 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Wideband User Scheduling and Hybrid Precoding with Graph Neural Networks
Mar 06, 2025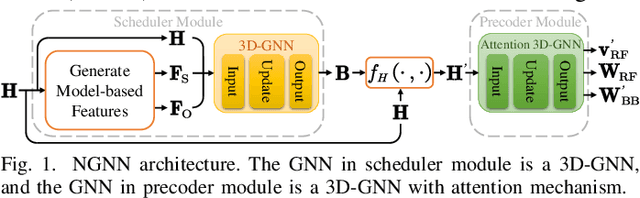
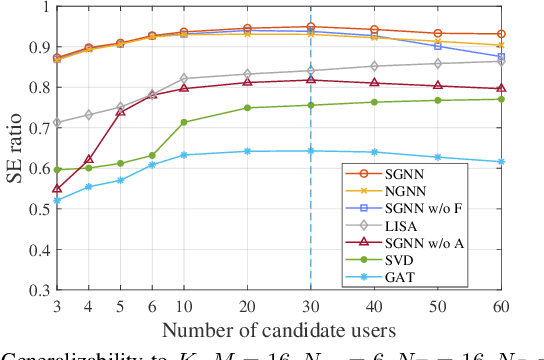
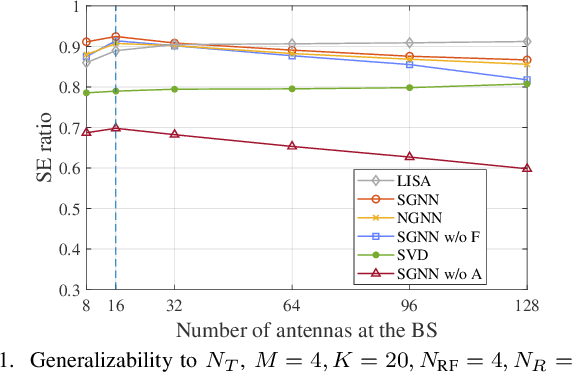

Spatial-frequency scheduling and hybrid precoding in wideband multi-user multi-antenna systems have never been learned jointly due to the challenges arising from the massive user combinations on resource blocks (RBs) and the shared analog precoder among RBs. In this paper, we strive to jointly learn the scheduling and precoding policies with graph neural networks (GNNs), which have emerged as a powerful tool for optimizing resource allocation thanks to their potential in generalizing across problem scales. By reformulating the joint optimization problem into an equivalent functional optimization problem for the scheduling and precoding policies, we propose a GNN-based architecture consisting of two cascaded modules to learn the two policies. We discover a same-parameter same-decision (SPSD) property for wireless policies defined on sets, revealing that a GNN cannot well learn the optimal scheduling policy when users have similar channels. This motivates us to develop a sequence of GNNs to enhance the scheduling module. Furthermore, by analyzing the SPSD property, we find when linear aggregators in GNNs impede size generalization. Based on the observation, we devise a novel attention mechanism for information aggregation in the precoder module. Simulation results demonstrate that the proposed architecture achieves satisfactory spectral efficiency with short inference time and low training complexity, and is generalizable to the numbers of users, RBs, and antennas at the base station and users.
Daily Land Surface Temperature Reconstruction in Landsat Cross-Track Areas Using Deep Ensemble Learning With Uncertainty Quantification
Feb 20, 2025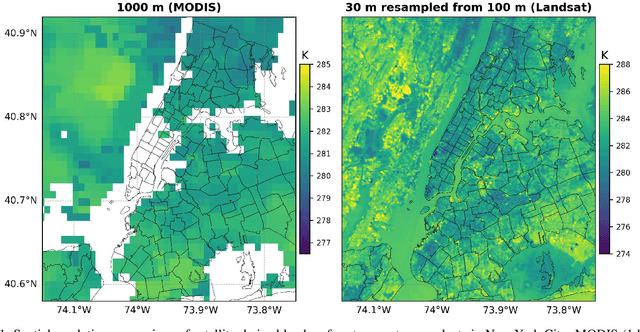
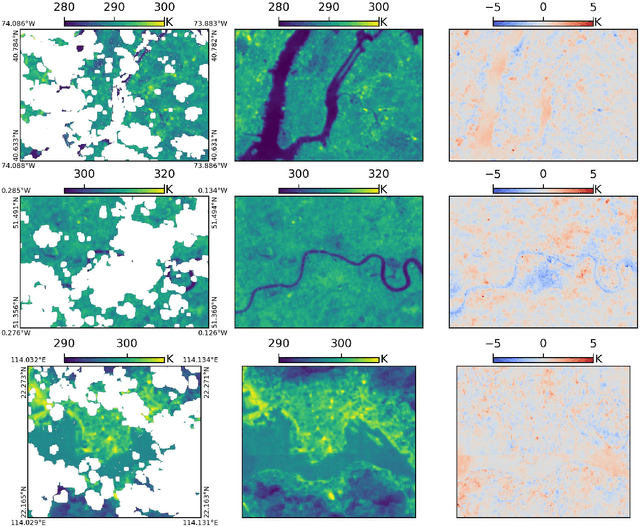
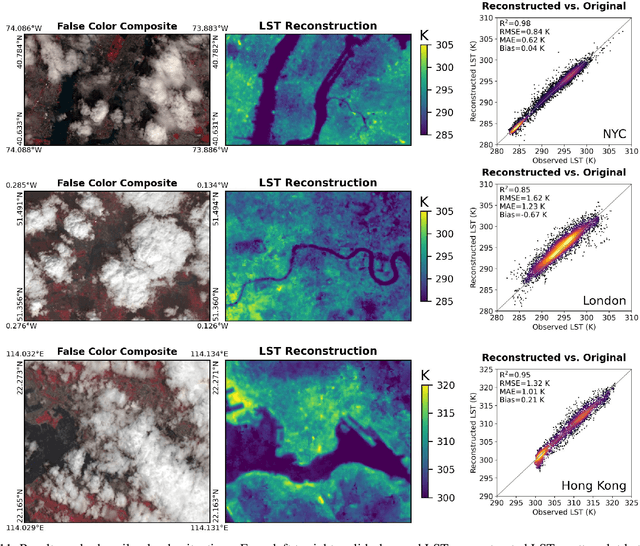
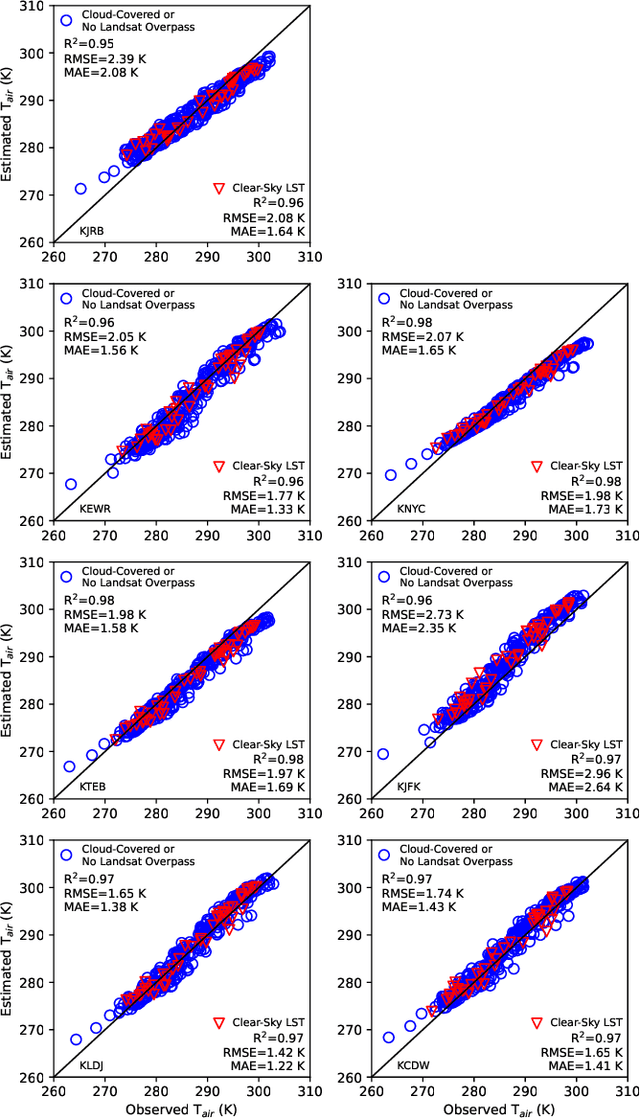
Many real-world applications rely on land surface temperature (LST) data at high spatiotemporal resolution. In complex urban areas, LST exhibits significant variations, fluctuating dramatically within and across city blocks. Landsat provides high spatial resolution data at 100 meters but is limited by long revisit time, with cloud cover further disrupting data collection. Here, we propose DELAG, a deep ensemble learning method that integrates annual temperature cycles and Gaussian processes, to reconstruct Landsat LST in complex urban areas. Leveraging the cross-track characteristics and dual-satellite operation of Landsat since 2021, we further enhance data availability to 4 scenes every 16 days. We select New York City, London and Hong Kong from three different continents as study areas. Experiments show that DELAG successfully reconstructed LST in the three cities under clear-sky (RMSE = 0.73-0.96 K) and heavily-cloudy (RMSE = 0.84-1.62 K) situations, superior to existing methods. Additionally, DELAG can quantify uncertainty that enhances LST reconstruction reliability. We further tested the reconstructed LST to estimate near-surface air temperature, achieving results (RMSE = 1.48-2.11 K) comparable to those derived from clear-sky LST (RMSE = 1.63-2.02 K). The results demonstrate the successful reconstruction through DELAG and highlight the broader applications of LST reconstruction for estimating accurate air temperature. Our study thus provides a novel and practical method for Landsat LST reconstruction, particularly suited for complex urban areas within Landsat cross-track areas, taking one step toward addressing complex climate events at high spatiotemporal resolution.
Source-free Semantic Regularization Learning for Semi-supervised Domain Adaptation
Jan 02, 2025



Semi-supervised domain adaptation (SSDA) has been extensively researched due to its ability to improve classification performance and generalization ability of models by using a small amount of labeled data on the target domain. However, existing methods cannot effectively adapt to the target domain due to difficulty in fully learning rich and complex target semantic information and relationships. In this paper, we propose a novel SSDA learning framework called semantic regularization learning (SERL), which captures the target semantic information from multiple perspectives of regularization learning to achieve adaptive fine-tuning of the source pre-trained model on the target domain. SERL includes three robust semantic regularization techniques. Firstly, semantic probability contrastive regularization (SPCR) helps the model learn more discriminative feature representations from a probabilistic perspective, using semantic information on the target domain to understand the similarities and differences between samples. Additionally, adaptive weights in SPCR can help the model learn the semantic distribution correctly through the probabilities of different samples. To further comprehensively understand the target semantic distribution, we introduce hard-sample mixup regularization (HMR), which uses easy samples as guidance to mine the latent target knowledge contained in hard samples, thereby learning more complete and complex target semantic knowledge. Finally, target prediction regularization (TPR) regularizes the target predictions of the model by maximizing the correlation between the current prediction and the past learned objective, thereby mitigating the misleading of semantic information caused by erroneous pseudo-labels. Extensive experiments on three benchmark datasets demonstrate that our SERL method achieves state-of-the-art performance.
CROPS: A Deployable Crop Management System Over All Possible State Availabilities
Nov 09, 2024



Exploring the optimal management strategy for nitrogen and irrigation has a significant impact on crop yield, economic profit, and the environment. To tackle this optimization challenge, this paper introduces a deployable \textbf{CR}op Management system \textbf{O}ver all \textbf{P}ossible \textbf{S}tate availabilities (CROPS). CROPS employs a language model (LM) as a reinforcement learning (RL) agent to explore optimal management strategies within the Decision Support System for Agrotechnology Transfer (DSSAT) crop simulations. A distinguishing feature of this system is that the states used for decision-making are partially observed through random masking. Consequently, the RL agent is tasked with two primary objectives: optimizing management policies and inferring masked states. This approach significantly enhances the RL agent's robustness and adaptability across various real-world agricultural scenarios. Extensive experiments on maize crops in Florida, USA, and Zaragoza, Spain, validate the effectiveness of CROPS. Not only did CROPS achieve State-of-the-Art (SOTA) results across various evaluation metrics such as production, profit, and sustainability, but the trained management policies are also immediately deployable in over of ten millions of real-world contexts. Furthermore, the pre-trained policies possess a noise resilience property, which enables them to minimize potential sensor biases, ensuring robustness and generalizability. Finally, unlike previous methods, the strength of CROPS lies in its unified and elegant structure, which eliminates the need for pre-defined states or multi-stage training. These advancements highlight the potential of CROPS in revolutionizing agricultural practices.
Learning Robust Correlation with Foundation Model for Weakly-Supervised Few-Shot Segmentation
May 30, 2024Existing few-shot segmentation (FSS) only considers learning support-query correlation and segmenting unseen categories under the precise pixel masks. However, the cost of a large number of pixel masks during training is expensive. This paper considers a more challenging scenario, weakly-supervised few-shot segmentation (WS-FSS), which only provides category ($i.e.$ image-level) labels. It requires the model to learn robust support-query information when the generated mask is inaccurate. In this work, we design a Correlation Enhancement Network (CORENet) with foundation model, which utilizes multi-information guidance to learn robust correlation. Specifically, correlation-guided transformer (CGT) utilizes self-supervised ViT tokens to learn robust correlation from both local and global perspectives. From the perspective of semantic categories, the class-guided module (CGM) guides the model to locate valuable correlations through the pre-trained CLIP. Finally, the embedding-guided module (EGM) implicitly guides the model to supplement the inevitable information loss during the correlation learning by the original appearance embedding and finally generates the query mask. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ have shown that CORENet exhibits excellent performance compared to existing methods.
Deep Feature Gaussian Processes for Single-Scene Aerosol Optical Depth Reconstruction
May 27, 2024



Remote sensing data provide a low-cost solution for large-scale monitoring of air pollution via the retrieval of aerosol optical depth (AOD), but is often limited by cloud contamination. Existing methods for AOD reconstruction rely on temporal information. However, for remote sensing data at high spatial resolution, multi-temporal observations are often unavailable. In this letter, we take advantage of deep representation learning from convolutional neural networks and propose Deep Feature Gaussian Processes (DFGP) for single-scene AOD reconstruction. By using deep learning, we transform the variables to a feature space with better explainable power. By using Gaussian processes, we explicitly consider the correlation between observed AOD and missing AOD in spatial and feature domains. Experiments on two AOD datasets with real-world cloud patterns showed that the proposed method outperformed deep CNN and random forest, achieving R$^2$ of 0.7431 on MODIS AOD and R$^2$ of 0.9211 on EMIT AOD, compared to deep CNN's R$^2$ of 0.6507 and R$^2$ of 0.8619. The proposed methods increased R$^2$ by over 0.35 compared to the popular random forest in AOD reconstruction. The data and code used in this study are available at \url{https://skrisliu.com/dfgp}.
Towards a Robust Retrieval-Based Summarization System
Mar 29, 2024



This paper describes an investigation of the robustness of large language models (LLMs) for retrieval augmented generation (RAG)-based summarization tasks. While LLMs provide summarization capabilities, their performance in complex, real-world scenarios remains under-explored. Our first contribution is LogicSumm, an innovative evaluation framework incorporating realistic scenarios to assess LLM robustness during RAG-based summarization. Based on limitations identified by LogiSumm, we then developed SummRAG, a comprehensive system to create training dialogues and fine-tune a model to enhance robustness within LogicSumm's scenarios. SummRAG is an example of our goal of defining structured methods to test the capabilities of an LLM, rather than addressing issues in a one-off fashion. Experimental results confirm the power of SummRAG, showcasing improved logical coherence and summarization quality. Data, corresponding model weights, and Python code are available online.
SwitchTab: Switched Autoencoders Are Effective Tabular Learners
Jan 04, 2024



Self-supervised representation learning methods have achieved significant success in computer vision and natural language processing, where data samples exhibit explicit spatial or semantic dependencies. However, applying these methods to tabular data is challenging due to the less pronounced dependencies among data samples. In this paper, we address this limitation by introducing SwitchTab, a novel self-supervised method specifically designed to capture latent dependencies in tabular data. SwitchTab leverages an asymmetric encoder-decoder framework to decouple mutual and salient features among data pairs, resulting in more representative embeddings. These embeddings, in turn, contribute to better decision boundaries and lead to improved results in downstream tasks. To validate the effectiveness of SwitchTab, we conduct extensive experiments across various domains involving tabular data. The results showcase superior performance in end-to-end prediction tasks with fine-tuning. Moreover, we demonstrate that pre-trained salient embeddings can be utilized as plug-and-play features to enhance the performance of various traditional classification methods (e.g., Logistic Regression, XGBoost, etc.). Lastly, we highlight the capability of SwitchTab to create explainable representations through visualization of decoupled mutual and salient features in the latent space.
Is Knowledge All Large Language Models Needed for Causal Reasoning?
Dec 30, 2023



This paper explores the causal reasoning of large language models (LLMs) to enhance their interpretability and reliability in advancing artificial intelligence. Despite the proficiency of LLMs in a range of tasks, their potential for understanding causality requires further exploration. We propose a novel causal attribution model that utilizes "do-operators" for constructing counterfactual scenarios, allowing us to systematically quantify the influence of input numerical data and LLMs' pre-existing knowledge on their causal reasoning processes. Our newly developed experimental setup assesses LLMs' reliance on contextual information and inherent knowledge across various domains. Our evaluation reveals that LLMs' causal reasoning ability depends on the context and domain-specific knowledge provided, and supports the argument that "knowledge is, indeed, what LLMs principally require for sound causal reasoning". On the contrary, in the absence of knowledge, LLMs still maintain a degree of causal reasoning using the available numerical data, albeit with limitations in the calculations.
Breast Cancer Immunohistochemical Image Generation: a Benchmark Dataset and Challenge Review
May 05, 2023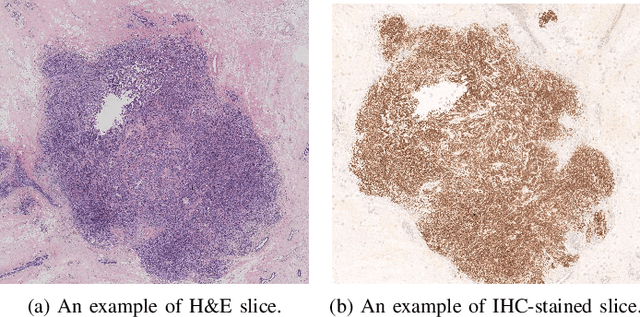
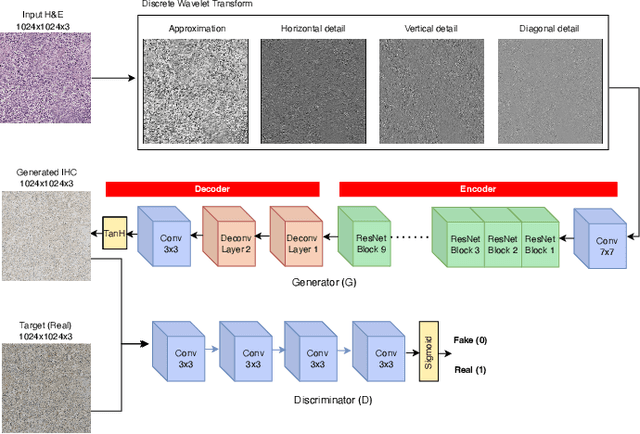

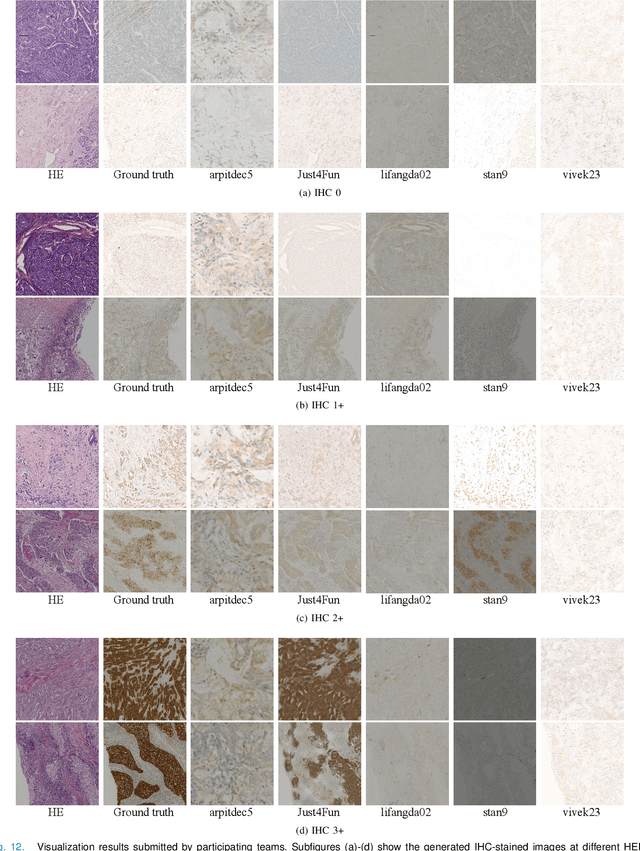
For invasive breast cancer, immunohistochemical (IHC) techniques are often used to detect the expression level of human epidermal growth factor receptor-2 (HER2) in breast tissue to formulate a precise treatment plan. From the perspective of saving manpower, material and time costs, directly generating IHC-stained images from hematoxylin and eosin (H&E) stained images is a valuable research direction. Therefore, we held the breast cancer immunohistochemical image generation challenge, aiming to explore novel ideas of deep learning technology in pathological image generation and promote research in this field. The challenge provided registered H&E and IHC-stained image pairs, and participants were required to use these images to train a model that can directly generate IHC-stained images from corresponding H&E-stained images. We selected and reviewed the five highest-ranking methods based on their PSNR and SSIM metrics, while also providing overviews of the corresponding pipelines and implementations. In this paper, we further analyze the current limitations in the field of breast cancer immunohistochemical image generation and forecast the future development of this field. We hope that the released dataset and the challenge will inspire more scholars to jointly study higher-quality IHC-stained image generation.