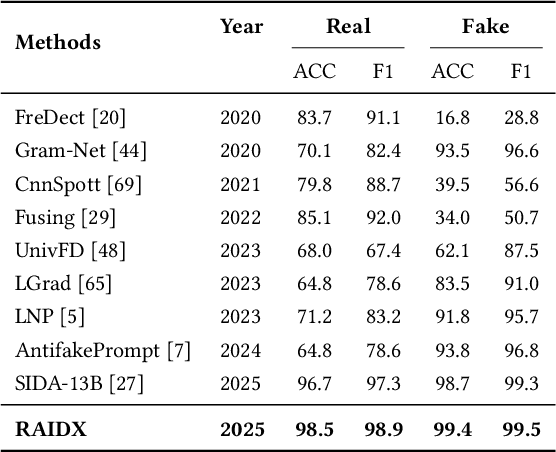
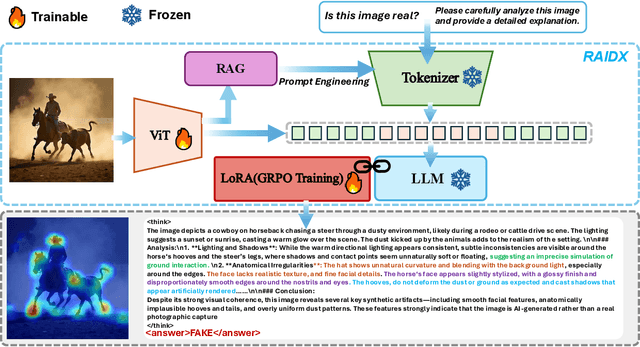
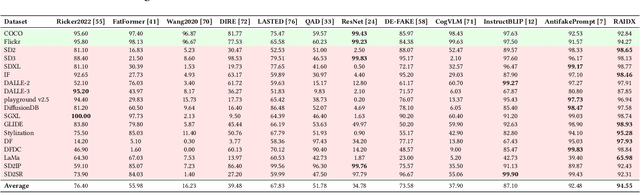
The rapid advancement of AI-generation models has enabled the creation of hyperrealistic imagery, posing ethical risks through widespread misinformation. Current deepfake detection methods, categorized as face specific detectors or general AI-generated detectors, lack transparency by framing detection as a classification task without explaining decisions. While several LLM-based approaches offer explainability, they suffer from coarse-grained analyses and dependency on labor-intensive annotations. This paper introduces RAIDX (Retrieval-Augmented Image Deepfake Detection and Explainability), a novel deepfake detection framework integrating Retrieval-Augmented Generation (RAG) and Group Relative Policy Optimization (GRPO) to enhance detection accuracy and decision explainability. Specifically, RAIDX leverages RAG to incorporate external knowledge for improved detection accuracy and employs GRPO to autonomously generate fine-grained textual explanations and saliency maps, eliminating the need for extensive manual annotations. Experiments on multiple benchmarks demonstrate RAIDX's effectiveness in identifying real or fake, and providing interpretable rationales in both textual descriptions and saliency maps, achieving state-of-the-art detection performance while advancing transparency in deepfake identification. RAIDX represents the first unified framework to synergize RAG and GRPO, addressing critical gaps in accuracy and explainability. Our code and models will be publicly available.
Vision Mamba in Remote Sensing: A Comprehensive Survey of Techniques, Applications and Outlook
May 01, 2025Deep learning has profoundly transformed remote sensing, yet prevailing architectures like Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) remain constrained by critical trade-offs: CNNs suffer from limited receptive fields, while ViTs grapple with quadratic computational complexity, hindering their scalability for high-resolution remote sensing data. State Space Models (SSMs), particularly the recently proposed Mamba architecture, have emerged as a paradigm-shifting solution, combining linear computational scaling with global context modeling. This survey presents a comprehensive review of Mamba-based methodologies in remote sensing, systematically analyzing about 120 studies to construct a holistic taxonomy of innovations and applications. Our contributions are structured across five dimensions: (i) foundational principles of vision Mamba architectures, (ii) micro-architectural advancements such as adaptive scan strategies and hybrid SSM formulations, (iii) macro-architectural integrations, including CNN-Transformer-Mamba hybrids and frequency-domain adaptations, (iv) rigorous benchmarking against state-of-the-art methods in multiple application tasks, such as object detection, semantic segmentation, change detection, etc. and (v) critical analysis of unresolved challenges with actionable future directions. By bridging the gap between SSM theory and remote sensing practice, this survey establishes Mamba as a transformative framework for remote sensing analysis. To our knowledge, this paper is the first systematic review of Mamba architectures in remote sensing. Our work provides a structured foundation for advancing research in remote sensing systems through SSM-based methods. We curate an open-source repository (https://github.com/BaoBao0926/Awesome-Mamba-in-Remote-Sensing) to foster community-driven advancements.
ASP-VMUNet: Atrous Shifted Parallel Vision Mamba U-Net for Skin Lesion Segmentation
Mar 25, 2025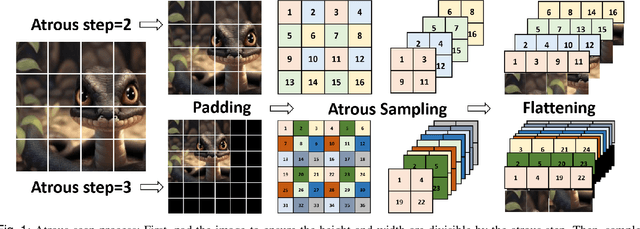
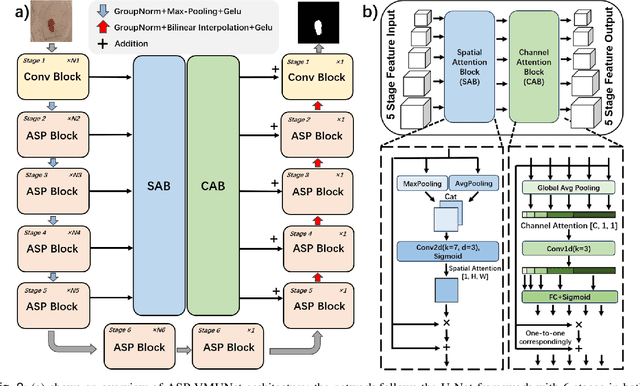
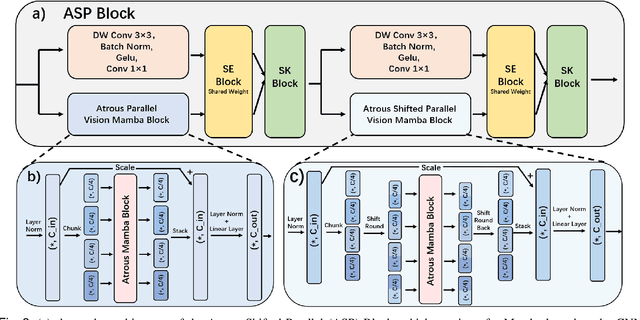
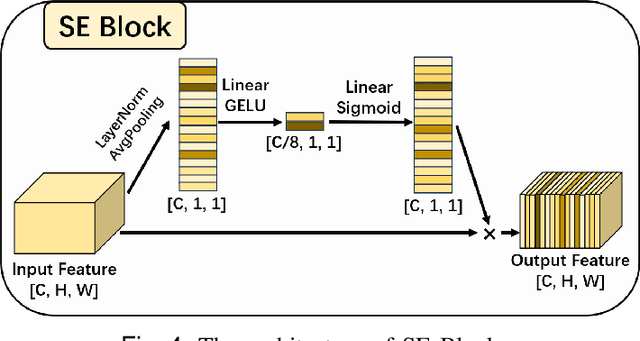
Skin lesion segmentation is a critical challenge in computer vision, and it is essential to separate pathological features from healthy skin for diagnostics accurately. Traditional Convolutional Neural Networks (CNNs) are limited by narrow receptive fields, and Transformers face significant computational burdens. This paper presents a novel skin lesion segmentation framework, the Atrous Shifted Parallel Vision Mamba UNet (ASP-VMUNet), which integrates the efficient and scalable Mamba architecture to overcome limitations in traditional CNNs and computationally demanding Transformers. The framework introduces an atrous scan technique that minimizes background interference and expands the receptive field, enhancing Mamba's scanning capabilities. Additionally, the inclusion of a Parallel Vision Mamba (PVM) layer and a shift round operation optimizes feature segmentation and fosters rich inter-segment information exchange. A supplementary CNN branch with a Selective-Kernel (SK) Block further refines the segmentation by blending local and global contextual information. Tested on four benchmark datasets (ISIC16/17/18 and PH2), ASP-VMUNet demonstrates superior performance in skin lesion segmentation, validated by comprehensive ablation studies. This approach not only advances medical image segmentation but also highlights the benefits of hybrid architectures in medical imaging technology. Our code is available at https://github.com/BaoBao0926/ASP-VMUNet/tree/main.
Joint-Optimized Unsupervised Adversarial Domain Adaptation in Remote Sensing Segmentation with Prompted Foundation Model
Nov 18, 2024



Unsupervised Domain Adaptation for Remote Sensing Semantic Segmentation (UDA-RSSeg) addresses the challenge of adapting a model trained on source domain data to target domain samples, thereby minimizing the need for annotated data across diverse remote sensing scenes. This task presents two principal challenges: (1) severe inconsistencies in feature representation across different remote sensing domains, and (2) a domain gap that emerges due to the representation bias of source domain patterns when translating features to predictive logits. To tackle these issues, we propose a joint-optimized adversarial network incorporating the "Segment Anything Model (SAM) (SAM-JOANet)" for UDA-RSSeg. Our approach integrates SAM to leverage its robust generalized representation capabilities, thereby alleviating feature inconsistencies. We introduce a finetuning decoder designed to convert SAM-Encoder features into predictive logits. Additionally, a feature-level adversarial-based prompted segmentor is employed to generate class-agnostic maps, which guide the finetuning decoder's feature representations. The network is optimized end-to-end, combining the prompted segmentor and the finetuning decoder. Extensive evaluations on benchmark datasets, including ISPRS (Potsdam/Vaihingen) and CITY-OSM (Paris/Chicago), demonstrate the effectiveness of our method. The results, supported by visualization and analysis, confirm the method's interpretability and robustness. The code of this paper is available at https://github.com/CV-ShuchangLyu/SAM-JOANet.
BEARD: Benchmarking the Adversarial Robustness for Dataset Distillation
Nov 14, 2024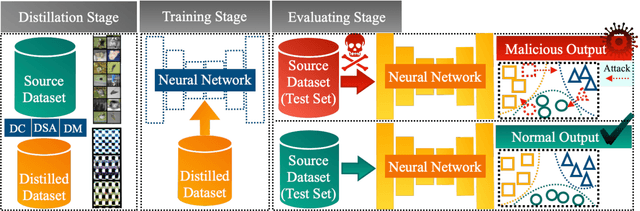
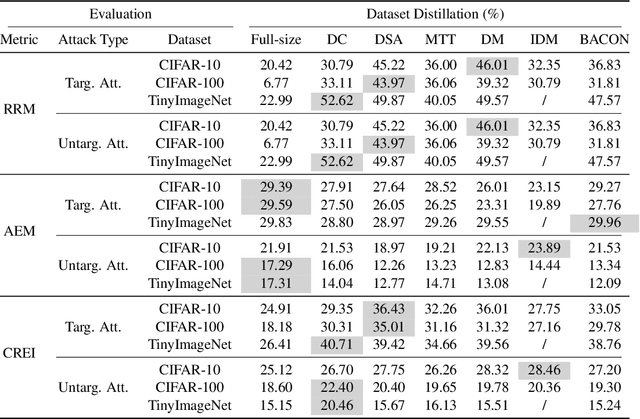
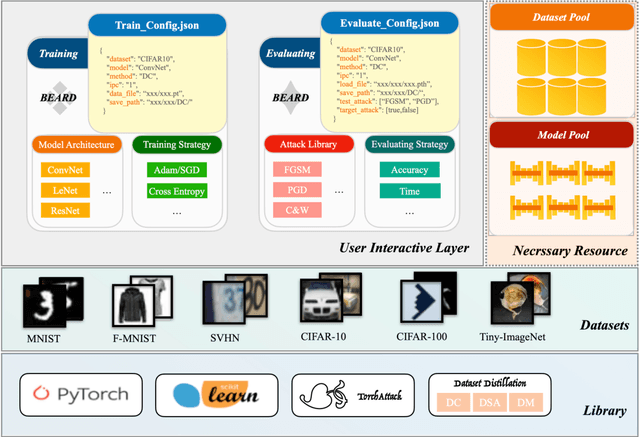
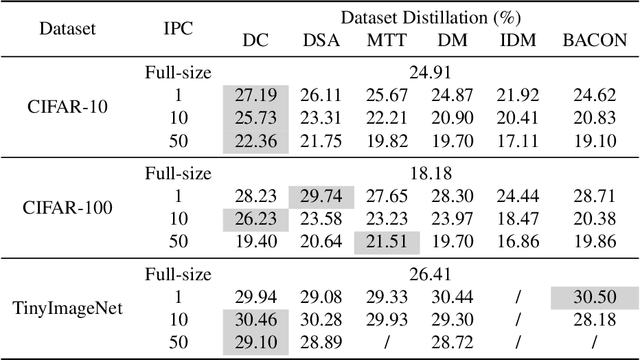
Dataset Distillation (DD) is an emerging technique that compresses large-scale datasets into significantly smaller synthesized datasets while preserving high test performance and enabling the efficient training of large models. However, current research primarily focuses on enhancing evaluation accuracy under limited compression ratios, often overlooking critical security concerns such as adversarial robustness. A key challenge in evaluating this robustness lies in the complex interactions between distillation methods, model architectures, and adversarial attack strategies, which complicate standardized assessments. To address this, we introduce BEARD, an open and unified benchmark designed to systematically assess the adversarial robustness of DD methods, including DM, IDM, and BACON. BEARD encompasses a variety of adversarial attacks (e.g., FGSM, PGD, C&W) on distilled datasets like CIFAR-10/100 and TinyImageNet. Utilizing an adversarial game framework, it introduces three key metrics: Robustness Ratio (RR), Attack Efficiency Ratio (AE), and Comprehensive Robustness-Efficiency Index (CREI). Our analysis includes unified benchmarks, various Images Per Class (IPC) settings, and the effects of adversarial training. Results are available on the BEARD Leaderboard, along with a library providing model and dataset pools to support reproducible research. Access the code at BEARD.
BACON: Bayesian Optimal Condensation Framework for Dataset Distillation
Jun 03, 2024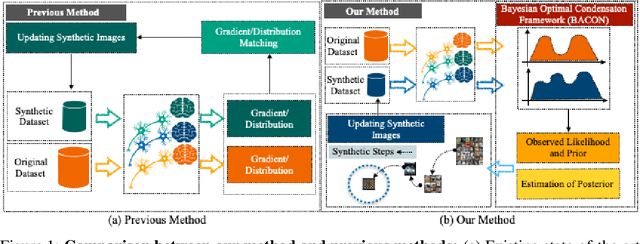
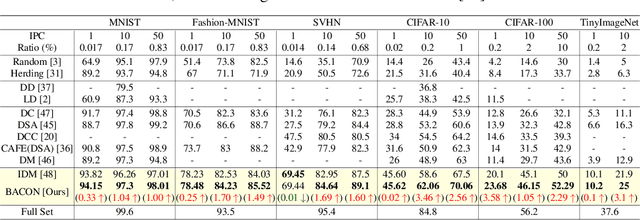
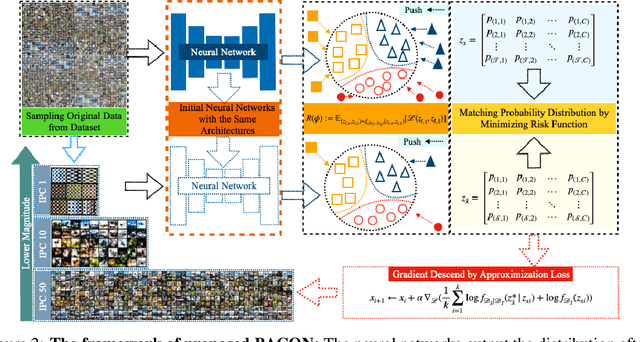
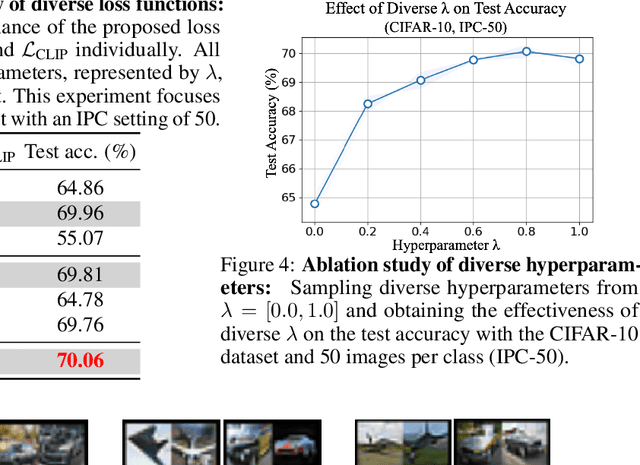
Dataset Distillation (DD) aims to distill knowledge from extensive datasets into more compact ones while preserving performance on the test set, thereby reducing storage costs and training expenses. However, existing methods often suffer from computational intensity, particularly exhibiting suboptimal performance with large dataset sizes due to the lack of a robust theoretical framework for analyzing the DD problem. To address these challenges, we propose the BAyesian optimal CONdensation framework (BACON), which is the first work to introduce the Bayesian theoretical framework to the literature of DD. This framework provides theoretical support for enhancing the performance of DD. Furthermore, BACON formulates the DD problem as the minimization of the expected risk function in joint probability distributions using the Bayesian framework. Additionally, by analyzing the expected risk function for optimal condensation, we derive a numerically feasible lower bound based on specific assumptions, providing an approximate solution for BACON. We validate BACON across several datasets, demonstrating its superior performance compared to existing state-of-the-art methods. For instance, under the IPC-10 setting, BACON achieves a 3.46% accuracy gain over the IDM method on the CIFAR-10 dataset and a 3.10% gain on the TinyImageNet dataset. Our extensive experiments confirm the effectiveness of BACON and its seamless integration with existing methods, thereby enhancing their performance for the DD task. Code and distilled datasets are available at BACON.
MVPatch: More Vivid Patch for Adversarial Camouflaged Attacks on Object Detectors in the Physical World
Jan 12, 2024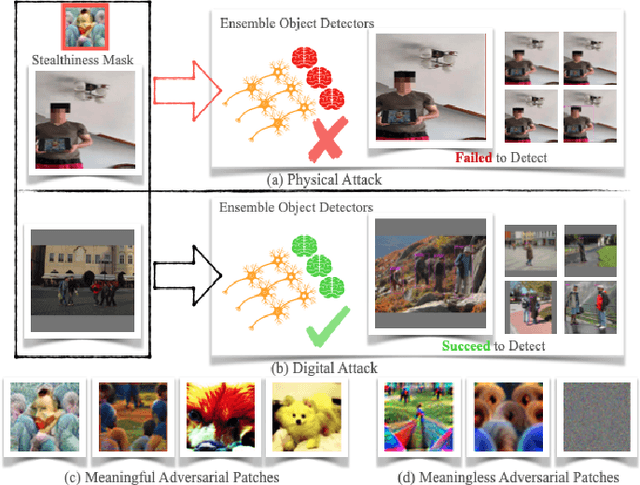
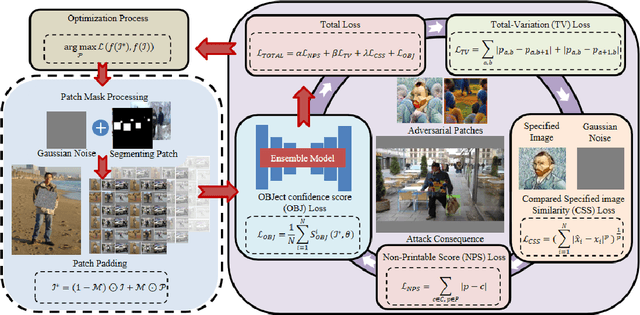


Recent investigations demonstrate that adversarial patches can be utilized to manipulate the result of object detection models. However, the conspicuous patterns on these patches may draw more attention and raise suspicions among humans. Moreover, existing works have primarily focused on enhancing the efficacy of attacks in the physical domain, rather than seeking to optimize their stealth attributes and transferability potential. To address these issues, we introduce a dual-perception-based attack framework that generates an adversarial patch known as the More Vivid Patch (MVPatch). The framework consists of a model-perception degradation method and a human-perception improvement method. To derive the MVPatch, we formulate an iterative process that simultaneously constrains the efficacy of multiple object detectors and refines the visual correlation between the generated adversarial patch and a realistic image. Our method employs a model-perception-based approach that reduces the object confidence scores of several object detectors to boost the transferability of adversarial patches. Further, within the human-perception-based framework, we put forward a lightweight technique for visual similarity measurement that facilitates the development of inconspicuous and natural adversarial patches and eliminates the reliance on additional generative models. Additionally, we introduce the naturalness score and transferability score as metrics for an unbiased assessment of various adversarial patches' natural appearance and transferability capacity. Extensive experiments demonstrate that the proposed MVPatch algorithm achieves superior attack transferability compared to similar algorithms in both digital and physical domains while also exhibiting a more natural appearance. These findings emphasize the remarkable stealthiness and transferability of the proposed MVPatch attack algorithm.
OV-VG: A Benchmark for Open-Vocabulary Visual Grounding
Oct 22, 2023



Open-vocabulary learning has emerged as a cutting-edge research area, particularly in light of the widespread adoption of vision-based foundational models. Its primary objective is to comprehend novel concepts that are not encompassed within a predefined vocabulary. One key facet of this endeavor is Visual Grounding, which entails locating a specific region within an image based on a corresponding language description. While current foundational models excel at various visual language tasks, there's a noticeable absence of models specifically tailored for open-vocabulary visual grounding. This research endeavor introduces novel and challenging OV tasks, namely Open-Vocabulary Visual Grounding and Open-Vocabulary Phrase Localization. The overarching aim is to establish connections between language descriptions and the localization of novel objects. To facilitate this, we have curated a comprehensive annotated benchmark, encompassing 7,272 OV-VG images and 1,000 OV-PL images. In our pursuit of addressing these challenges, we delved into various baseline methodologies rooted in existing open-vocabulary object detection, VG, and phrase localization frameworks. Surprisingly, we discovered that state-of-the-art methods often falter in diverse scenarios. Consequently, we developed a novel framework that integrates two critical components: Text-Image Query Selection and Language-Guided Feature Attention. These modules are designed to bolster the recognition of novel categories and enhance the alignment between visual and linguistic information. Extensive experiments demonstrate the efficacy of our proposed framework, which consistently attains SOTA performance across the OV-VG task. Additionally, ablation studies provide further evidence of the effectiveness of our innovative models. Codes and datasets will be made publicly available at https://github.com/cv516Buaa/OV-VG.
Iterative Robust Visual Grounding with Masked Reference based Centerpoint Supervision
Jul 23, 2023



Visual Grounding (VG) aims at localizing target objects from an image based on given expressions and has made significant progress with the development of detection and vision transformer. However, existing VG methods tend to generate false-alarm objects when presented with inaccurate or irrelevant descriptions, which commonly occur in practical applications. Moreover, existing methods fail to capture fine-grained features, accurate localization, and sufficient context comprehension from the whole image and textual descriptions. To address both issues, we propose an Iterative Robust Visual Grounding (IR-VG) framework with Masked Reference based Centerpoint Supervision (MRCS). The framework introduces iterative multi-level vision-language fusion (IMVF) for better alignment. We use MRCS to ahieve more accurate localization with point-wised feature supervision. Then, to improve the robustness of VG, we also present a multi-stage false-alarm sensitive decoder (MFSD) to prevent the generation of false-alarm objects when presented with inaccurate expressions. The proposed framework is evaluated on five regular VG datasets and two newly constructed robust VG datasets. Extensive experiments demonstrate that IR-VG achieves new state-of-the-art (SOTA) results, with improvements of 25\% and 10\% compared to existing SOTA approaches on the two newly proposed robust VG datasets. Moreover, the proposed framework is also verified effective on five regular VG datasets. Codes and models will be publicly at https://github.com/cv516Buaa/IR-VG.