 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRNeRV: A Scale-wise Recursive Framework for Neural Video Representation
Mar 09, 2026Implicit Neural Representations (INRs) have emerged as a promising paradigm for video representation and compression. However, existing multi-scale INR generators often suffer from significant parameter redundancy by stacking independent processing blocks for each scale. Inspired by the principle of scale self-similarity in the generation process, we propose SRNeRV, a novel scale-wise recursive framework that replaces this stacked design with a parameter-efficient shared architecture. The core of our approach is a hybrid sharing scheme derived from decoupling the processing block into a scale-specific spatial mixing module and a scale-invariant channel mixing module. We recursively apply the same shared channel mixing module, which contains the majority of the parameters, across all scales, significantly reducing the model size while preserving the crucial capacity to learn scale-specific spatial patterns. Extensive experiments demonstrate that SRNeRV achieves a significant rate-distortion performance boost, especially in INR-friendly scenarios, validating that our sharing scheme successfully amplifies the core strengths of the INR paradigm.
Video Compression with Hierarchical Temporal Neural Representation
Jan 25, 2026Video compression has recently benefited from implicit neural representations (INRs), which model videos as continuous functions. INRs offer compact storage and flexible reconstruction, providing a promising alternative to traditional codecs. However, most existing INR-based methods treat the temporal dimension as an independent input, limiting their ability to capture complex temporal dependencies. To address this, we propose a Hierarchical Temporal Neural Representation for Videos, TeNeRV. TeNeRV integrates short- and long-term dependencies through two key components. First, an Inter-Frame Feature Fusion (IFF) module aggregates features from adjacent frames, enforcing local temporal coherence and capturing fine-grained motion. Second, a GoP-Adaptive Modulation (GAM) mechanism partitions videos into Groups-of-Pictures and learns group-specific priors. The mechanism modulates network parameters, enabling adaptive representations across different GoPs. Extensive experiments demonstrate that TeNeRV consistently outperforms existing INR-based methods in rate-distortion performance, validating the effectiveness of our proposed approach.
Frequency-aware Neural Representation for Videos
Jan 25, 2026Implicit Neural Representations (INRs) have emerged as a promising paradigm for video compression. However, existing INR-based frameworks typically suffer from inherent spectral bias, which favors low-frequency components and leads to over-smoothed reconstructions and suboptimal rate-distortion performance. In this paper, we propose FaNeRV, a Frequency-aware Neural Representation for videos, which explicitly decouples low- and high-frequency components to enable efficient and faithful video reconstruction. FaNeRV introduces a multi-resolution supervision strategy that guides the network to progressively capture global structures and fine-grained textures through staged supervision . To further enhance high-frequency reconstruction, we propose a dynamic high-frequency injection mechanism that adaptively emphasizes challenging regions. In addition, we design a frequency-decomposed network module to improve feature modeling across different spectral bands. Extensive experiments on standard benchmarks demonstrate that FaNeRV significantly outperforms state-of-the-art INR methods and achieves competitive rate-distortion performance against traditional codecs.
MSNeRV: Neural Video Representation with Multi-Scale Feature Fusion
Jun 18, 2025Implicit Neural representations (INRs) have emerged as a promising approach for video compression, and have achieved comparable performance to the state-of-the-art codecs such as H.266/VVC. However, existing INR-based methods struggle to effectively represent detail-intensive and fast-changing video content. This limitation mainly stems from the underutilization of internal network features and the absence of video-specific considerations in network design. To address these challenges, we propose a multi-scale feature fusion framework, MSNeRV, for neural video representation. In the encoding stage, we enhance temporal consistency by employing temporal windows, and divide the video into multiple Groups of Pictures (GoPs), where a GoP-level grid is used for background representation. Additionally, we design a multi-scale spatial decoder with a scale-adaptive loss function to integrate multi-resolution and multi-frequency information. To further improve feature extraction, we introduce a multi-scale feature block that fully leverages hidden features. We evaluate MSNeRV on HEVC ClassB and UVG datasets for video representation and compression. Experimental results demonstrate that our model exhibits superior representation capability among INR-based approaches and surpasses VTM-23.7 (Random Access) in dynamic scenarios in terms of compression efficiency.
Generative Models in Computational Pathology: A Comprehensive Survey on Methods, Applications, and Challenges
May 16, 2025Generative modeling has emerged as a promising direction in computational pathology, offering capabilities such as data-efficient learning, synthetic data augmentation, and multimodal representation across diverse diagnostic tasks. This review provides a comprehensive synthesis of recent progress in the field, organized into four key domains: image generation, text generation, multimodal image-text generation, and other generative applications, including spatial simulation and molecular inference. By analyzing over 150 representative studies, we trace the evolution of generative architectures from early generative adversarial networks to recent advances in diffusion models and foundation models with generative capabilities. We further examine the datasets and evaluation protocols commonly used in this domain and highlight ongoing limitations, including challenges in generating high-fidelity whole slide images, clinical interpretability, and concerns related to the ethical and legal implications of synthetic data. The review concludes with a discussion of open challenges and prospective research directions, with an emphasis on developing unified, multimodal, and clinically deployable generative systems. This work aims to provide a foundational reference for researchers and practitioners developing and applying generative models in computational pathology.
UAR-NVC: A Unified AutoRegressive Framework for Memory-Efficient Neural Video Compression
Mar 04, 2025Implicit Neural Representations (INRs) have demonstrated significant potential in video compression by representing videos as neural networks. However, as the number of frames increases, the memory consumption for training and inference increases substantially, posing challenges in resource-constrained scenarios. Inspired by the success of traditional video compression frameworks, which process video frame by frame and can efficiently compress long videos, we adopt this modeling strategy for INRs to decrease memory consumption, while aiming to unify the frameworks from the perspective of timeline-based autoregressive modeling. In this work, we present a novel understanding of INR models from an autoregressive (AR) perspective and introduce a Unified AutoRegressive Framework for memory-efficient Neural Video Compression (UAR-NVC). UAR-NVC integrates timeline-based and INR-based neural video compression under a unified autoregressive paradigm. It partitions videos into several clips and processes each clip using a different INR model instance, leveraging the advantages of both compression frameworks while allowing seamless adaptation to either in form. To further reduce temporal redundancy between clips, we design two modules to optimize the initialization, training, and compression of these model parameters. UAR-NVC supports adjustable latencies by varying the clip length. Extensive experimental results demonstrate that UAR-NVC, with its flexible video clip setting, can adapt to resource-constrained environments and significantly improve performance compared to different baseline models.
Spatial Degradation-Aware and Temporal Consistent Diffusion Model for Compressed Video Super-Resolution
Feb 12, 2025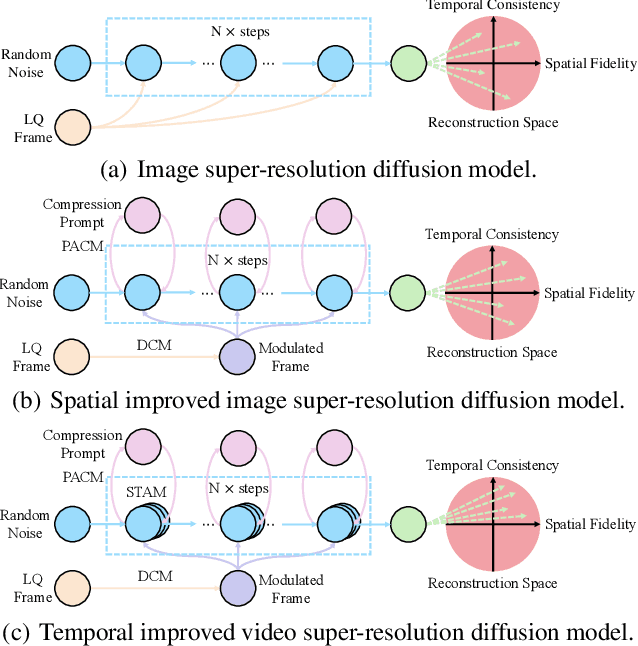
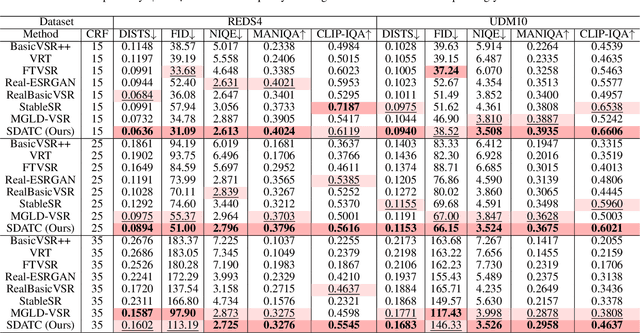
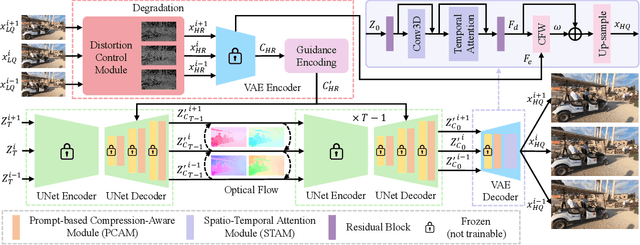
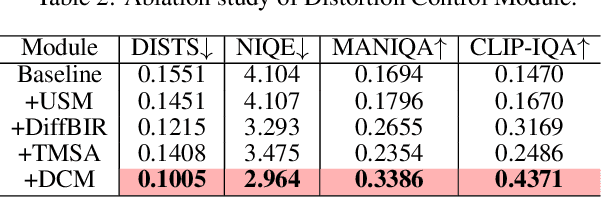
Due to limitations of storage and bandwidth, videos stored and transmitted on the Internet are usually low-quality with low-resolution and compression noise. Although video super-resolution (VSR) is an efficient technique to enhance video resolution, relatively VSR methods focus on compressed videos. Directly applying general VSR approaches leads to the failure of improving practical videos, especially when frames are highly compressed at a low bit rate. Recently, diffusion models have achieved superior performance in low-level visual tasks, and their high-realism generation capability enables them to be applied in VSR. To synthesize more compression-lost details and refine temporal consistency, we propose a novel Spatial Degradation-Aware and Temporal Consistent (SDATC) diffusion model for compressed VSR. Specifically, we introduce a distortion Control module (DCM) to modulate diffusion model inputs and guide the generation. Next, the diffusion model executes the denoising process for texture generation with fine-tuned spatial prompt-based compression-aware module (PCAM) and spatio-temporal attention module (STAM). PCAM extracts features to encode specific compression information dynamically. STAM extends the spatial attention mechanism to a spatio-temporal dimension for capturing temporal correlation. Extensive experimental results on benchmark datasets demonstrate the effectiveness of the proposed modules in enhancing compressed videos.
CANeRV: Content Adaptive Neural Representation for Video Compression
Feb 10, 2025


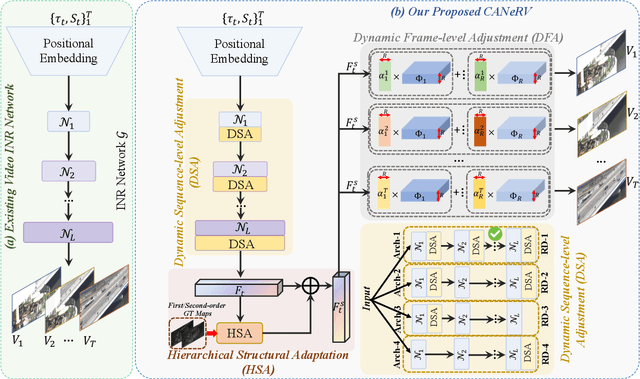
Recent advances in video compression introduce implicit neural representation (INR) based methods, which effectively capture global dependencies and characteristics of entire video sequences. Unlike traditional and deep learning based approaches, INR-based methods optimize network parameters from a global perspective, resulting in superior compression potential. However, most current INR methods utilize a fixed and uniform network architecture across all frames, limiting their adaptability to dynamic variations within and between video sequences. This often leads to suboptimal compression outcomes as these methods struggle to capture the distinct nuances and transitions in video content. To overcome these challenges, we propose Content Adaptive Neural Representation for Video Compression (CANeRV), an innovative INR-based video compression network that adaptively conducts structure optimisation based on the specific content of each video sequence. To better capture dynamic information across video sequences, we propose a dynamic sequence-level adjustment (DSA). Furthermore, to enhance the capture of dynamics between frames within a sequence, we implement a dynamic frame-level adjustment (DFA). {Finally, to effectively capture spatial structural information within video frames, thereby enhancing the detail restoration capabilities of CANeRV, we devise a structure level hierarchical structural adaptation (HSA).} Experimental results demonstrate that CANeRV can outperform both H.266/VVC and state-of-the-art INR-based video compression techniques across diverse video datasets.
Predicting Satisfied User and Machine Ratio for Compressed Images: A Unified Approach
Dec 23, 2024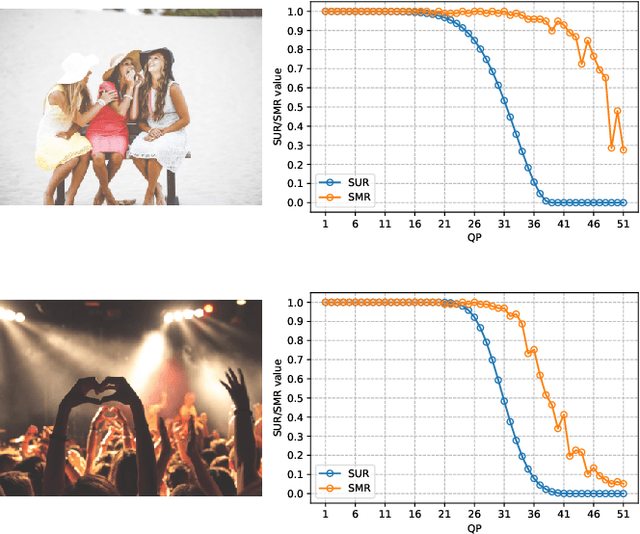
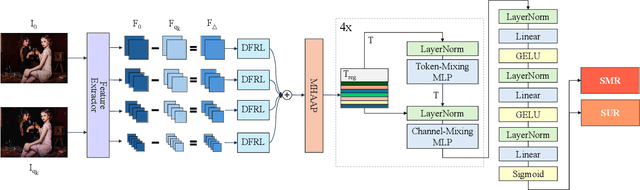
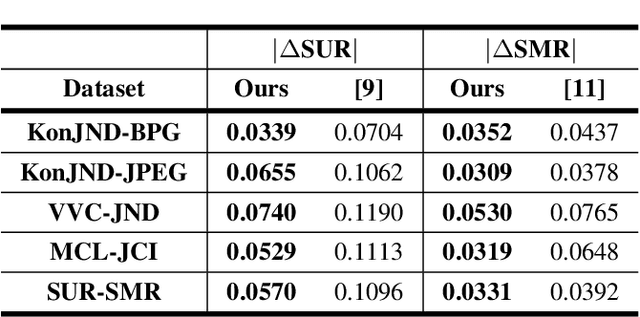
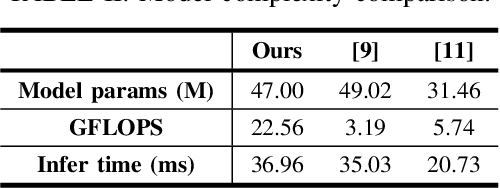
Nowadays, high-quality images are pursued by both humans for better viewing experience and by machines for more accurate visual analysis. However, images are usually compressed before being consumed, decreasing their quality. It is meaningful to predict the perceptual quality of compressed images for both humans and machines, which guides the optimization for compression. In this paper, we propose a unified approach to address this. Specifically, we create a deep learning-based model to predict Satisfied User Ratio (SUR) and Satisfied Machine Ratio (SMR) of compressed images simultaneously. We first pre-train a feature extractor network on a large-scale SMR-annotated dataset with human perception-related quality labels generated by diverse image quality models, which simulates the acquisition of SUR labels. Then, we propose an MLP-Mixer-based network to predict SUR and SMR by leveraging and fusing the extracted multi-layer features. We introduce a Difference Feature Residual Learning (DFRL) module to learn more discriminative difference features. We further use a Multi-Head Attention Aggregation and Pooling (MHAAP) layer to aggregate difference features and reduce their redundancy. Experimental results indicate that the proposed model significantly outperforms state-of-the-art SUR and SMR prediction methods. Moreover, our joint learning scheme of human and machine perceptual quality prediction tasks is effective at improving the performance of both.
Spatio-Temporal Distortion Aware Omnidirectional Video Super-Resolution
Oct 15, 2024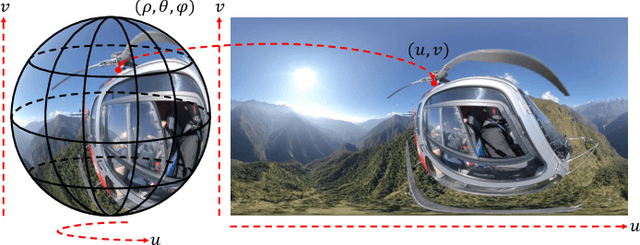


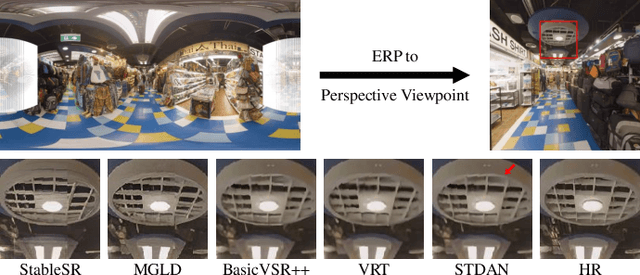
Omnidirectional video (ODV) can provide an immersive experience and is widely utilized in the field of virtual reality and augmented reality. However, the restricted capturing devices and transmission bandwidth lead to the low resolution of ODVs. Video super-resolution (VSR) methods are proposed to enhance the resolution of videos, but ODV projection distortions in the application are not well addressed directly applying such methods. To achieve better super-resolution reconstruction quality, we propose a novel Spatio-Temporal Distortion Aware Network (STDAN) oriented to ODV characteristics. Specifically, a spatio-temporal distortion modulation module is introduced to improve spatial ODV projection distortions and exploit the temporal correlation according to intra and inter alignments. Next, we design a multi-frame reconstruction and fusion mechanism to refine the consistency of reconstructed ODV frames. Furthermore, we incorporate latitude-saliency adaptive maps in the loss function to concentrate on important viewpoint regions with higher texture complexity and human-watching interest. In addition, we collect a new ODV-SR dataset with various scenarios. Extensive experimental results demonstrate that the proposed STDAN achieves superior super-resolution performance on ODVs and outperforms state-of-the-art methods.