 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic High-frequency Convolution for Infrared Small Target Detection
Feb 03, 2026Infrared small targets are typically tiny and locally salient, which belong to high-frequency components (HFCs) in images. Single-frame infrared small target (SIRST) detection is challenging, since there are many HFCs along with targets, such as bright corners, broken clouds, and other clutters. Current learning-based methods rely on the powerful capabilities of deep networks, but neglect explicit modeling and discriminative representation learning of various HFCs, which is important to distinguish targets from other HFCs. To address the aforementioned issues, we propose a dynamic high-frequency convolution (DHiF) to translate the discriminative modeling process into the generation of a dynamic local filter bank. Especially, DHiF is sensitive to HFCs, owing to the dynamic parameters of its generated filters being symmetrically adjusted within a zero-centered range according to Fourier transformation properties. Combining with standard convolution operations, DHiF can adaptively and dynamically process different HFC regions and capture their distinctive grayscale variation characteristics for discriminative representation learning. DHiF functions as a drop-in replacement for standard convolution and can be used in arbitrary SIRST detection networks without significant decrease in computational efficiency. To validate the effectiveness of our DHiF, we conducted extensive experiments across different SIRST detection networks on real-scene datasets. Compared to other state-of-the-art convolution operations, DHiF exhibits superior detection performance with promising improvement. Codes are available at https://github.com/TinaLRJ/DHiF.
Compressed Domain Prior-Guided Video Super-Resolution for Cloud Gaming Content
Jan 03, 2025Cloud gaming is an advanced form of Internet service that necessitates local terminals to decode within limited resources and time latency. Super-Resolution (SR) techniques are often employed on these terminals as an efficient way to reduce the required bit-rate bandwidth for cloud gaming. However, insufficient attention has been paid to SR of compressed game video content. Most SR networks amplify block artifacts and ringing effects in decoded frames while ignoring edge details of game content, leading to unsatisfactory reconstruction results. In this paper, we propose a novel lightweight network called Coding Prior-Guided Super-Resolution (CPGSR) to address the SR challenges in compressed game video content. First, we design a Compressed Domain Guided Block (CDGB) to extract features of different depths from coding priors, which are subsequently integrated with features from the U-net backbone. Then, a series of re-parameterization blocks are utilized for reconstruction. Ultimately, inspired by the quantization in video coding, we propose a partitioned focal frequency loss to effectively guide the model's focus on preserving high-frequency information. Extensive experiments demonstrate the advancement of our approach.
Constructing accurate machine-learned potentials and performing highly efficient atomistic simulations to predict structural and thermal properties
Nov 16, 2024



The $\text{Cu}_7\text{P}\text{S}_6$ compound has garnered significant attention due to its potential in thermoelectric applications. In this study, we introduce a neuroevolution potential (NEP), trained on a dataset generated from ab initio molecular dynamics (AIMD) simulations, using the moment tensor potential (MTP) as a reference. The low root mean square errors (RMSEs) for total energy and atomic forces demonstrate the high accuracy and transferability of both the MTP and NEP. We further calculate the phonon density of states (DOS) and radial distribution function (RDF) using both machine learning potentials, comparing the results to density functional theory (DFT) calculations. While the MTP potential offers slightly higher accuracy, the NEP achieves a remarkable 41-fold increase in computational speed. These findings provide detailed microscopic insights into the dynamics and rapid Cu-ion diffusion, paving the way for future studies on Cu-based solid electrolytes and their applications in energy devices.
TransCouplet:Transformer based Chinese Couplet Generation
Dec 03, 2021



Chinese couplet is a special form of poetry composed of complex syntax with ancient Chinese language. Due to the complexity of semantic and grammatical rules, creation of a suitable couplet is a formidable challenge. This paper presents a transformer-based sequence-to-sequence couplet generation model. With the utilization of AnchiBERT, the model is able to capture ancient Chinese language understanding. Moreover, we evaluate the Glyph, PinYin and Part-of-Speech tagging on the couplet grammatical rules to further improve the model.
Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark
Nov 25, 2021
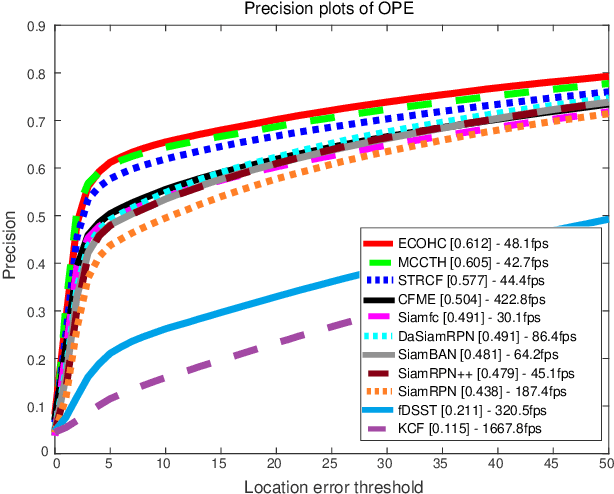
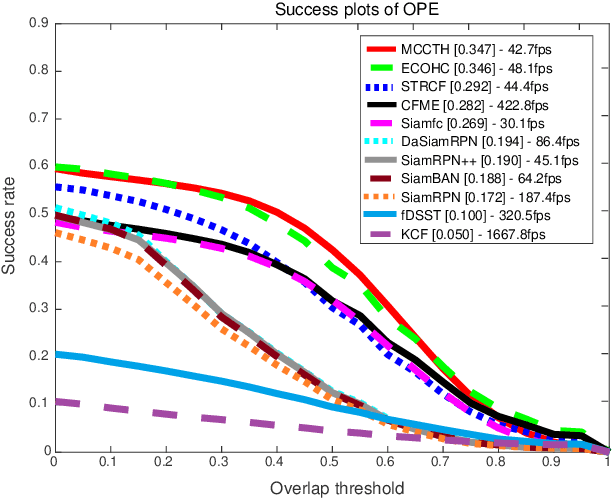

Satellite video cameras can provide continuous observation for a large-scale area, which is important for many remote sensing applications. However, achieving moving object detection and tracking in satellite videos remains challenging due to the insufficient appearance information of objects and lack of high-quality datasets. In this paper, we first build a large-scale satellite video dataset with rich annotations for the task of moving object detection and tracking. This dataset is collected by the Jilin-1 satellite constellation and composed of 47 high-quality videos with 1,646,038 instances of interest for object detection and 3,711 trajectories for object tracking. We then introduce a motion modeling baseline to improve the detection rate and reduce false alarms based on accumulative multi-frame differencing and robust matrix completion. Finally, we establish the first public benchmark for moving object detection and tracking in satellite videos, and extensively evaluate the performance of several representative approaches on our dataset. Comprehensive experimental analyses and insightful conclusions are also provided. The dataset is available at https://github.com/QingyongHu/VISO.
Lossless Point Cloud Attribute Compression with Normal-based Intra Prediction
Jun 23, 2021
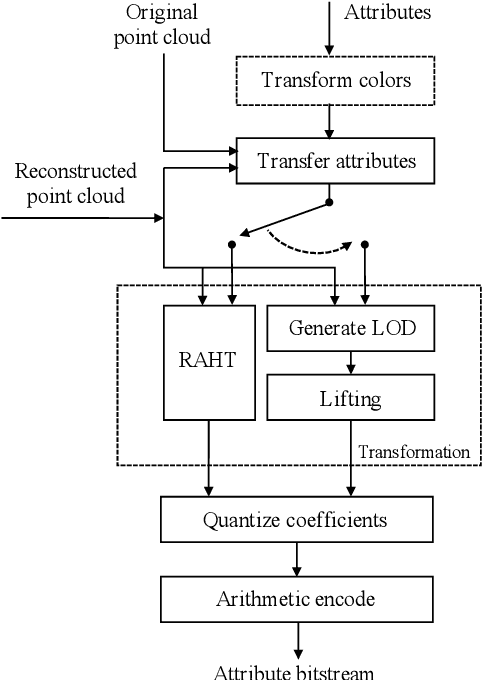
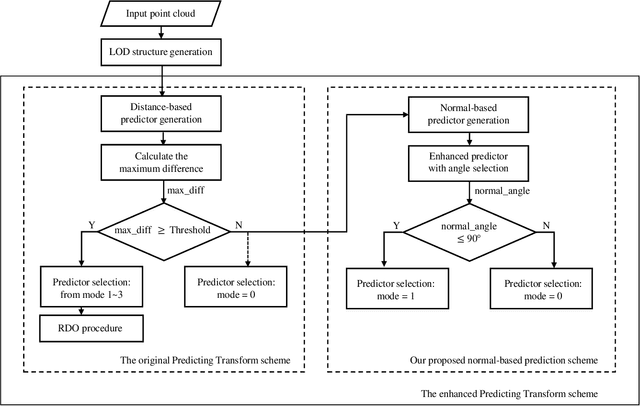
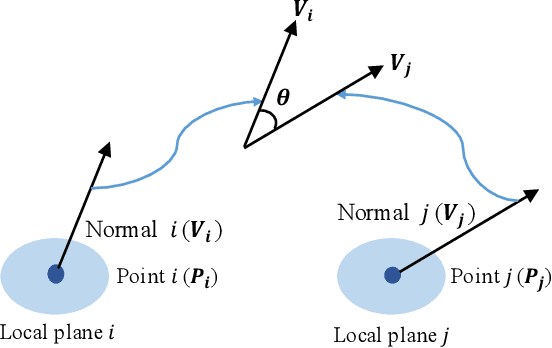
The sparse LiDAR point clouds become more and more popular in various applications, e.g., the autonomous driving. However, for this type of data, there exists much under-explored space in the corresponding compression framework proposed by MPEG, i.e., geometry-based point cloud compression (G-PCC). In G-PCC, only the distance-based similarity is considered in the intra prediction for the attribute compression. In this paper, we propose a normal-based intra prediction scheme, which provides a more efficient lossless attribute compression by introducing the normals of point clouds. The angle between normals is used to further explore accurate local similarity, which optimizes the selection of predictors. We implement our method into the G-PCC reference software. Experimental results over LiDAR acquired datasets demonstrate that our proposed method is able to deliver better compression performance than the G-PCC anchor, with $2.1\%$ gains on average for lossless attribute coding.
RAI-Net: Range-Adaptive LiDAR Point Cloud Frame Interpolation Network
Jun 01, 2021

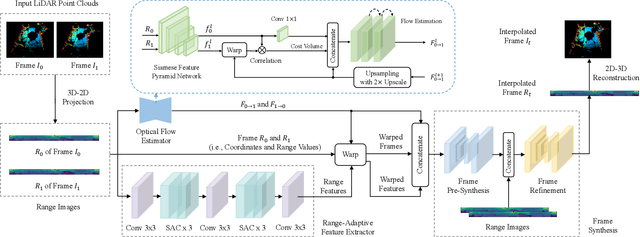
LiDAR point cloud frame interpolation, which synthesizes the intermediate frame between the captured frames, has emerged as an important issue for many applications. Especially for reducing the amounts of point cloud transmission, it is by predicting the intermediate frame based on the reference frames to upsample data to high frame rate ones. However, due to high-dimensional and sparse characteristics of point clouds, it is more difficult to predict the intermediate frame for LiDAR point clouds than videos. In this paper, we propose a novel LiDAR point cloud frame interpolation method, which exploits range images (RIs) as an intermediate representation with CNNs to conduct the frame interpolation process. Considering the inherited characteristics of RIs differ from that of color images, we introduce spatially adaptive convolutions to extract range features adaptively, while a high-efficient flow estimation method is presented to generate optical flows. The proposed model then warps the input frames and range features, based on the optical flows to synthesize the interpolated frame. Extensive experiments on the KITTI dataset have clearly demonstrated that our method consistently achieves superior frame interpolation results with better perceptual quality to that of using state-of-the-art video frame interpolation methods. The proposed method could be integrated into any LiDAR point cloud compression systems for inter prediction.
Synergetic Learning Systems: Concept, Architecture, and Algorithms
Jun 14, 2020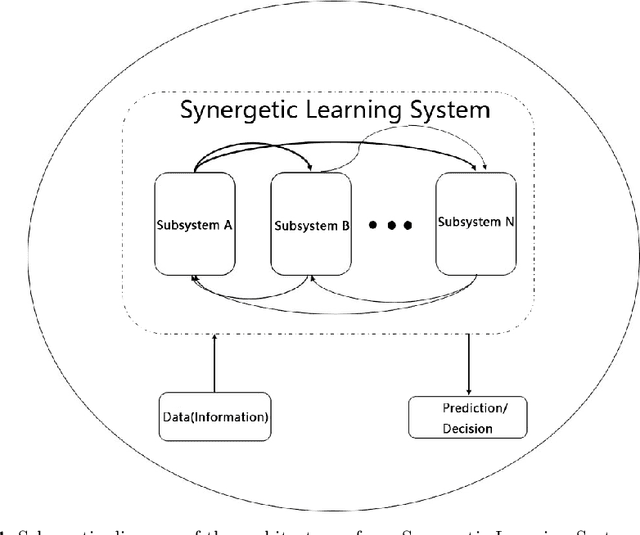
Drawing on the idea that brain development is a Darwinian process of ``evolution + selection'' and the idea that the current state is a local equilibrium state of many bodies with self-organization and evolution processes driven by the temperature and gravity in our universe, in this work, we describe an artificial intelligence system called the ``Synergetic Learning Systems''. The system is composed of two or more subsystems (models, agents or virtual bodies), and it is an open complex giant system. Inspired by natural intelligence, the system achieves intelligent information processing and decision-making in a given environment through cooperative/competitive synergetic learning. The intelligence evolved by the natural law of ``it is not the strongest of the species that survives, but the one most responsive to change,'' while an artificial intelligence system should adopt the law of ``human selection'' in the evolution process. Therefore, we expect that the proposed system architecture can also be adapted in human-machine synergy or multi-agent synergetic systems. It is also expected that under our design criteria, the proposed system will eventually achieve artificial general intelligence through long term coevolution.
Two-dimensional Multi-fiber Spectrum Image Correction Based on Machine Learning Techniques
Feb 16, 2020


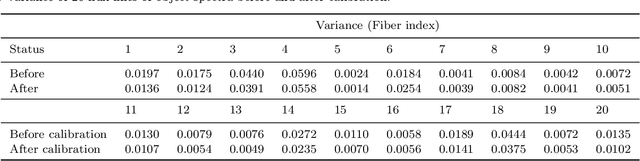
Due to limited size and imperfect of the optical components in a spectrometer, aberration has inevitably been brought into two-dimensional multi-fiber spectrum image in LAMOST, which leads to obvious spacial variation of the point spread functions (PSFs). Consequently, if spatial variant PSFs are estimated directly , the huge storage and intensive computation requirements result in deconvolutional spectral extraction method become intractable. In this paper, we proposed a novel method to solve the problem of spatial variation PSF through image aberration correction. When CCD image aberration is corrected, PSF, the convolution kernel, can be approximated by one spatial invariant PSF only. Specifically, machine learning techniques are adopted to calibrate distorted spectral image, including Total Least Squares (TLS) algorithm, intelligent sampling method, multi-layer feed-forward neural networks. The calibration experiments on the LAMOST CCD images show that the calibration effect of proposed method is effectible. At the same time, the spectrum extraction results before and after calibration are compared, results show the characteristics of the extracted one-dimensional waveform are more close to an ideal optics system, and the PSF of the corrected object spectrum image estimated by the blind deconvolution method is nearly central symmetry, which indicates that our proposed method can significantly reduce the complexity of spectrum extraction and improve extraction accuracy.
Quadratic video interpolation
Nov 02, 2019
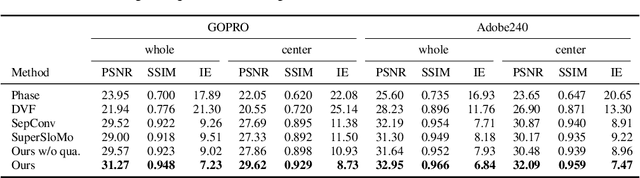
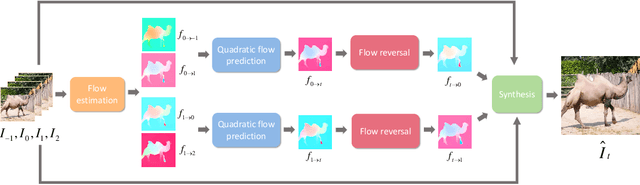

Video interpolation is an important problem in computer vision, which helps overcome the temporal limitation of camera sensors. Existing video interpolation methods usually assume uniform motion between consecutive frames and use linear models for interpolation, which cannot well approximate the complex motion in the real world. To address these issues, we propose a quadratic video interpolation method which exploits the acceleration information in videos. This method allows prediction with curvilinear trajectory and variable velocity, and generates more accurate interpolation results. For high-quality frame synthesis, we develop a flow reversal layer to estimate flow fields starting from the unknown target frame to the source frame. In addition, we present techniques for flow refinement. Extensive experiments demonstrate that our approach performs favorably against the existing linear models on a wide variety of video datasets.