 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Latent Collaborative Decoding for Fidelity-Perception Balanced Image Compression
May 14, 2026Learned image compression (LIC) increasingly requires reconstructions that balance distortion fidelity and perceptual realism across a wide range of bitrates. However, most existing methods still rely on a single compressed latent representation to simultaneously carry structural details, semantic cues, and perceptual priors, requiring the same latent representation to serve multiple, potentially conflicting roles. This tension becomes evident across different latent paradigms: scalar-quantized (SQ) continuous latents provide rate-scalable fidelity but tend to lose perceptual details at low rates, while vector-quantized (VQ) discrete tokens preserve compact semantic cues but suffer from limited structural fidelity and bitrate scalability. To address this issue, we propose Mixture of Decoder Experts (MoDE), a dual-latent collaborative decoding framework that decomposes reconstruction responsibilities across complementary latent paradigms. Specifically, MoDE treats the SQ branch as a fidelity-oriented expert and the VQ branch as a perception-oriented expert, and coordinates them through two decoder-side modules: Expert-Specific Enhancement (ESE), which preserves branch-specific expert references, and Cross-Expert Modulation (CEM), which enables selective complementary transfer during reconstruction. The resulting framework supports selective cross-latent collaboration under a shared dual-stream bitstream and enables both fidelity-anchored and perception-anchored decoding. Extensive experiments demonstrate that MoDE achieves a more favorable fidelity-perception balance than representative distortion-oriented, perception-oriented, generative, and dual-latent baselines across a wide bitrate range, highlighting decoder-side expert collaboration as an effective design for wide-range fidelity-perception balanced LIC.
Neural Video Compression with Domain Transfer
May 13, 2026Content-adaptive compression has always been a key direction in neural video coding (NVC), aiming to mitigate the domain gap between training and testing data. Such gaps often arise from distributional discrepancies between training and inference data, which may cause noticeable performance degradation when the testing content differs from the training distribution. To tackle this challenge, we propose DCVC-DT, a domain transfer enhanced neural video compression framework. Specifically, we design a lightweight online domain transfer (DT) mechanism that dynamically adapts the encoded latent representation during inference, effectively bridging the domain gap without modifying the encoder or decoder parameters. In addition, we develop a frame-level dynamic RD (Rate and Distortion) adjustment scheme that actively regulates the ratio of R and D in the loss function based on quality fluctuation, thereby improving rate-distortion performance. Extensive experiments demonstrate that DCVC-DT achieves up to 6.21% bitrate savings over the baseline DCVC-DC, while significantly enhancing generalization to unseen testing data and alleviating error propagation. Our code is available at https://github.com/SunnyMass/DCVC-DT.
HarmoWAM: Harmonizing Generalizable and Precise Manipulation via Adaptive World Action Models
May 11, 2026World Action Models (WAMs) have emerged as a promising paradigm for robot control by modeling physical dynamics. Current WAMs generally follow two paradigms: the "Imagine-then-Execute" approach, which uses video prediction to infer actions via inverse dynamics, and the "Joint Modeling" approach, which jointly models actions and video representations. Based on systematic experiments, we observe a fundamental trade-off between these paradigms: the former explicitly leverages world models for generalizable transit but lacks interaction precision, whereas the latter enables fine-grained, temporally coherent action generation but is constrained by the exploration space of the training distribution. Motivated by these findings, we propose HarmoWAM, an end-to-end WAM that fully leverages a world model to unify predictive and reactive control, enabling both generalizable transit and precise manipulation. Specifically, the world model provides spatio-temporal physical priors that condition two complementary action experts: a predictive expert that leverages latent dynamics for iterative action generation, and a reactive expert that directly infers actions from predicted visual evolution. To enable adaptive coordination, a Process-Adaptive Gating Mechanism is proposed to automatically determine the timing and location of switching between them. This allows the world model to drive the reactive expert to expand the exploration space and the predictive expert to perform precise interactions across different stages of a task. For evaluation, we construct three training-unseen test environments across six real-world robotic tasks, covering variations in background, position, and object semantics. Notably, HarmoWAM achieves strong zero-shot generalization across these scenarios, significantly outperforming prior state-of-the-art VLA models and WAMs by margins of 33% and 29%, respectively.
Spark3R: Asymmetric Token Reduction Makes Fast Feed-Forward 3D Reconstruction
May 07, 2026Feed-forward 3D reconstruction models based on Vision Transformers can directly estimate scene geometry and camera poses from a small set of input images, but scaling them to video inputs with hundreds or thousands of frames remains challenging due to the quadratic cost of global attention layers. Recent token-merging methods accelerate these models by compressing the token sequence within the global attention layers, but they apply a uniform reduction to query tokens and key-value tokens, ignoring their functionally distinct roles in 3D reconstruction. In this work, we identify a key property of feed-forward 3D reconstruction models: query tokens encode view-specific geometric requests and are sensitive to compression, while key-value tokens represent shared scene context and tolerate aggressive compression. Guided by this insight, we propose Spark3R, a training-free acceleration framework that decouples the compression of query tokens and key-value tokens by assigning distinct reduction factors, with intra-group token merging applied to query tokens and lightweight token pruning to key-value tokens. Additionally, Spark3R adaptively adjusts the key-value reduction factor across layers, further improving the quality-efficiency trade-off. As a plug-and-play framework requiring no retraining, Spark3R integrates directly into multiple pretrained feed-forward 3D reconstruction models, including VGGT, $π^3$, and Depth-Anything-3, and achieves up to $28\times$ speedup on 1,000-frame inputs while maintaining competitive reconstruction quality.
Parallax to Align Them All: An OmniParallax Attention Mechanism for Distributed Multi-View Image Compression
Mar 04, 2026Multi-view image compression (MIC) aims to achieve high compression efficiency by exploiting inter-image correlations, playing a crucial role in 3D applications. As a subfield of MIC, distributed multi-view image compression (DMIC) offers performance comparable to MIC while eliminating the need for inter-view information at the encoder side. However, existing methods in DMIC typically treat all images equally, overlooking the varying degrees of correlation between different views during decoding, which leads to suboptimal coding performance. To address this limitation, we propose a novel $\textbf{OmniParallax Attention Mechanism}$ (OPAM), which is a general mechanism for explicitly modeling correlations and aligned features between arbitrary pairs of information sources. Building upon OPAM, we propose a Parallax Multi Information Fusion Module (PMIFM) to adaptively integrate information from different sources. PMIFM is incorporated into both the joint decoder and the entropy model to construct our end-to-end DMIC framework, $\textbf{ParaHydra}$. Extensive experiments demonstrate that $\textbf{ParaHydra}$ is $\textbf{the first DMIC method}$ to significantly surpass state-of-the-art MIC codecs, while maintaining low computational overhead. Performance gains become more pronounced as the number of input views increases. Compared with LDMIC, $\textbf{ParaHydra}$ achieves bitrate savings of $\textbf{19.72%}$ on WildTrack(3) and up to $\textbf{24.18%}$ on WildTrack(6), while significantly improving coding efficiency (as much as $\textbf{65}\times$ in decoding and $\textbf{34}\times$ in encoding).
Content Adaptive based Motion Alignment Framework for Learned Video Compression
Dec 15, 2025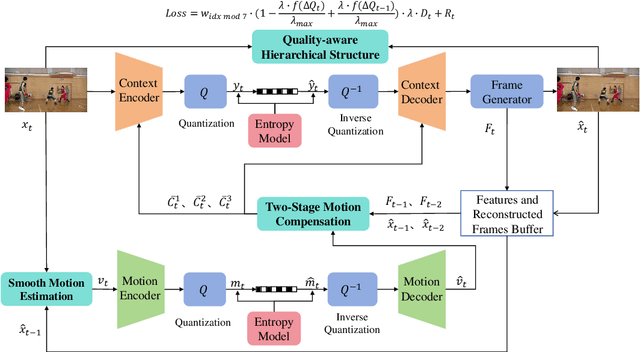

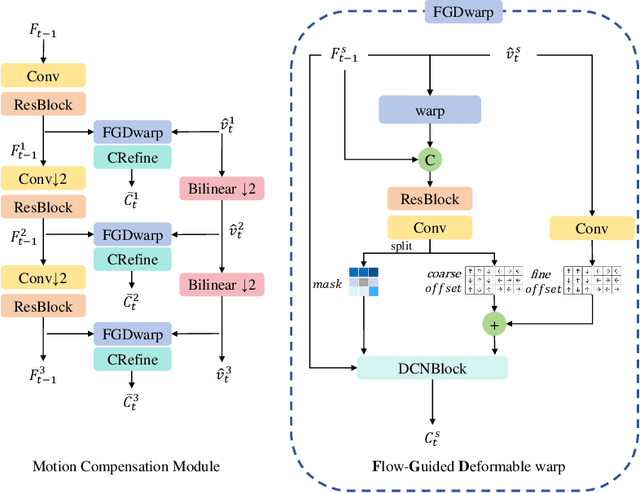
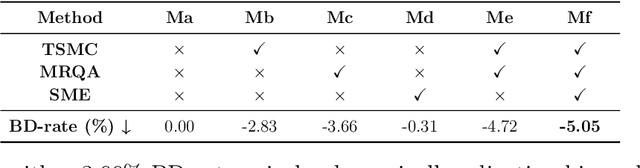
Recent advances in end-to-end video compression have shown promising results owing to their unified end-to-end learning optimization. However, such generalized frameworks often lack content-specific adaptation, leading to suboptimal compression performance. To address this, this paper proposes a content adaptive based motion alignment framework that improves performance by adapting encoding strategies to diverse content characteristics. Specifically, we first introduce a two-stage flow-guided deformable warping mechanism that refines motion compensation with coarse-to-fine offset prediction and mask modulation, enabling precise feature alignment. Second, we propose a multi-reference quality aware strategy that adjusts distortion weights based on reference quality, and applies it to hierarchical training to reduce error propagation. Third, we integrate a training-free module that downsamples frames by motion magnitude and resolution to obtain smooth motion estimation. Experimental results on standard test datasets demonstrate that our framework CAMA achieves significant improvements over state-of-the-art Neural Video Compression models, achieving a 24.95% BD-rate (PSNR) savings over our baseline model DCVC-TCM, while also outperforming reproduced DCVC-DC and traditional codec HM-16.25.
L-STEC: Learned Video Compression with Long-term Spatio-Temporal Enhanced Context
Dec 14, 2025Neural Video Compression has emerged in recent years, with condition-based frameworks outperforming traditional codecs. However, most existing methods rely solely on the previous frame's features to predict temporal context, leading to two critical issues. First, the short reference window misses long-term dependencies and fine texture details. Second, propagating only feature-level information accumulates errors over frames, causing prediction inaccuracies and loss of subtle textures. To address these, we propose the Long-term Spatio-Temporal Enhanced Context (L-STEC) method. We first extend the reference chain with LSTM to capture long-term dependencies. We then incorporate warped spatial context from the pixel domain, fusing spatio-temporal information through a multi-receptive field network to better preserve reference details. Experimental results show that L-STEC significantly improves compression by enriching contextual information, achieving 37.01% bitrate savings in PSNR and 31.65% in MS-SSIM compared to DCVC-TCM, outperforming both VTM-17.0 and DCVC-FM and establishing new state-of-the-art performance.
MoCo: Motion-Consistent Human Video Generation via Structure-Appearance Decoupling
Aug 24, 2025Generating human videos with consistent motion from text prompts remains a significant challenge, particularly for whole-body or long-range motion. Existing video generation models prioritize appearance fidelity, resulting in unrealistic or physically implausible human movements with poor structural coherence. Additionally, most existing human video datasets primarily focus on facial or upper-body motions, or consist of vertically oriented dance videos, limiting the scope of corresponding generation methods to simple movements. To overcome these challenges, we propose MoCo, which decouples the process of human video generation into two components: structure generation and appearance generation. Specifically, our method first employs an efficient 3D structure generator to produce a human motion sequence from a text prompt. The remaining video appearance is then synthesized under the guidance of the generated structural sequence. To improve fine-grained control over sparse human structures, we introduce Human-Aware Dynamic Control modules and integrate dense tracking constraints during training. Furthermore, recognizing the limitations of existing datasets, we construct a large-scale whole-body human video dataset featuring complex and diverse motions. Extensive experiments demonstrate that MoCo outperforms existing approaches in generating realistic and structurally coherent human videos.
TinySplat: Feedforward Approach for Generating Compact 3D Scene Representation
Jun 11, 2025



The recent development of feedforward 3D Gaussian Splatting (3DGS) presents a new paradigm to reconstruct 3D scenes. Using neural networks trained on large-scale multi-view datasets, it can directly infer 3DGS representations from sparse input views. Although the feedforward approach achieves high reconstruction speed, it still suffers from the substantial storage cost of 3D Gaussians. Existing 3DGS compression methods relying on scene-wise optimization are not applicable due to architectural incompatibilities. To overcome this limitation, we propose TinySplat, a complete feedforward approach for generating compact 3D scene representations. Built upon standard feedforward 3DGS methods, TinySplat integrates a training-free compression framework that systematically eliminates key sources of redundancy. Specifically, we introduce View-Projection Transformation (VPT) to reduce geometric redundancy by projecting geometric parameters into a more compact space. We further present Visibility-Aware Basis Reduction (VABR), which mitigates perceptual redundancy by aligning feature energy along dominant viewing directions via basis transformation. Lastly, spatial redundancy is addressed through an off-the-shelf video codec. Comprehensive experimental results on multiple benchmark datasets demonstrate that TinySplat achieves over 100x compression for 3D Gaussian data generated by feedforward methods. Compared to the state-of-the-art compression approach, we achieve comparable quality with only 6% of the storage size. Meanwhile, our compression framework requires only 25% of the encoding time and 1% of the decoding time.
ProSplat: Improved Feed-Forward 3D Gaussian Splatting for Wide-Baseline Sparse Views
Jun 09, 2025Feed-forward 3D Gaussian Splatting (3DGS) has recently demonstrated promising results for novel view synthesis (NVS) from sparse input views, particularly under narrow-baseline conditions. However, its performance significantly degrades in wide-baseline scenarios due to limited texture details and geometric inconsistencies across views. To address these challenges, in this paper, we propose ProSplat, a two-stage feed-forward framework designed for high-fidelity rendering under wide-baseline conditions. The first stage involves generating 3D Gaussian primitives via a 3DGS generator. In the second stage, rendered views from these primitives are enhanced through an improvement model. Specifically, this improvement model is based on a one-step diffusion model, further optimized by our proposed Maximum Overlap Reference view Injection (MORI) and Distance-Weighted Epipolar Attention (DWEA). MORI supplements missing texture and color by strategically selecting a reference view with maximum viewpoint overlap, while DWEA enforces geometric consistency using epipolar constraints. Additionally, we introduce a divide-and-conquer training strategy that aligns data distributions between the two stages through joint optimization. We evaluate ProSplat on the RealEstate10K and DL3DV-10K datasets under wide-baseline settings. Experimental results demonstrate that ProSplat achieves an average improvement of 1 dB in PSNR compared to recent SOTA methods.