 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Guided Optimization for Uncertainty-Aware Medical Image Segmentation
Jan 27, 2026Uncertainty in medical image segmentation is inherently non-uniform, with boundary regions exhibiting substantially higher ambiguity than interior areas. Conventional training treats all pixels equally, leading to unstable optimization during early epochs when predictions are unreliable. We argue that this instability hinders convergence toward Pareto-optimal solutions and propose a region-wise curriculum strategy that prioritizes learning from certain regions and gradually incorporates uncertain ones, reducing gradient variance. Methodologically, we introduce a Pareto-consistent loss that balances trade-offs between regional uncertainties by adaptively reshaping the loss landscape and constraining convergence dynamics between interior and boundary regions; this guides the model toward Pareto-approximate solutions. To address boundary ambiguity, we further develop a fuzzy labeling mechanism that maintains binary confidence in non-boundary areas while enabling smooth transitions near boundaries, stabilizing gradients, and expanding flat regions in the loss surface. Experiments on brain metastasis and non-metastatic tumor segmentation show consistent improvements across multiple configurations, with our method outperforming traditional crisp-set approaches in all tumor subregions.
Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
Towards Training-Free Open-World Classification with 3D Generative Models
Jan 29, 2025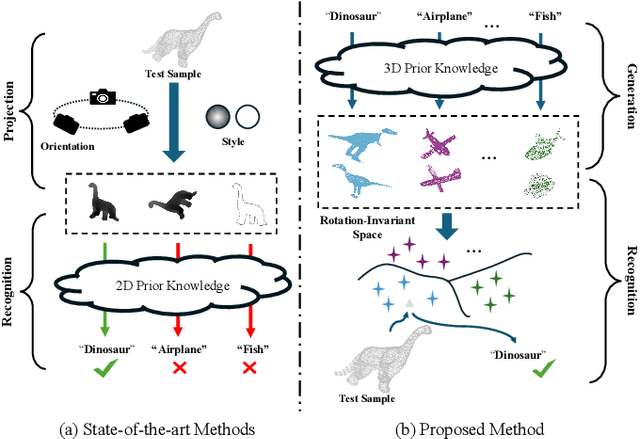
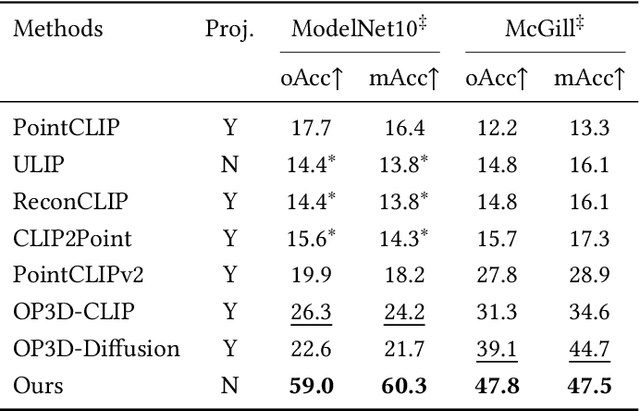
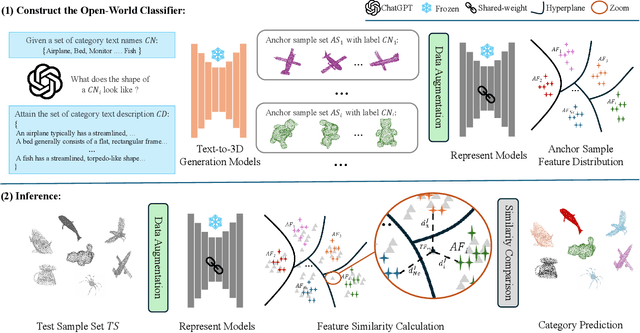

3D open-world classification is a challenging yet essential task in dynamic and unstructured real-world scenarios, requiring both open-category and open-pose recognition. To address these challenges, recent wisdom often takes sophisticated 2D pre-trained models to provide enriched and stable representations. However, these methods largely rely on how 3D objects can be projected into 2D space, which is unfortunately not well solved, and thus significantly limits their performance. Unlike these present efforts, in this paper we make a pioneering exploration of 3D generative models for 3D open-world classification. Drawing on abundant prior knowledge from 3D generative models, we additionally craft a rotation-invariant feature extractor. This innovative synergy endows our pipeline with the advantages of being training-free, open-category, and pose-invariant, thus well suited to 3D open-world classification. Extensive experiments on benchmark datasets demonstrate the potential of generative models in 3D open-world classification, achieving state-of-the-art performance on ModelNet10 and McGill with 32.0% and 8.7% overall accuracy improvement, respectively.
Computational Protein Science in the Era of Large Language Models (LLMs)
Jan 17, 2025



Considering the significance of proteins, computational protein science has always been a critical scientific field, dedicated to revealing knowledge and developing applications within the protein sequence-structure-function paradigm. In the last few decades, Artificial Intelligence (AI) has made significant impacts in computational protein science, leading to notable successes in specific protein modeling tasks. However, those previous AI models still meet limitations, such as the difficulty in comprehending the semantics of protein sequences, and the inability to generalize across a wide range of protein modeling tasks. Recently, LLMs have emerged as a milestone in AI due to their unprecedented language processing & generalization capability. They can promote comprehensive progress in fields rather than solving individual tasks. As a result, researchers have actively introduced LLM techniques in computational protein science, developing protein Language Models (pLMs) that skillfully grasp the foundational knowledge of proteins and can be effectively generalized to solve a diversity of sequence-structure-function reasoning problems. While witnessing prosperous developments, it's necessary to present a systematic overview of computational protein science empowered by LLM techniques. First, we summarize existing pLMs into categories based on their mastered protein knowledge, i.e., underlying sequence patterns, explicit structural and functional information, and external scientific languages. Second, we introduce the utilization and adaptation of pLMs, highlighting their remarkable achievements in promoting protein structure prediction, protein function prediction, and protein design studies. Then, we describe the practical application of pLMs in antibody design, enzyme design, and drug discovery. Finally, we specifically discuss the promising future directions in this fast-growing field.
Towards Cross-device and Training-free Robotic Grasping in 3D Open World
Nov 27, 2024Robotic grasping in the open world is a critical component of manufacturing and automation processes. While numerous existing approaches depend on 2D segmentation output to facilitate the grasping procedure, accurately determining depth from 2D imagery remains a challenge, often leading to limited performance in complex stacking scenarios. In contrast, techniques utilizing 3D point cloud data inherently capture depth information, thus enabling adeptly navigating and manipulating a diverse range of complex stacking scenes. However, such efforts are considerably hindered by the variance in data capture devices and the unstructured nature of the data, which limits their generalizability. Consequently, much research is narrowly concentrated on managing designated objects within specific settings, which confines their real-world applicability. This paper presents a novel pipeline capable of executing object grasping tasks in open-world scenarios even on previously unseen objects without the necessity for training. Additionally, our pipeline supports the flexible use of different 3D point cloud segmentation models across a variety of scenes. Leveraging the segmentation results, we propose to engage a training-free binary clustering algorithm that not only improves segmentation precision but also possesses the capability to cluster and localize unseen objects for executing grasping operations. In our experiments, we investigate a range of open-world scenarios, and the outcomes underscore the remarkable robustness and generalizability of our pipeline, consistent across various environments, robots, cameras, and objects. The code will be made available upon acceptance of the paper.
Diff-OP3D: Bridging 2D Diffusion for Open Pose 3D Zero-Shot Classification
Dec 12, 2023With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, the methods via transferring Contrastive Language-Image Pre-training (CLIP) to 3D vision have made great progress in the 3D zero-shot classification task. However, these methods primarily focus on aligned pose 3D objects (ap-3os), overlooking the recognition of 3D objects with open poses (op-3os) typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more challenging benchmark for 3D open-pose zero-shot classification. Echoing our benchmark, we design a concise angle-refinement mechanism that automatically optimizes one ideal pose as well as classifies these op-3os. Furthermore, we make a first attempt to bridge 2D pre-trained diffusion model as a classifer to 3D zero-shot classification without any additional training. Such 2D diffusion to 3D objects proves vital in improving zero-shot classification for both ap-3os and op-3os. Our model notably improves by 3.5% and 15.8% on ModelNet10$^{\ddag}$ and McGill$^{\ddag}$ open pose benchmarks, respectively, and surpasses the current state-of-the-art by 6.8% on the aligned pose ModelNet10, affirming diffusion's efficacy in 3D zero-shot tasks.
Towards Deeper and Better Multi-view Feature Fusion for 3D Semantic Segmentation
Dec 13, 20223D point clouds are rich in geometric structure information, while 2D images contain important and continuous texture information. Combining 2D information to achieve better 3D semantic segmentation has become mainstream in 3D scene understanding. Albeit the success, it still remains elusive how to fuse and process the cross-dimensional features from these two distinct spaces. Existing state-of-the-art usually exploit bidirectional projection methods to align the cross-dimensional features and realize both 2D & 3D semantic segmentation tasks. However, to enable bidirectional mapping, this framework often requires a symmetrical 2D-3D network structure, thus limiting the network's flexibility. Meanwhile, such dual-task settings may distract the network easily and lead to over-fitting in the 3D segmentation task. As limited by the network's inflexibility, fused features can only pass through a decoder network, which affects model performance due to insufficient depth. To alleviate these drawbacks, in this paper, we argue that despite its simplicity, projecting unidirectionally multi-view 2D deep semantic features into the 3D space aligned with 3D deep semantic features could lead to better feature fusion. On the one hand, the unidirectional projection enforces our model focused more on the core task, i.e., 3D segmentation; on the other hand, unlocking the bidirectional to unidirectional projection enables a deeper cross-domain semantic alignment and enjoys the flexibility to fuse better and complicated features from very different spaces. In joint 2D-3D approaches, our proposed method achieves superior performance on the ScanNetv2 benchmark for 3D semantic segmentation.
Towards Better Text-Image Consistency in Text-to-Image Generation
Oct 27, 2022

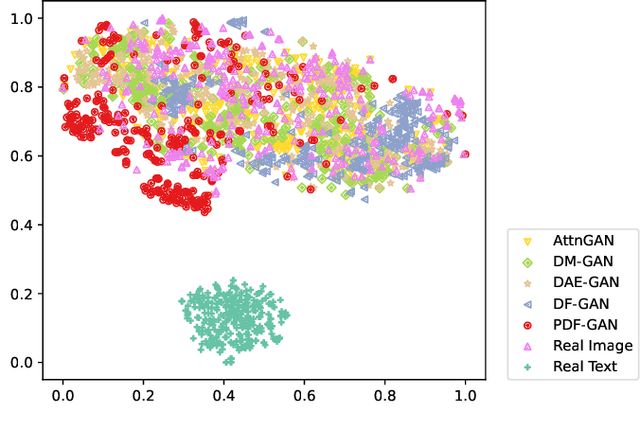
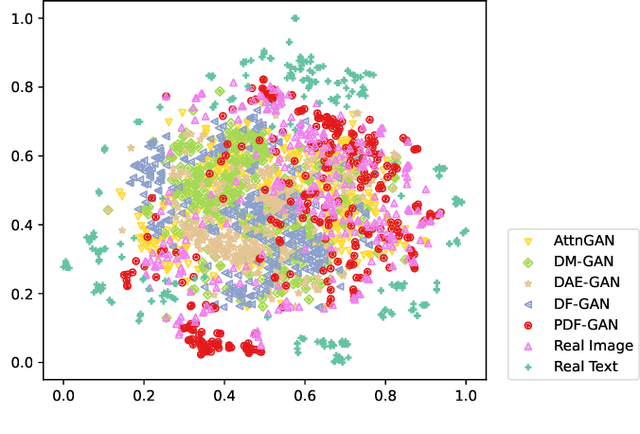
Generating consistent and high-quality images from given texts is essential for visual-language understanding. Although impressive results have been achieved in generating high-quality images, text-image consistency is still a major concern in existing GAN-based methods. Particularly, the most popular metric $R$-precision may not accurately reflect the text-image consistency, often resulting in very misleading semantics in the generated images. Albeit its significance, how to design a better text-image consistency metric surprisingly remains under-explored in the community. In this paper, we make a further step forward to develop a novel CLIP-based metric termed as Semantic Similarity Distance (SSD), which is both theoretically founded from a distributional viewpoint and empirically verified on benchmark datasets. Benefiting from the proposed metric, we further design the Parallel Deep Fusion Generative Adversarial Networks (PDF-GAN), which can fuse semantic information at different granularities and capture accurate semantics. Equipped with two novel plug-and-play components: Hard-Negative Sentence Constructor and Semantic Projection, the proposed PDF-GAN can mitigate inconsistent semantics and bridge the text-image semantic gap. A series of experiments show that, as opposed to current state-of-the-art methods, our PDF-GAN can lead to significantly better text-image consistency while maintaining decent image quality on the CUB and COCO datasets.
3D Random Occlusion and Multi-Layer Projection for Deep Multi-Camera Pedestrian Localization
Jul 25, 2022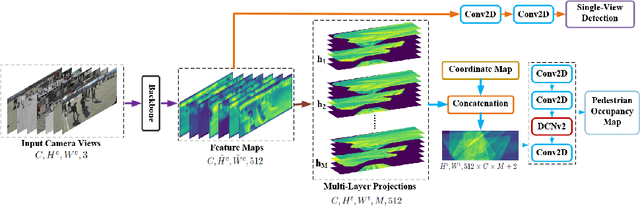

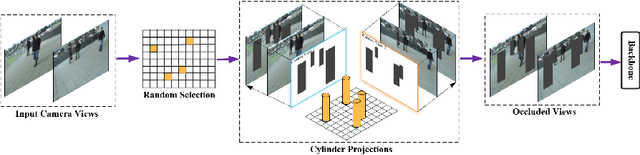
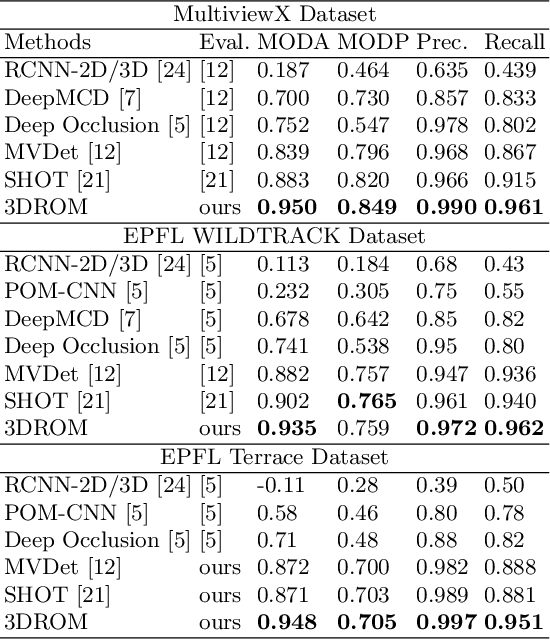
Although deep-learning based methods for monocular pedestrian detection have made great progress, they are still vulnerable to heavy occlusions. Using multi-view information fusion is a potential solution but has limited applications, due to the lack of annotated training samples in existing multi-view datasets, which increases the risk of overfitting. To address this problem, a data augmentation method is proposed to randomly generate 3D cylinder occlusions, on the ground plane, which are of the average size of pedestrians and projected to multiple views, to relieve the impact of overfitting in the training. Moreover, the feature map of each view is projected to multiple parallel planes at different heights, by using homographies, which allows the CNNs to fully utilize the features across the height of each pedestrian to infer the locations of pedestrians on the ground plane. The proposed 3DROM method has a greatly improved performance in comparison with the state-of-the-art deep-learning based methods for multi-view pedestrian detection.
Divide and Conquer: 3D Point Cloud Instance Segmentation With Point-Wise Binarization
Jul 22, 2022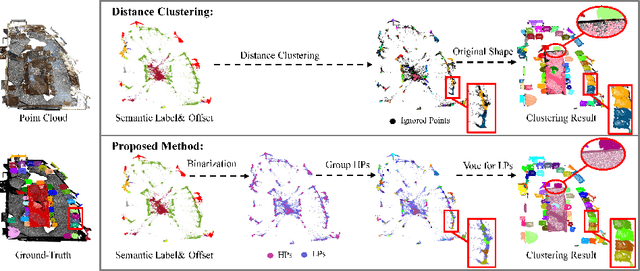
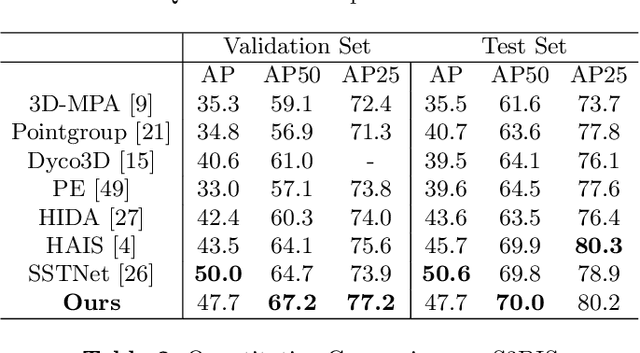
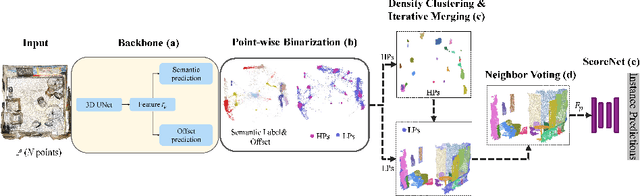
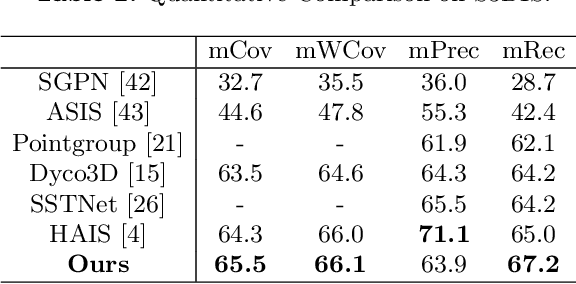
Instance segmentation on point clouds is crucially important for 3D scene understanding. Distance clustering is commonly used in state-of-the-art methods (SOTAs), which is typically effective but does not perform well in segmenting adjacent objects with the same semantic label (especially when they share neighboring points). Due to the uneven distribution of offset points, these existing methods can hardly cluster all instance points. To this end, we design a novel divide and conquer strategy and propose an end-to-end network named PBNet that binarizes each point and clusters them separately to segment instances. PBNet divides offset instance points into two categories: high and low density points (HPs vs.LPs), which are then conquered separately. Adjacent objects can be clearly separated by removing LPs, and then be completed and refined by assigning LPs via a neighbor voting method. To further reduce clustering errors, we develop an iterative merging algorithm based on mean size to aggregate fragment instances. Experiments on ScanNetV2 and S3DIS datasets indicate the superiority of our model. In particular, PBNet achieves so far the best AP50 and AP25 on the ScanNetV2 official benchmark challenge (Validation Set) while demonstrating high efficiency.