 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Computers
Apr 07, 2026We propose a new frontier: Neural Computers (NCs) -- an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today's agents, world models, and conventional computers.
Planning to Explore: Curiosity-Driven Planning for LLM Test Generation
Apr 06, 2026The use of LLMs for code generation has naturally extended to code testing and evaluation. As codebases grow in size and complexity, so does the need for automated test generation. Current approaches for LLM-based test generation rely on strategies that maximize immediate coverage gain, a greedy approach that plateaus on code where reaching deep branches requires setup steps that individually yield zero new coverage. Drawing on principles of Bayesian exploration, we treat the program's branch structure as an unknown environment, and an evolving coverage map as a proxy probabilistic posterior representing what the LLM has discovered so far. Our method, CovQValue, feeds the coverage map back to the LLM, generates diverse candidate plans in parallel, and selects the most informative plan by LLM-estimated Q-values, seeking actions that balance immediate branch discovery with future reachability. Our method outperforms greedy selection on TestGenEval Lite, achieving 51-77% higher branch coverage across three popular LLMs and winning on 77-84% of targets. In addition, we build a benchmark for iterative test generation, RepoExploreBench, where they achieve 40-74%. These results show the potential of curiosity-driven planning methods for LLM-based exploration, enabling more effective discovery of program behavior through sequential interaction
Learning Glioblastoma Tumor Heterogeneity Using Brain Inspired Topological Neural Networks
Feb 11, 2026Accurate prognosis for Glioblastoma (GBM) using deep learning (DL) is hindered by extreme spatial and structural heterogeneity. Moreover, inconsistent MRI acquisition protocols across institutions hinder generalizability of models. Conventional transformer and DL pipelines often fail to capture the multi-scale morphological diversity such as fragmented necrotic cores, infiltrating margins, and disjoint enhancing components leading to scanner-specific artifacts and poor cross-site prognosis. We propose TopoGBM, a learning framework designed to capture heterogeneity-preserved, scanner-robust representations from multi-parametric 3D MRI. Central to our approach is a 3D convolutional autoencoder regularized by a topological regularization that preserves the complex, non-Euclidean invariants of the tumor's manifold within a compressed latent space. By enforcing these topological priors, TopoGBM explicitly models the high-variance structural signatures characteristic of aggressive GBM. Evaluated across heterogeneous cohorts (UPENN, UCSF, RHUH) and external validation on TCGA, TopoGBM achieves better performance (C-index 0.67 test, 0.58 validation), outperforming baselines that degrade under domain shift. Mechanistic interpretability analysis reveals that reconstruction residuals are highly localized to pathologically heterogeneous zones, with tumor-restricted and healthy tissue error significantly low (Test: 0.03, Validation: 0.09). Furthermore, occlusion-based attribution localizes approximately 50% of the prognostic signal to the tumor and the diverse peritumoral microenvironment advocating clinical reliability of the unsupervised learning method. Our findings demonstrate that incorporating topological priors enables the learning of morphology-faithful embeddings that capture tumor heterogeneity while maintaining cross-institutional robustness.
Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Oct 24, 2025Recent studies operationalize self-improvement through coding agents that edit their own codebases. They grow a tree of self-modifications through expansion strategies that favor higher software engineering benchmark performance, assuming that this implies more promising subsequent self-modifications. However, we identify a mismatch between the agent's self-improvement potential (metaproductivity) and its coding benchmark performance, namely the Metaproductivity-Performance Mismatch. Inspired by Huxley's concept of clade, we propose a metric ($\mathrm{CMP}$) that aggregates the benchmark performances of the descendants of an agent as an indicator of its potential for self-improvement. We show that, in our self-improving coding agent development setting, access to the true $\mathrm{CMP}$ is sufficient to simulate how the G\"odel Machine would behave under certain assumptions. We introduce the Huxley-G\"odel Machine (HGM), which, by estimating $\mathrm{CMP}$ and using it as guidance, searches the tree of self-modifications. On SWE-bench Verified and Polyglot, HGM outperforms prior self-improving coding agent development methods while using less wall-clock time. Last but not least, HGM demonstrates strong transfer to other coding datasets and large language models. The agent optimized by HGM on SWE-bench Verified with GPT-5-mini and evaluated on SWE-bench Lite with GPT-5 achieves human-level performance, matching the best officially checked results of human-engineered coding agents. Our code is available at https://github.com/metauto-ai/HGM.
How to Correctly do Semantic Backpropagation on Language-based Agentic Systems
Dec 04, 2024Language-based agentic systems have shown great promise in recent years, transitioning from solving small-scale research problems to being deployed in challenging real-world tasks. However, optimizing these systems often requires substantial manual labor. Recent studies have demonstrated that these systems can be represented as computational graphs, enabling automatic optimization. Despite these advancements, most current efforts in Graph-based Agentic System Optimization (GASO) fail to properly assign feedback to the system's components given feedback on the system's output. To address this challenge, we formalize the concept of semantic backpropagation with semantic gradients -- a generalization that aligns several key optimization techniques, including reverse-mode automatic differentiation and the more recent TextGrad by exploiting the relationship among nodes with a common successor. This serves as a method for computing directional information about how changes to each component of an agentic system might improve the system's output. To use these gradients, we propose a method called semantic gradient descent which enables us to solve GASO effectively. Our results on both BIG-Bench Hard and GSM8K show that our approach outperforms existing state-of-the-art methods for solving GASO problems. A detailed ablation study on the LIAR dataset demonstrates the parsimonious nature of our method. A full copy of our implementation is publicly available at https://github.com/HishamAlyahya/semantic_backprop
FACTS: A Factored State-Space Framework For World Modelling
Oct 28, 2024



World modelling is essential for understanding and predicting the dynamics of complex systems by learning both spatial and temporal dependencies. However, current frameworks, such as Transformers and selective state-space models like Mambas, exhibit limitations in efficiently encoding spatial and temporal structures, particularly in scenarios requiring long-term high-dimensional sequence modelling. To address these issues, we propose a novel recurrent framework, the \textbf{FACT}ored \textbf{S}tate-space (\textbf{FACTS}) model, for spatial-temporal world modelling. The FACTS framework constructs a graph-structured memory with a routing mechanism that learns permutable memory representations, ensuring invariance to input permutations while adapting through selective state-space propagation. Furthermore, FACTS supports parallel computation of high-dimensional sequences. We empirically evaluate FACTS across diverse tasks, including multivariate time series forecasting and object-centric world modelling, demonstrating that it consistently outperforms or matches specialised state-of-the-art models, despite its general-purpose world modelling design.
Agent-as-a-Judge: Evaluate Agents with Agents
Oct 14, 2024



Contemporary evaluation techniques are inadequate for agentic systems. These approaches either focus exclusively on final outcomes -- ignoring the step-by-step nature of agentic systems, or require excessive manual labour. To address this, we introduce the Agent-as-a-Judge framework, wherein agentic systems are used to evaluate agentic systems. This is an organic extension of the LLM-as-a-Judge framework, incorporating agentic features that enable intermediate feedback for the entire task-solving process. We apply the Agent-as-a-Judge to the task of code generation. To overcome issues with existing benchmarks and provide a proof-of-concept testbed for Agent-as-a-Judge, we present DevAI, a new benchmark of 55 realistic automated AI development tasks. It includes rich manual annotations, like a total of 365 hierarchical user requirements. We benchmark three of the popular agentic systems using Agent-as-a-Judge and find it dramatically outperforms LLM-as-a-Judge and is as reliable as our human evaluation baseline. Altogether, we believe that Agent-as-a-Judge marks a concrete step forward for modern agentic systems -- by providing rich and reliable reward signals necessary for dynamic and scalable self-improvement.
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Apr 10, 2024



Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at \url{https://github.com/mulns/PerVFI}
Towards a Robust Retrieval-Based Summarization System
Mar 29, 2024



This paper describes an investigation of the robustness of large language models (LLMs) for retrieval augmented generation (RAG)-based summarization tasks. While LLMs provide summarization capabilities, their performance in complex, real-world scenarios remains under-explored. Our first contribution is LogicSumm, an innovative evaluation framework incorporating realistic scenarios to assess LLM robustness during RAG-based summarization. Based on limitations identified by LogiSumm, we then developed SummRAG, a comprehensive system to create training dialogues and fine-tune a model to enhance robustness within LogicSumm's scenarios. SummRAG is an example of our goal of defining structured methods to test the capabilities of an LLM, rather than addressing issues in a one-off fashion. Experimental results confirm the power of SummRAG, showcasing improved logical coherence and summarization quality. Data, corresponding model weights, and Python code are available online.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024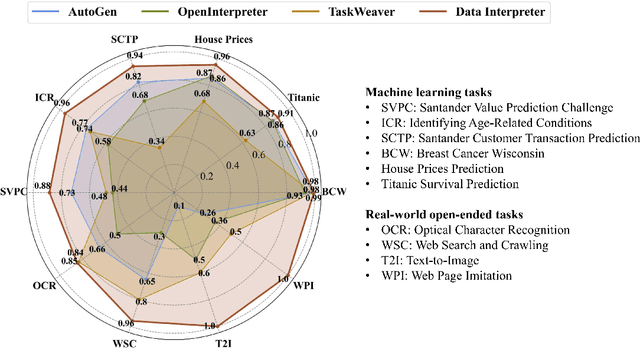
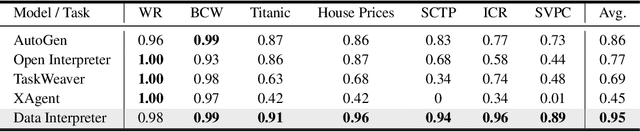
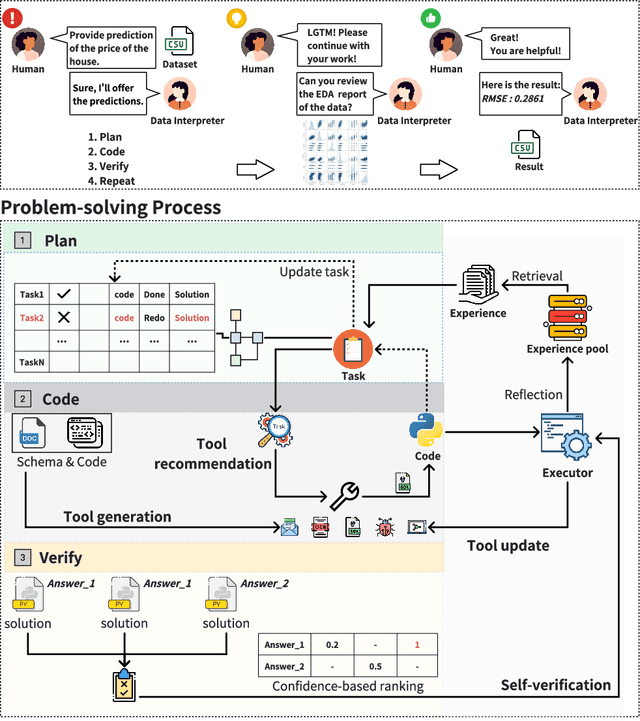

Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.