 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
Diff-OP3D: Bridging 2D Diffusion for Open Pose 3D Zero-Shot Classification
Dec 12, 2023With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, the methods via transferring Contrastive Language-Image Pre-training (CLIP) to 3D vision have made great progress in the 3D zero-shot classification task. However, these methods primarily focus on aligned pose 3D objects (ap-3os), overlooking the recognition of 3D objects with open poses (op-3os) typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more challenging benchmark for 3D open-pose zero-shot classification. Echoing our benchmark, we design a concise angle-refinement mechanism that automatically optimizes one ideal pose as well as classifies these op-3os. Furthermore, we make a first attempt to bridge 2D pre-trained diffusion model as a classifer to 3D zero-shot classification without any additional training. Such 2D diffusion to 3D objects proves vital in improving zero-shot classification for both ap-3os and op-3os. Our model notably improves by 3.5% and 15.8% on ModelNet10$^{\ddag}$ and McGill$^{\ddag}$ open pose benchmarks, respectively, and surpasses the current state-of-the-art by 6.8% on the aligned pose ModelNet10, affirming diffusion's efficacy in 3D zero-shot tasks.
Towards Deeper and Better Multi-view Feature Fusion for 3D Semantic Segmentation
Dec 13, 20223D point clouds are rich in geometric structure information, while 2D images contain important and continuous texture information. Combining 2D information to achieve better 3D semantic segmentation has become mainstream in 3D scene understanding. Albeit the success, it still remains elusive how to fuse and process the cross-dimensional features from these two distinct spaces. Existing state-of-the-art usually exploit bidirectional projection methods to align the cross-dimensional features and realize both 2D & 3D semantic segmentation tasks. However, to enable bidirectional mapping, this framework often requires a symmetrical 2D-3D network structure, thus limiting the network's flexibility. Meanwhile, such dual-task settings may distract the network easily and lead to over-fitting in the 3D segmentation task. As limited by the network's inflexibility, fused features can only pass through a decoder network, which affects model performance due to insufficient depth. To alleviate these drawbacks, in this paper, we argue that despite its simplicity, projecting unidirectionally multi-view 2D deep semantic features into the 3D space aligned with 3D deep semantic features could lead to better feature fusion. On the one hand, the unidirectional projection enforces our model focused more on the core task, i.e., 3D segmentation; on the other hand, unlocking the bidirectional to unidirectional projection enables a deeper cross-domain semantic alignment and enjoys the flexibility to fuse better and complicated features from very different spaces. In joint 2D-3D approaches, our proposed method achieves superior performance on the ScanNetv2 benchmark for 3D semantic segmentation.
Divide and Conquer: 3D Point Cloud Instance Segmentation With Point-Wise Binarization
Jul 22, 2022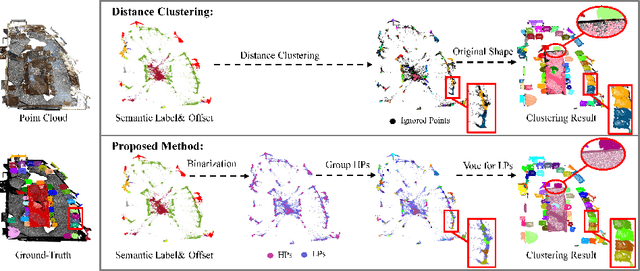
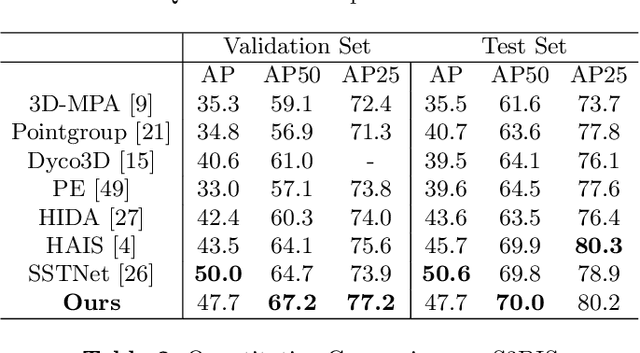
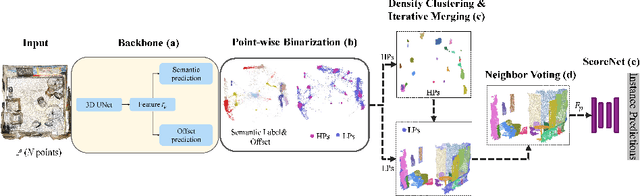
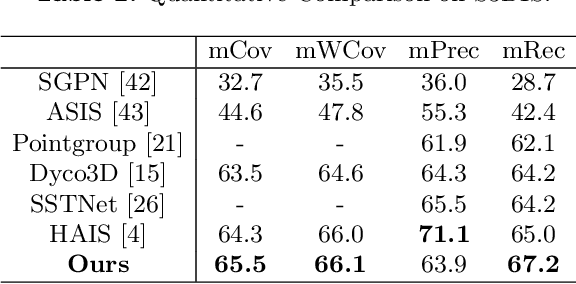
Instance segmentation on point clouds is crucially important for 3D scene understanding. Distance clustering is commonly used in state-of-the-art methods (SOTAs), which is typically effective but does not perform well in segmenting adjacent objects with the same semantic label (especially when they share neighboring points). Due to the uneven distribution of offset points, these existing methods can hardly cluster all instance points. To this end, we design a novel divide and conquer strategy and propose an end-to-end network named PBNet that binarizes each point and clusters them separately to segment instances. PBNet divides offset instance points into two categories: high and low density points (HPs vs.LPs), which are then conquered separately. Adjacent objects can be clearly separated by removing LPs, and then be completed and refined by assigning LPs via a neighbor voting method. To further reduce clustering errors, we develop an iterative merging algorithm based on mean size to aggregate fragment instances. Experiments on ScanNetV2 and S3DIS datasets indicate the superiority of our model. In particular, PBNet achieves so far the best AP50 and AP25 on the ScanNetV2 official benchmark challenge (Validation Set) while demonstrating high efficiency.
From 2D Images to 3D Model:Weakly Supervised Multi-View Face Reconstruction with Deep Fusion
Apr 08, 2022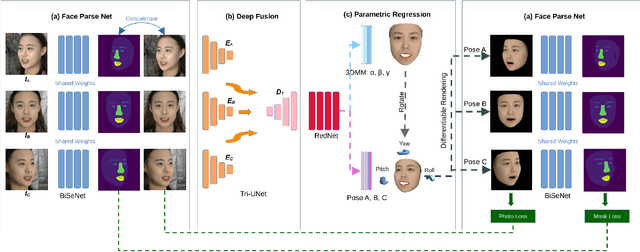

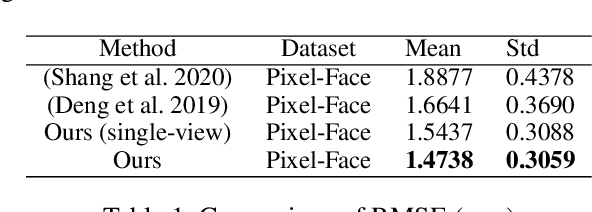
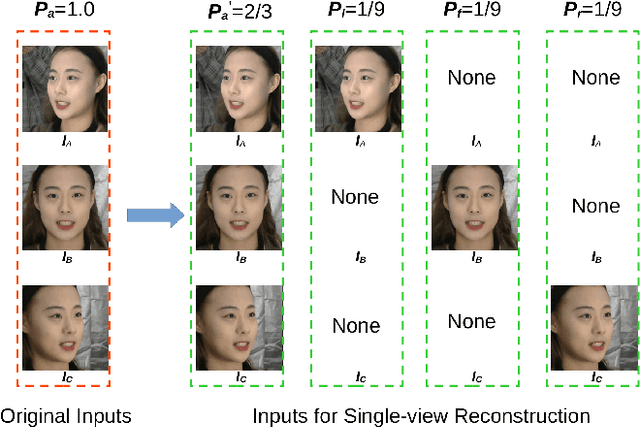
We consider the problem of Multi-view 3D Face Reconstruction (MVR) with weakly supervised learning that leverages a limited number of 2D face images (e.g. 3) to generate a high-quality 3D face model with very light annotation. Despite their encouraging performance, present MVR methods simply concatenate multi-view image features and pay less attention to critical areas (e.g. eye, brow, nose and mouth). To this end, we propose a novel model called Deep Fusion MVR (DF-MVR) and design a multi-view encoding to a single decoding framework with skip connections, able to extract, integrate, and compensate deep features with attention from multi-view images. In addition, we develop a multi-view face parse network to learn, identify, and emphasize the critical common face area. Finally, though our model is trained with a few 2D images, it can reconstruct an accurate 3D model even if one single 2D image is input. We conduct extensive experiments to evaluate various multi-view 3D face reconstruction methods. Our proposed model attains superior performance, leading to 11.4% RMSE improvement over the existing best weakly supervised MVRs. Source codes are available in the supplementary materials.