 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Detail-Preserved Completion of Complex Tubular Structures based on Point Cloud: a Dataset and a Benchmark
Aug 25, 2025



Complex tubular structures are essential in medical imaging and computer-assisted diagnosis, where their integrity enhances anatomical visualization and lesion detection. However, existing segmentation algorithms struggle with structural discontinuities, particularly in severe clinical cases such as coronary artery stenosis and vessel occlusions, which leads to undesired discontinuity and compromising downstream diagnostic accuracy. Therefore, it is imperative to reconnect discontinuous structures to ensure their completeness. In this study, we explore the tubular structure completion based on point cloud for the first time and establish a Point Cloud-based Coronary Artery Completion (PC-CAC) dataset, which is derived from real clinical data. This dataset provides a novel benchmark for tubular structure completion. Additionally, we propose TSRNet, a Tubular Structure Reconnection Network that integrates a detail-preservated feature extractor, a multiple dense refinement strategy, and a global-to-local loss function to ensure accurate reconnection while maintaining structural integrity. Comprehensive experiments on our PC-CAC and two additional public datasets (PC-ImageCAS and PC-PTR) demonstrate that our method consistently outperforms state-of-the-art approaches across multiple evaluation metrics, setting a new benchmark for point cloud-based tubular structure reconstruction. Our benchmark is available at https://github.com/YaoleiQi/PCCAC.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025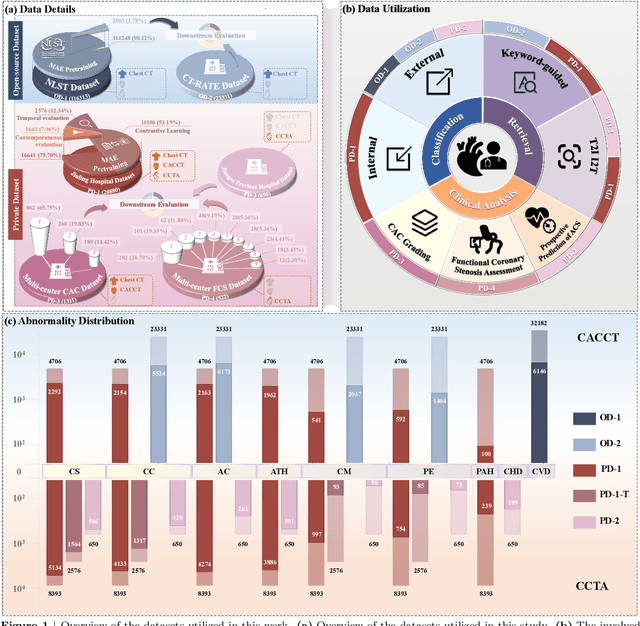
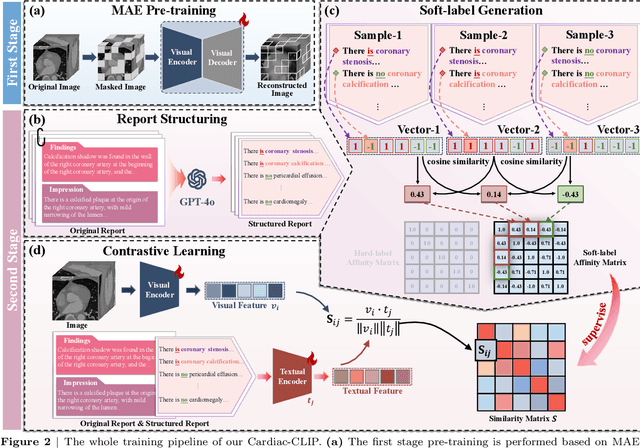
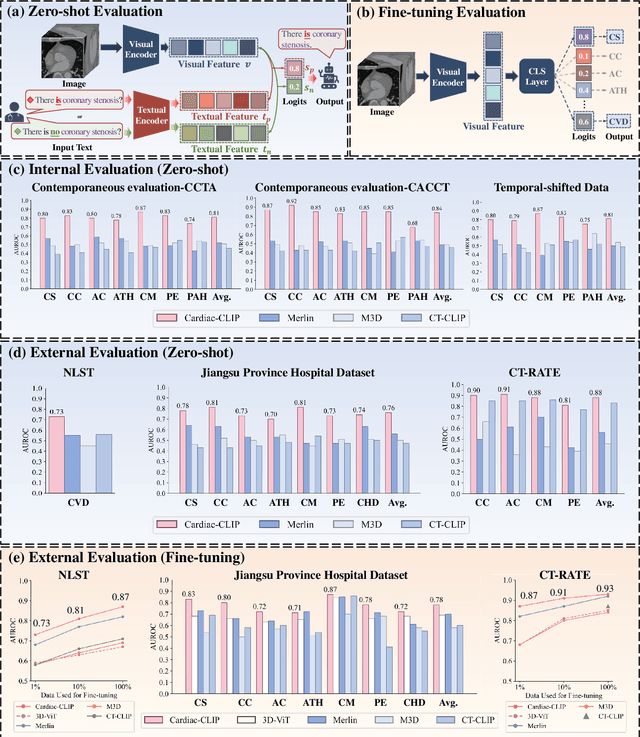
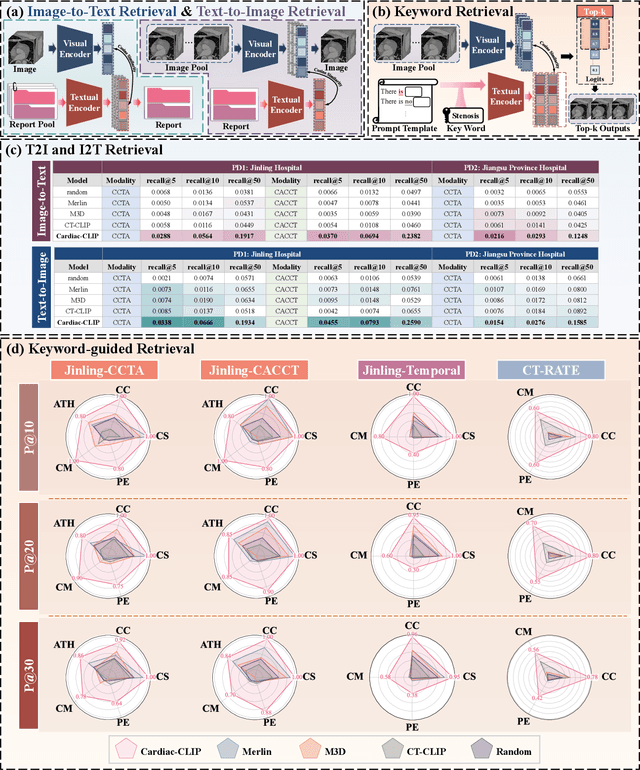
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
PathFL: Multi-Alignment Federated Learning for Pathology Image Segmentation
May 28, 2025Pathology image segmentation across multiple centers encounters significant challenges due to diverse sources of heterogeneity including imaging modalities, organs, and scanning equipment, whose variability brings representation bias and impedes the development of generalizable segmentation models. In this paper, we propose PathFL, a novel multi-alignment Federated Learning framework for pathology image segmentation that addresses these challenges through three-level alignment strategies of image, feature, and model aggregation. Firstly, at the image level, a collaborative style enhancement module aligns and diversifies local data by facilitating style information exchange across clients. Secondly, at the feature level, an adaptive feature alignment module ensures implicit alignment in the representation space by infusing local features with global insights, promoting consistency across heterogeneous client features learning. Finally, at the model aggregation level, a stratified similarity aggregation strategy hierarchically aligns and aggregates models on the server, using layer-specific similarity to account for client discrepancies and enhance global generalization. Comprehensive evaluations on four sets of heterogeneous pathology image datasets, encompassing cross-source, cross-modality, cross-organ, and cross-scanner variations, validate the effectiveness of our PathFL in achieving better performance and robustness against data heterogeneity.
Generative Models in Computational Pathology: A Comprehensive Survey on Methods, Applications, and Challenges
May 16, 2025Generative modeling has emerged as a promising direction in computational pathology, offering capabilities such as data-efficient learning, synthetic data augmentation, and multimodal representation across diverse diagnostic tasks. This review provides a comprehensive synthesis of recent progress in the field, organized into four key domains: image generation, text generation, multimodal image-text generation, and other generative applications, including spatial simulation and molecular inference. By analyzing over 150 representative studies, we trace the evolution of generative architectures from early generative adversarial networks to recent advances in diffusion models and foundation models with generative capabilities. We further examine the datasets and evaluation protocols commonly used in this domain and highlight ongoing limitations, including challenges in generating high-fidelity whole slide images, clinical interpretability, and concerns related to the ethical and legal implications of synthetic data. The review concludes with a discussion of open challenges and prospective research directions, with an emphasis on developing unified, multimodal, and clinically deployable generative systems. This work aims to provide a foundational reference for researchers and practitioners developing and applying generative models in computational pathology.
Dynamic Allocation Hypernetwork with Adaptive Model Recalibration for Federated Continual Learning
Mar 25, 2025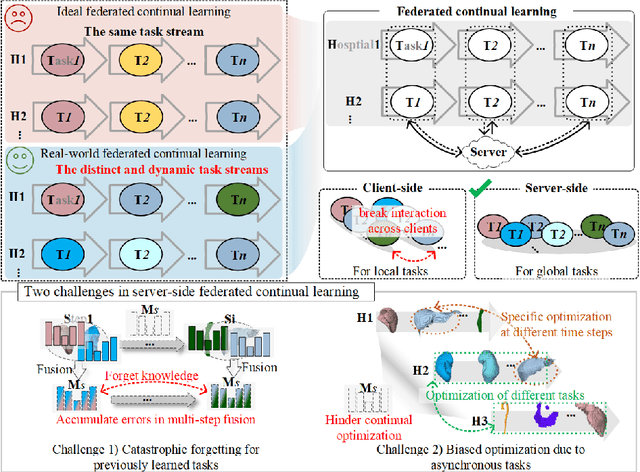

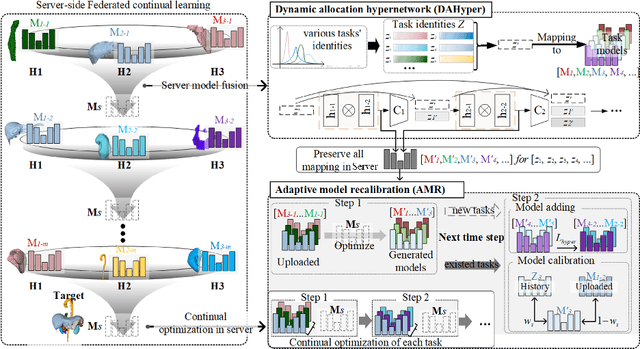

Federated continual learning (FCL) offers an emerging pattern to facilitate the applicability of federated learning (FL) in real-world scenarios, where tasks evolve dynamically and asynchronously across clients, especially in medical scenario. Existing server-side FCL methods in nature domain construct a continually learnable server model by client aggregation on all-involved tasks. However, they are challenged by: (1) Catastrophic forgetting for previously learned tasks, leading to error accumulation in server model, making it difficult to sustain comprehensive knowledge across all tasks. (2) Biased optimization due to asynchronous tasks handled across different clients, leading to the collision of optimization targets of different clients at the same time steps. In this work, we take the first step to propose a novel server-side FCL pattern in medical domain, Dynamic Allocation Hypernetwork with adaptive model recalibration (FedDAH). It is to facilitate collaborative learning under the distinct and dynamic task streams across clients. To alleviate the catastrophic forgetting, we propose a dynamic allocation hypernetwork (DAHyper) where a continually updated hypernetwork is designed to manage the mapping between task identities and their associated model parameters, enabling the dynamic allocation of the model across clients. For the biased optimization, we introduce a novel adaptive model recalibration (AMR) to incorporate the candidate changes of historical models into current server updates, and assign weights to identical tasks across different time steps based on the similarity for continual optimization. Extensive experiments on the AMOS dataset demonstrate the superiority of our FedDAH to other FCL methods on sites with different task streams. The code is available:https://github.com/jinlab-imvr/FedDAH.
FCaS: Fine-grained Cardiac Image Synthesis based on 3D Template Conditional Diffusion Model
Mar 12, 2025Solving medical imaging data scarcity through semantic image generation has attracted significant attention in recent years. However, existing methods primarily focus on generating whole-organ or large-tissue structures, showing limited effectiveness for organs with fine-grained structure. Due to stringent topological consistency, fragile coronary features, and complex 3D morphological heterogeneity in cardiac imaging, accurately reconstructing fine-grained anatomical details of the heart remains a great challenge. To address this problem, in this paper, we propose the Fine-grained Cardiac image Synthesis(FCaS) framework, established on 3D template conditional diffusion model. FCaS achieves precise cardiac structure generation using Template-guided Conditional Diffusion Model (TCDM) through bidirectional mechanisms, which provides the fine-grained topological structure information of target image through the guidance of template. Meanwhile, we design a deformable Mask Generation Module (MGM) to mitigate the scarcity of high-quality and diverse reference mask in the generation process. Furthermore, to alleviate the confusion caused by imprecise synthetic images, we propose a Confidence-aware Adaptive Learning (CAL) strategy to facilitate the pre-training of downstream segmentation tasks. Specifically, we introduce the Skip-Sampling Variance (SSV) estimation to obtain confidence maps, which are subsequently employed to rectify the pre-training on downstream tasks. Experimental results demonstrate that images generated from FCaS achieves state-of-the-art performance in topological consistency and visual quality, which significantly facilitates the downstream tasks as well. Code will be released in the future.
Homeomorphism Prior for False Positive and Negative Problem in Medical Image Dense Contrastive Representation Learning
Feb 07, 2025Dense contrastive representation learning (DCRL) has greatly improved the learning efficiency for image-dense prediction tasks, showing its great potential to reduce the large costs of medical image collection and dense annotation. However, the properties of medical images make unreliable correspondence discovery, bringing an open problem of large-scale false positive and negative (FP&N) pairs in DCRL. In this paper, we propose GEoMetric vIsual deNse sImilarity (GEMINI) learning which embeds the homeomorphism prior to DCRL and enables a reliable correspondence discovery for effective dense contrast. We propose a deformable homeomorphism learning (DHL) which models the homeomorphism of medical images and learns to estimate a deformable mapping to predict the pixels' correspondence under topological preservation. It effectively reduces the searching space of pairing and drives an implicit and soft learning of negative pairs via a gradient. We also propose a geometric semantic similarity (GSS) which extracts semantic information in features to measure the alignment degree for the correspondence learning. It will promote the learning efficiency and performance of deformation, constructing positive pairs reliably. We implement two practical variants on two typical representation learning tasks in our experiments. Our promising results on seven datasets which outperform the existing methods show our great superiority. We will release our code on a companion link: https://github.com/YutingHe-list/GEMINI.
Towards Training-Free Open-World Classification with 3D Generative Models
Jan 29, 2025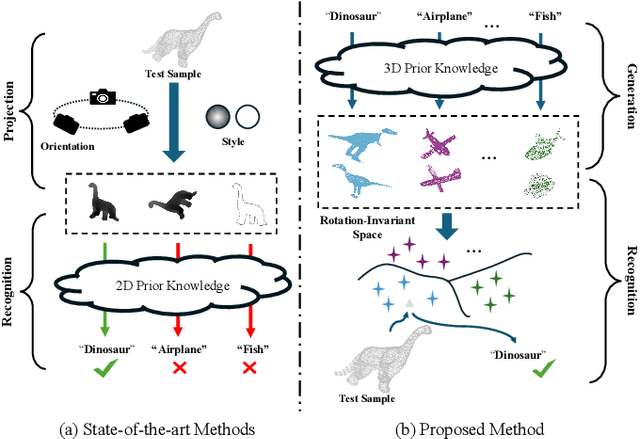
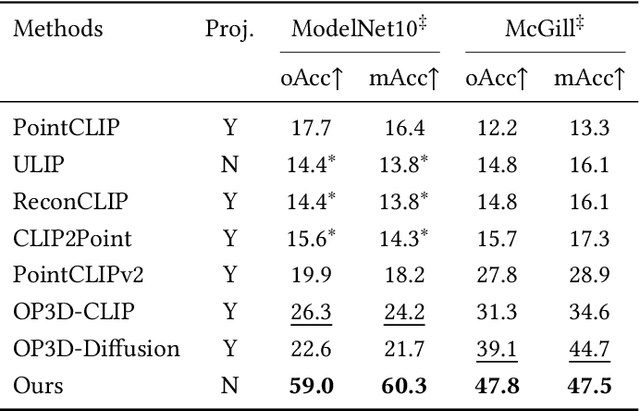
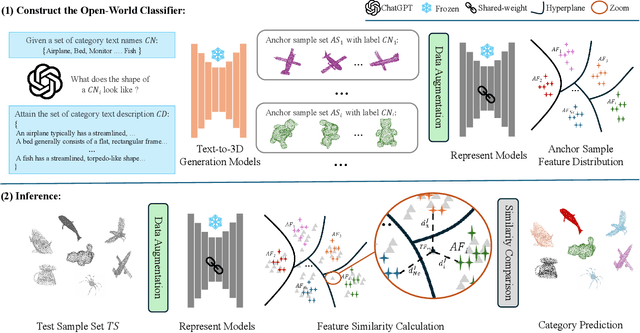

3D open-world classification is a challenging yet essential task in dynamic and unstructured real-world scenarios, requiring both open-category and open-pose recognition. To address these challenges, recent wisdom often takes sophisticated 2D pre-trained models to provide enriched and stable representations. However, these methods largely rely on how 3D objects can be projected into 2D space, which is unfortunately not well solved, and thus significantly limits their performance. Unlike these present efforts, in this paper we make a pioneering exploration of 3D generative models for 3D open-world classification. Drawing on abundant prior knowledge from 3D generative models, we additionally craft a rotation-invariant feature extractor. This innovative synergy endows our pipeline with the advantages of being training-free, open-category, and pose-invariant, thus well suited to 3D open-world classification. Extensive experiments on benchmark datasets demonstrate the potential of generative models in 3D open-world classification, achieving state-of-the-art performance on ModelNet10 and McGill with 32.0% and 8.7% overall accuracy improvement, respectively.
Covariance-based Space Regularization for Few-shot Class Incremental Learning
Nov 02, 2024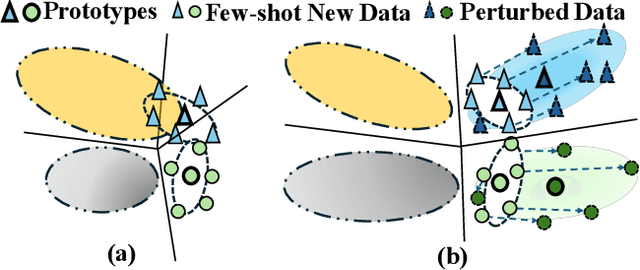
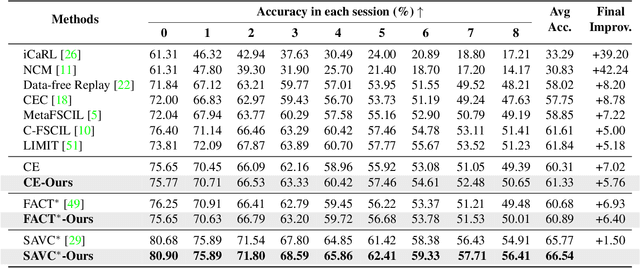
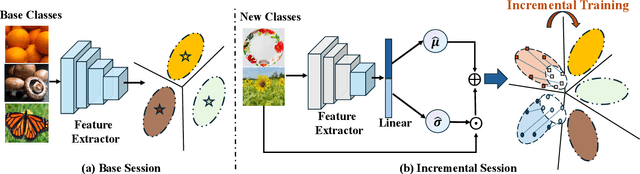
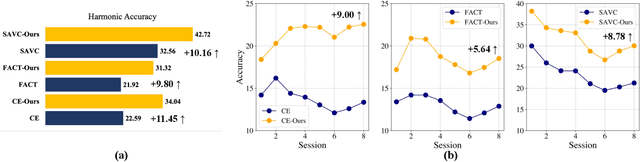
Few-shot Class Incremental Learning (FSCIL) presents a challenging yet realistic scenario, which requires the model to continually learn new classes with limited labeled data (i.e., incremental sessions) while retaining knowledge of previously learned base classes (i.e., base sessions). Due to the limited data in incremental sessions, models are prone to overfitting new classes and suffering catastrophic forgetting of base classes. To tackle these issues, recent advancements resort to prototype-based approaches to constrain the base class distribution and learn discriminative representations of new classes. Despite the progress, the limited data issue still induces ill-divided feature space, leading the model to confuse the new class with old classes or fail to facilitate good separation among new classes. In this paper, we aim to mitigate these issues by directly constraining the span of each class distribution from a covariance perspective. In detail, we propose a simple yet effective covariance constraint loss to force the model to learn each class distribution with the same covariance matrix. In addition, we propose a perturbation approach to perturb the few-shot training samples in the feature space, which encourages the samples to be away from the weighted distribution of other classes. Regarding perturbed samples as new class data, the classifier is forced to establish explicit boundaries between each new class and the existing ones. Our approach is easy to integrate into existing FSCIL approaches to boost performance. Experiments on three benchmarks validate the effectiveness of our approach, achieving a new state-of-the-art performance of FSCIL.
DSCENet: Dynamic Screening and Clinical-Enhanced Multimodal Fusion for MPNs Subtype Classification
Jul 11, 2024
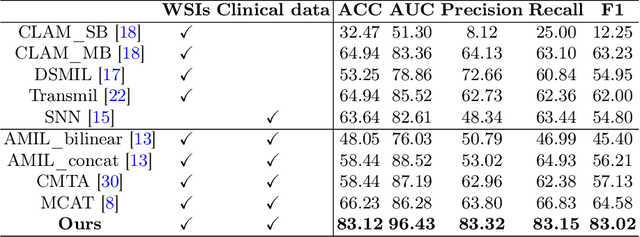


The precise subtype classification of myeloproliferative neoplasms (MPNs) based on multimodal information, which assists clinicians in diagnosis and long-term treatment plans, is of great clinical significance. However, it remains a great challenging task due to the lack of diagnostic representativeness for local patches and the absence of diagnostic-relevant features from a single modality. In this paper, we propose a Dynamic Screening and Clinical-Enhanced Network (DSCENet) for the subtype classification of MPNs on the multimodal fusion of whole slide images (WSIs) and clinical information. (1) A dynamic screening module is proposed to flexibly adapt the feature learning of local patches, reducing the interference of irrelevant features and enhancing their diagnostic representativeness. (2) A clinical-enhanced fusion module is proposed to integrate clinical indicators to explore complementary features across modalities, providing comprehensive diagnostic information. Our approach has been validated on the real clinical data, achieving an increase of 7.91% AUC and 16.89% accuracy compared with the previous state-of-the-art (SOTA) methods. The code is available at https://github.com/yuanzhang7/DSCENet.