 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient3D: A Unified Framework for Adaptive and Debiased Token Reduction in 3D MLLMs
Apr 03, 2026Recent advances in Multimodal Large Language Models (MLLMs) have expanded reasoning capabilities into 3D domains, enabling fine-grained spatial understanding. However, the substantial size of 3D MLLMs and the high dimensionality of input features introduce considerable inference overhead, which limits practical deployment on resource constrained platforms. To overcome this limitation, this paper presents Efficient3D, a unified framework for visual token pruning that accelerates 3D MLLMs while maintaining competitive accuracy. The proposed framework introduces a Debiased Visual Token Importance Estimator (DVTIE) module, which considers the influence of shallow initial layers during attention aggregation, thereby producing more reliable importance predictions for visual tokens. In addition, an Adaptive Token Rebalancing (ATR) strategy is developed to dynamically adjust pruning strength based on scene complexity, preserving semantic completeness and maintaining balanced attention across layers. Together, they enable context-aware token reduction that maintains essential semantics with lower computation. Comprehensive experiments conducted on five representative 3D vision and language benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D, demonstrate that Efficient3D achieves superior performance compared with unpruned baselines, with a +2.57% CIDEr improvement on the Scan2Cap dataset. Therefore, Efficient3D provides a scalable and effective solution for efficient inference in 3D MLLMs. The code is released at: https://github.com/sol924/Efficient3D
Think and Answer ME: Benchmarking and Exploring Multi-Entity Reasoning Grounding in Remote Sensing
Mar 13, 2026Recent advances in reasoning language models and reinforcement learning with verifiable rewards have significantly enhanced multi-step reasoning capabilities. This progress motivates the extension of reasoning paradigms to remote sensing visual grounding task. However, existing remote sensing grounding methods remain largely confined to perception-level matching and single-entity formulations, limiting the role of explicit reasoning and inter-entity modeling. To address this challenge, we introduce a new benchmark dataset for Multi-Entity Reasoning Grounding in Remote Sensing (ME-RSRG). Based on ME-RSRG, we reformulate remote sensing grounding as a multi-entity reasoning task and propose an Entity-Aware Reasoning (EAR) framework built upon visual-linguistic foundation models. EAR generates structured reasoning traces and subject-object grounding outputs. It adopts supervised fine-tuning for cold-start initialization and is further optimized via entity-aware reward-driven Group Relative Policy Optimization (GRPO). Extensive experiments on ME-RSRG demonstrate the challenges of multi-entity reasoning and verify the effectiveness of our proposed EAR framework. Our dataset, code, and models will be available at https://github.com/CV-ShuchangLyu/ME-RSRG.
Pareto-Guided Optimization for Uncertainty-Aware Medical Image Segmentation
Jan 27, 2026Uncertainty in medical image segmentation is inherently non-uniform, with boundary regions exhibiting substantially higher ambiguity than interior areas. Conventional training treats all pixels equally, leading to unstable optimization during early epochs when predictions are unreliable. We argue that this instability hinders convergence toward Pareto-optimal solutions and propose a region-wise curriculum strategy that prioritizes learning from certain regions and gradually incorporates uncertain ones, reducing gradient variance. Methodologically, we introduce a Pareto-consistent loss that balances trade-offs between regional uncertainties by adaptively reshaping the loss landscape and constraining convergence dynamics between interior and boundary regions; this guides the model toward Pareto-approximate solutions. To address boundary ambiguity, we further develop a fuzzy labeling mechanism that maintains binary confidence in non-boundary areas while enabling smooth transitions near boundaries, stabilizing gradients, and expanding flat regions in the loss surface. Experiments on brain metastasis and non-metastatic tumor segmentation show consistent improvements across multiple configurations, with our method outperforming traditional crisp-set approaches in all tumor subregions.
Beyond Segmentation: An Oil Spill Change Detection Framework Using Synthetic SAR Imagery
Jan 05, 2026Marine oil spills are urgent environmental hazards that demand rapid and reliable detection to minimise ecological and economic damage. While Synthetic Aperture Radar (SAR) imagery has become a key tool for large-scale oil spill monitoring, most existing detection methods rely on deep learning-based segmentation applied to single SAR images. These static approaches struggle to distinguish true oil spills from visually similar oceanic features (e.g., biogenic slicks or low-wind zones), leading to high false positive rates and limited generalizability, especially under data-scarce conditions. To overcome these limitations, we introduce Oil Spill Change Detection (OSCD), a new bi-temporal task that focuses on identifying changes between pre- and post-spill SAR images. As real co-registered pre-spill imagery is not always available, we propose the Temporal-Aware Hybrid Inpainting (TAHI) framework, which generates synthetic pre-spill images from post-spill SAR data. TAHI integrates two key components: High-Fidelity Hybrid Inpainting for oil-free reconstruction, and Temporal Realism Enhancement for radiometric and sea-state consistency. Using TAHI, we construct the first OSCD dataset and benchmark several state-of-the-art change detection models. Results show that OSCD significantly reduces false positives and improves detection accuracy compared to conventional segmentation, demonstrating the value of temporally-aware methods for reliable, scalable oil spill monitoring in real-world scenarios.
RAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection
Aug 06, 2025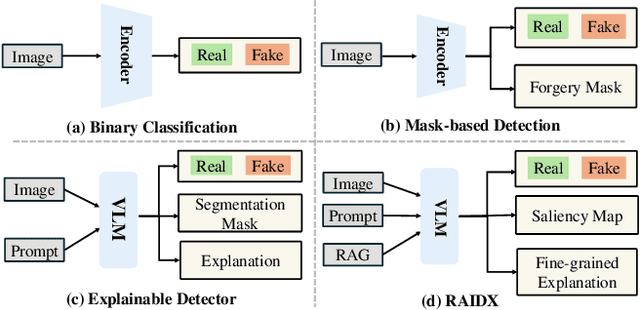
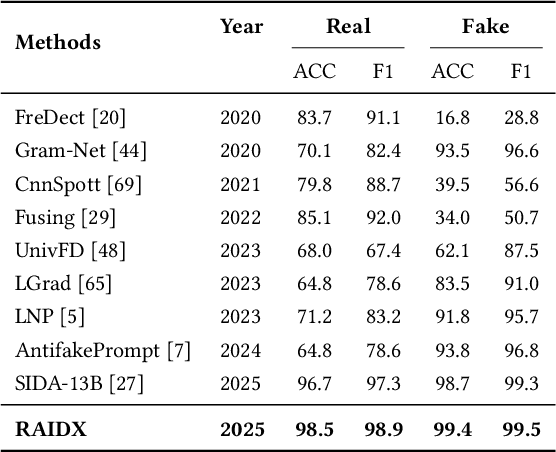
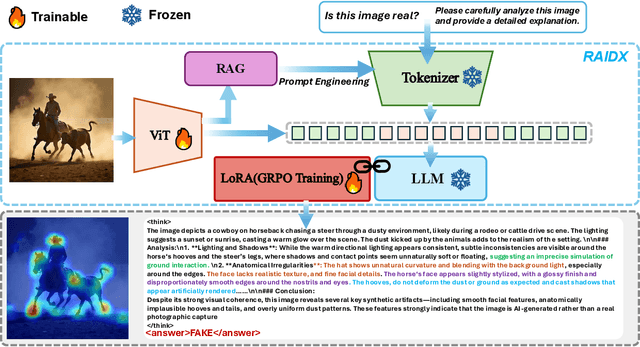
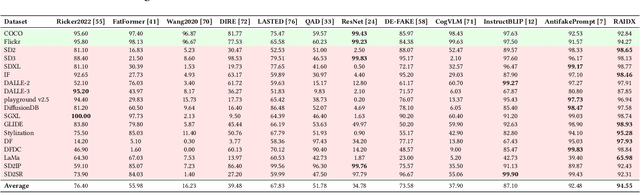
The rapid advancement of AI-generation models has enabled the creation of hyperrealistic imagery, posing ethical risks through widespread misinformation. Current deepfake detection methods, categorized as face specific detectors or general AI-generated detectors, lack transparency by framing detection as a classification task without explaining decisions. While several LLM-based approaches offer explainability, they suffer from coarse-grained analyses and dependency on labor-intensive annotations. This paper introduces RAIDX (Retrieval-Augmented Image Deepfake Detection and Explainability), a novel deepfake detection framework integrating Retrieval-Augmented Generation (RAG) and Group Relative Policy Optimization (GRPO) to enhance detection accuracy and decision explainability. Specifically, RAIDX leverages RAG to incorporate external knowledge for improved detection accuracy and employs GRPO to autonomously generate fine-grained textual explanations and saliency maps, eliminating the need for extensive manual annotations. Experiments on multiple benchmarks demonstrate RAIDX's effectiveness in identifying real or fake, and providing interpretable rationales in both textual descriptions and saliency maps, achieving state-of-the-art detection performance while advancing transparency in deepfake identification. RAIDX represents the first unified framework to synergize RAG and GRPO, addressing critical gaps in accuracy and explainability. Our code and models will be publicly available.
So-Fake: Benchmarking and Explaining Social Media Image Forgery Detection
May 24, 2025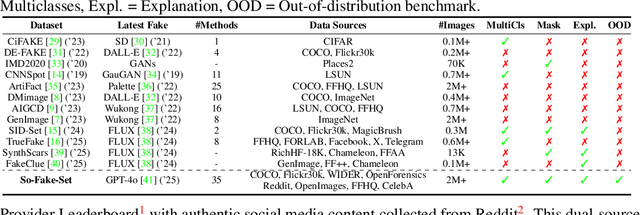
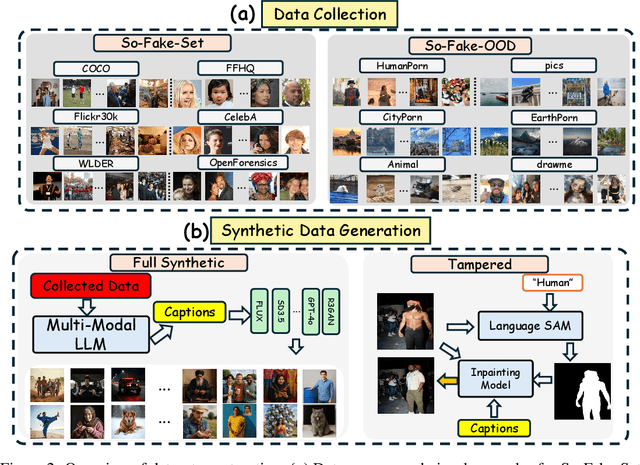
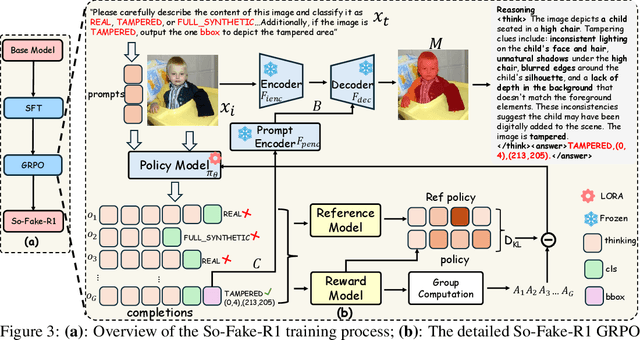
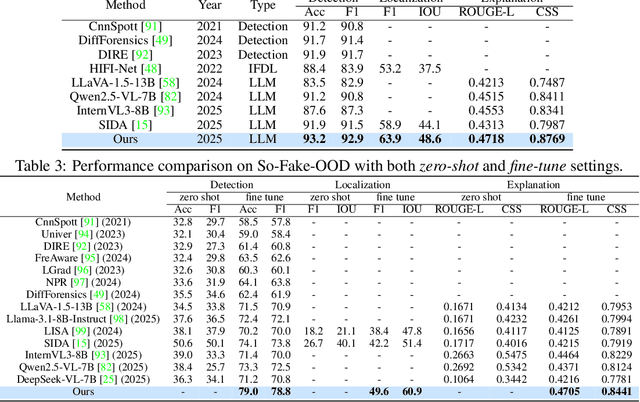
Recent advances in AI-powered generative models have enabled the creation of increasingly realistic synthetic images, posing significant risks to information integrity and public trust on social media platforms. While robust detection frameworks and diverse, large-scale datasets are essential to mitigate these risks, existing academic efforts remain limited in scope: current datasets lack the diversity, scale, and realism required for social media contexts, while detection methods struggle with generalization to unseen generative technologies. To bridge this gap, we introduce So-Fake-Set, a comprehensive social media-oriented dataset with over 2 million high-quality images, diverse generative sources, and photorealistic imagery synthesized using 35 state-of-the-art generative models. To rigorously evaluate cross-domain robustness, we establish a novel and large-scale (100K) out-of-domain benchmark (So-Fake-OOD) featuring synthetic imagery from commercial models explicitly excluded from the training distribution, creating a realistic testbed for evaluating real-world performance. Leveraging these resources, we present So-Fake-R1, an advanced vision-language framework that employs reinforcement learning for highly accurate forgery detection, precise localization, and explainable inference through interpretable visual rationales. Extensive experiments show that So-Fake-R1 outperforms the second-best method, with a 1.3% gain in detection accuracy and a 4.5% increase in localization IoU. By integrating a scalable dataset, a challenging OOD benchmark, and an advanced detection framework, this work establishes a new foundation for social media-centric forgery detection research. The code, models, and datasets will be released publicly.
BusterX: MLLM-Powered AI-Generated Video Forgery Detection and Explanation
May 19, 2025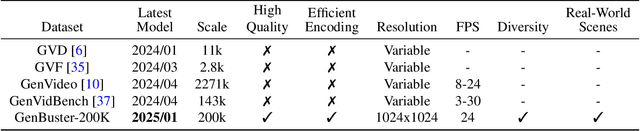
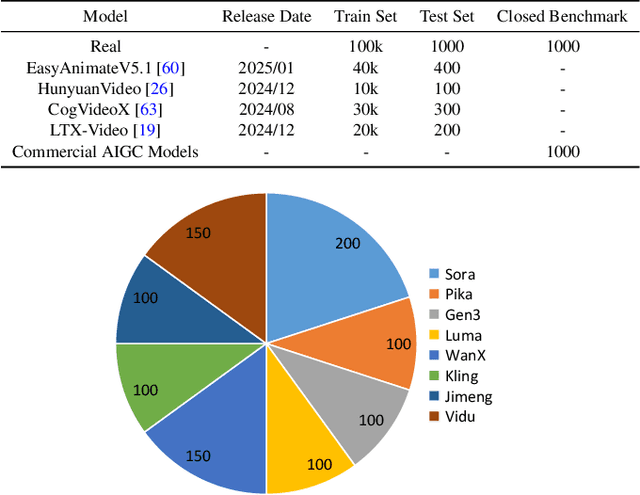
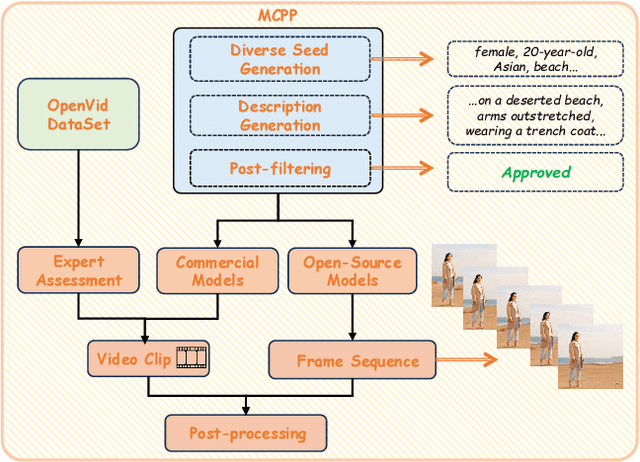
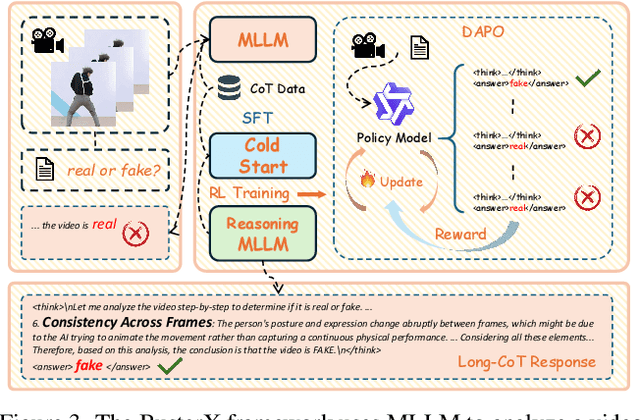
Advances in AI generative models facilitate super-realistic video synthesis, amplifying misinformation risks via social media and eroding trust in digital content. Several research works have explored new deepfake detection methods on AI-generated images to alleviate these risks. However, with the fast development of video generation models, such as Sora and WanX, there is currently a lack of large-scale, high-quality AI-generated video datasets for forgery detection. In addition, existing detection approaches predominantly treat the task as binary classification, lacking explainability in model decision-making and failing to provide actionable insights or guidance for the public. To address these challenges, we propose \textbf{GenBuster-200K}, a large-scale AI-generated video dataset featuring 200K high-resolution video clips, diverse latest generative techniques, and real-world scenes. We further introduce \textbf{BusterX}, a novel AI-generated video detection and explanation framework leveraging multimodal large language model (MLLM) and reinforcement learning for authenticity determination and explainable rationale. To our knowledge, GenBuster-200K is the {\it \textbf{first}} large-scale, high-quality AI-generated video dataset that incorporates the latest generative techniques for real-world scenarios. BusterX is the {\it \textbf{first}} framework to integrate MLLM with reinforcement learning for explainable AI-generated video detection. Extensive comparisons with state-of-the-art methods and ablation studies validate the effectiveness and generalizability of BusterX. The code, models, and datasets will be released.
Vision Mamba in Remote Sensing: A Comprehensive Survey of Techniques, Applications and Outlook
May 01, 2025Deep learning has profoundly transformed remote sensing, yet prevailing architectures like Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) remain constrained by critical trade-offs: CNNs suffer from limited receptive fields, while ViTs grapple with quadratic computational complexity, hindering their scalability for high-resolution remote sensing data. State Space Models (SSMs), particularly the recently proposed Mamba architecture, have emerged as a paradigm-shifting solution, combining linear computational scaling with global context modeling. This survey presents a comprehensive review of Mamba-based methodologies in remote sensing, systematically analyzing about 120 studies to construct a holistic taxonomy of innovations and applications. Our contributions are structured across five dimensions: (i) foundational principles of vision Mamba architectures, (ii) micro-architectural advancements such as adaptive scan strategies and hybrid SSM formulations, (iii) macro-architectural integrations, including CNN-Transformer-Mamba hybrids and frequency-domain adaptations, (iv) rigorous benchmarking against state-of-the-art methods in multiple application tasks, such as object detection, semantic segmentation, change detection, etc. and (v) critical analysis of unresolved challenges with actionable future directions. By bridging the gap between SSM theory and remote sensing practice, this survey establishes Mamba as a transformative framework for remote sensing analysis. To our knowledge, this paper is the first systematic review of Mamba architectures in remote sensing. Our work provides a structured foundation for advancing research in remote sensing systems through SSM-based methods. We curate an open-source repository (https://github.com/BaoBao0926/Awesome-Mamba-in-Remote-Sensing) to foster community-driven advancements.
ASP-VMUNet: Atrous Shifted Parallel Vision Mamba U-Net for Skin Lesion Segmentation
Mar 25, 2025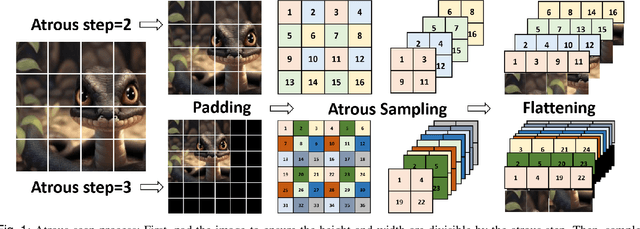
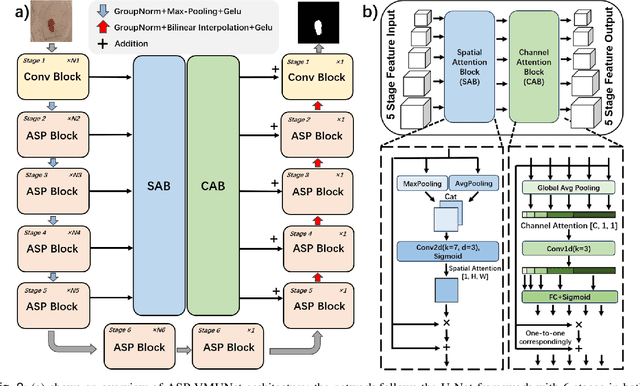
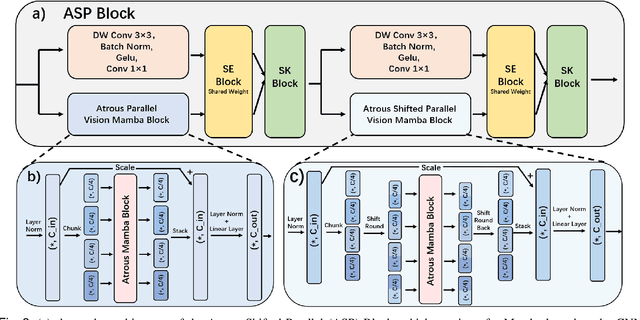
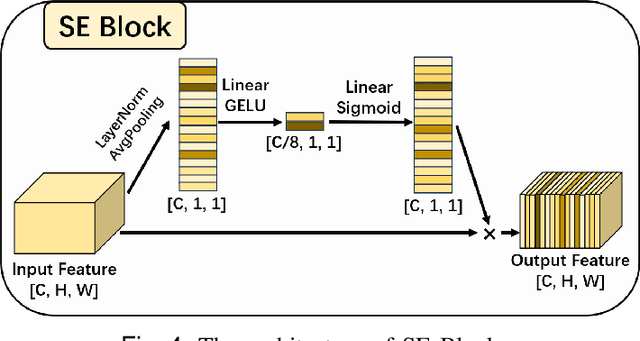
Skin lesion segmentation is a critical challenge in computer vision, and it is essential to separate pathological features from healthy skin for diagnostics accurately. Traditional Convolutional Neural Networks (CNNs) are limited by narrow receptive fields, and Transformers face significant computational burdens. This paper presents a novel skin lesion segmentation framework, the Atrous Shifted Parallel Vision Mamba UNet (ASP-VMUNet), which integrates the efficient and scalable Mamba architecture to overcome limitations in traditional CNNs and computationally demanding Transformers. The framework introduces an atrous scan technique that minimizes background interference and expands the receptive field, enhancing Mamba's scanning capabilities. Additionally, the inclusion of a Parallel Vision Mamba (PVM) layer and a shift round operation optimizes feature segmentation and fosters rich inter-segment information exchange. A supplementary CNN branch with a Selective-Kernel (SK) Block further refines the segmentation by blending local and global contextual information. Tested on four benchmark datasets (ISIC16/17/18 and PH2), ASP-VMUNet demonstrates superior performance in skin lesion segmentation, validated by comprehensive ablation studies. This approach not only advances medical image segmentation but also highlights the benefits of hybrid architectures in medical imaging technology. Our code is available at https://github.com/BaoBao0926/ASP-VMUNet/tree/main.
Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.