 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
PO3AD: Predicting Point Offsets toward Better 3D Point Cloud Anomaly Detection
Dec 17, 2024Point cloud anomaly detection under the anomaly-free setting poses significant challenges as it requires accurately capturing the features of 3D normal data to identify deviations indicative of anomalies. Current efforts focus on devising reconstruction tasks, such as acquiring normal data representations by restoring normal samples from altered, pseudo-anomalous counterparts. Our findings reveal that distributing attention equally across normal and pseudo-anomalous data tends to dilute the model's focus on anomalous deviations. The challenge is further compounded by the inherently disordered and sparse nature of 3D point cloud data. In response to those predicaments, we introduce an innovative approach that emphasizes learning point offsets, targeting more informative pseudo-abnormal points, thus fostering more effective distillation of normal data representations. We also have crafted an augmentation technique that is steered by normal vectors, facilitating the creation of credible pseudo anomalies that enhance the efficiency of the training process. Our comprehensive experimental evaluation on the Anomaly-ShapeNet and Real3D-AD datasets evidences that our proposed method outperforms existing state-of-the-art approaches, achieving an average enhancement of 9.0% and 1.4% in the AUC-ROC detection metric across these datasets, respectively.
Disentangling Tabular Data towards Better One-Class Anomaly Detection
Nov 12, 2024Tabular anomaly detection under the one-class classification setting poses a significant challenge, as it involves accurately conceptualizing "normal" derived exclusively from a single category to discern anomalies from normal data variations. Capturing the intrinsic correlation among attributes within normal samples presents one promising method for learning the concept. To do so, the most recent effort relies on a learnable mask strategy with a reconstruction task. However, this wisdom may suffer from the risk of producing uniform masks, i.e., essentially nothing is masked, leading to less effective correlation learning. To address this issue, we presume that attributes related to others in normal samples can be divided into two non-overlapping and correlated subsets, defined as CorrSets, to capture the intrinsic correlation effectively. Accordingly, we introduce an innovative method that disentangles CorrSets from normal tabular data. To our knowledge, this is a pioneering effort to apply the concept of disentanglement for one-class anomaly detection on tabular data. Extensive experiments on 20 tabular datasets show that our method substantially outperforms the state-of-the-art methods and leads to an average performance improvement of 6.1% on AUC-PR and 2.1% on AUC-ROC.
MathAttack: Attacking Large Language Models Towards Math Solving Ability
Sep 04, 2023With the boom of Large Language Models (LLMs), the research of solving Math Word Problem (MWP) has recently made great progress. However, there are few studies to examine the security of LLMs in math solving ability. Instead of attacking prompts in the use of LLMs, we propose a MathAttack model to attack MWP samples which are closer to the essence of security in solving math problems. Compared to traditional text adversarial attack, it is essential to preserve the mathematical logic of original MWPs during the attacking. To this end, we propose logical entity recognition to identify logical entries which are then frozen. Subsequently, the remaining text are attacked by adopting a word-level attacker. Furthermore, we propose a new dataset RobustMath to evaluate the robustness of LLMs in math solving ability. Extensive experiments on our RobustMath and two another math benchmark datasets GSM8K and MultiAirth show that MathAttack could effectively attack the math solving ability of LLMs. In the experiments, we observe that (1) Our adversarial samples from higher-accuracy LLMs are also effective for attacking LLMs with lower accuracy (e.g., transfer from larger to smaller-size LLMs, or from few-shot to zero-shot prompts); (2) Complex MWPs (such as more solving steps, longer text, more numbers) are more vulnerable to attack; (3) We can improve the robustness of LLMs by using our adversarial samples in few-shot prompts. Finally, we hope our practice and observation can serve as an important attempt towards enhancing the robustness of LLMs in math solving ability. We will release our code and dataset.
SaliencyCut: Augmenting Plausible Anomalies for Open-set Fine-Grained Anomaly Detection
Jun 14, 2023Open-set fine-grained anomaly detection is a challenging task that requires learning discriminative fine-grained features to detect anomalies that were even unseen during training. As a cheap yet effective approach, data augmentation has been widely used to create pseudo anomalies for better training of such models. Recent wisdom of augmentation methods focuses on generating random pseudo instances that may lead to a mixture of augmented instances with seen anomalies, or out of the typical range of anomalies. To address this issue, we propose a novel saliency-guided data augmentation method, SaliencyCut, to produce pseudo but more common anomalies which tend to stay in the plausible range of anomalies. Furthermore, we deploy a two-head learning strategy consisting of normal and anomaly learning heads, to learn the anomaly score of each sample. Theoretical analyses show that this mechanism offers a more tractable and tighter lower bound of the data log-likelihood. We then design a novel patch-wise residual module in the anomaly learning head to extract and assess the fine-grained anomaly features from each sample, facilitating the learning of discriminative representations of anomaly instances. Extensive experiments conducted on six real-world anomaly detection datasets demonstrate the superiority of our method to the baseline and other state-of-the-art methods under various settings.
Towards Deeper and Better Multi-view Feature Fusion for 3D Semantic Segmentation
Dec 13, 20223D point clouds are rich in geometric structure information, while 2D images contain important and continuous texture information. Combining 2D information to achieve better 3D semantic segmentation has become mainstream in 3D scene understanding. Albeit the success, it still remains elusive how to fuse and process the cross-dimensional features from these two distinct spaces. Existing state-of-the-art usually exploit bidirectional projection methods to align the cross-dimensional features and realize both 2D & 3D semantic segmentation tasks. However, to enable bidirectional mapping, this framework often requires a symmetrical 2D-3D network structure, thus limiting the network's flexibility. Meanwhile, such dual-task settings may distract the network easily and lead to over-fitting in the 3D segmentation task. As limited by the network's inflexibility, fused features can only pass through a decoder network, which affects model performance due to insufficient depth. To alleviate these drawbacks, in this paper, we argue that despite its simplicity, projecting unidirectionally multi-view 2D deep semantic features into the 3D space aligned with 3D deep semantic features could lead to better feature fusion. On the one hand, the unidirectional projection enforces our model focused more on the core task, i.e., 3D segmentation; on the other hand, unlocking the bidirectional to unidirectional projection enables a deeper cross-domain semantic alignment and enjoys the flexibility to fuse better and complicated features from very different spaces. In joint 2D-3D approaches, our proposed method achieves superior performance on the ScanNetv2 benchmark for 3D semantic segmentation.
Divide and Conquer: 3D Point Cloud Instance Segmentation With Point-Wise Binarization
Jul 22, 2022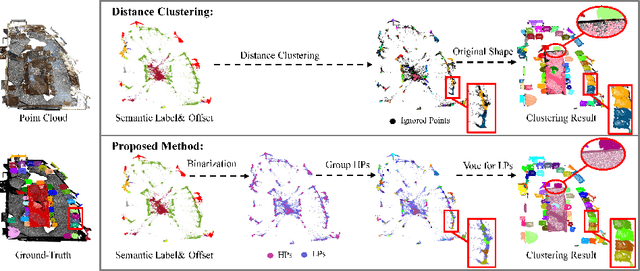
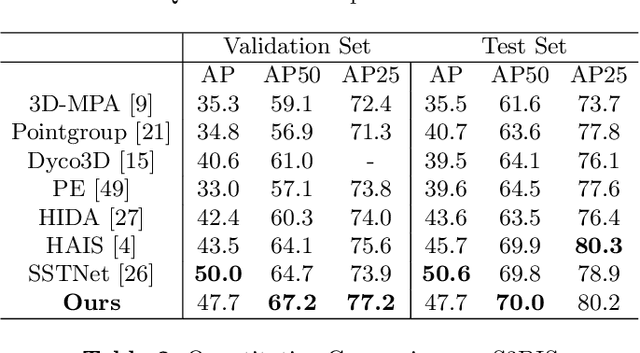
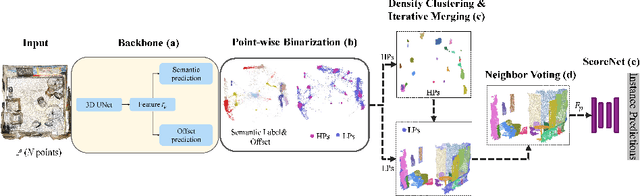
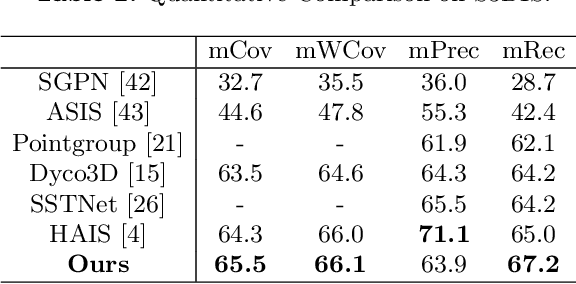
Instance segmentation on point clouds is crucially important for 3D scene understanding. Distance clustering is commonly used in state-of-the-art methods (SOTAs), which is typically effective but does not perform well in segmenting adjacent objects with the same semantic label (especially when they share neighboring points). Due to the uneven distribution of offset points, these existing methods can hardly cluster all instance points. To this end, we design a novel divide and conquer strategy and propose an end-to-end network named PBNet that binarizes each point and clusters them separately to segment instances. PBNet divides offset instance points into two categories: high and low density points (HPs vs.LPs), which are then conquered separately. Adjacent objects can be clearly separated by removing LPs, and then be completed and refined by assigning LPs via a neighbor voting method. To further reduce clustering errors, we develop an iterative merging algorithm based on mean size to aggregate fragment instances. Experiments on ScanNetV2 and S3DIS datasets indicate the superiority of our model. In particular, PBNet achieves so far the best AP50 and AP25 on the ScanNetV2 official benchmark challenge (Validation Set) while demonstrating high efficiency.
From 2D Images to 3D Model:Weakly Supervised Multi-View Face Reconstruction with Deep Fusion
Apr 08, 2022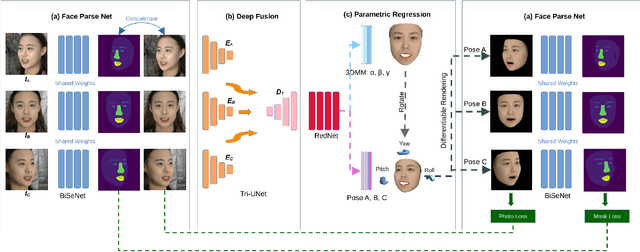

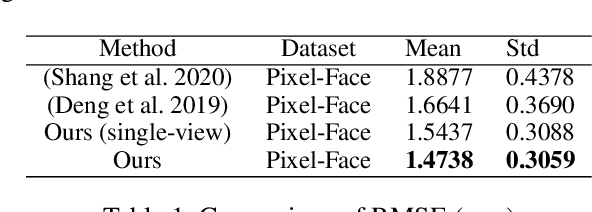
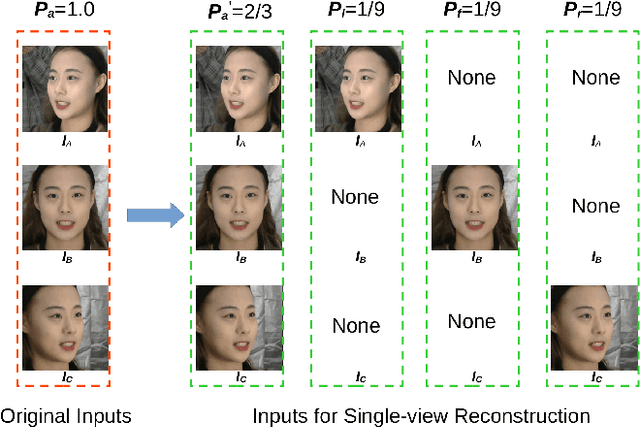
We consider the problem of Multi-view 3D Face Reconstruction (MVR) with weakly supervised learning that leverages a limited number of 2D face images (e.g. 3) to generate a high-quality 3D face model with very light annotation. Despite their encouraging performance, present MVR methods simply concatenate multi-view image features and pay less attention to critical areas (e.g. eye, brow, nose and mouth). To this end, we propose a novel model called Deep Fusion MVR (DF-MVR) and design a multi-view encoding to a single decoding framework with skip connections, able to extract, integrate, and compensate deep features with attention from multi-view images. In addition, we develop a multi-view face parse network to learn, identify, and emphasize the critical common face area. Finally, though our model is trained with a few 2D images, it can reconstruct an accurate 3D model even if one single 2D image is input. We conduct extensive experiments to evaluate various multi-view 3D face reconstruction methods. Our proposed model attains superior performance, leading to 11.4% RMSE improvement over the existing best weakly supervised MVRs. Source codes are available in the supplementary materials.