 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning
Apr 07, 2026Robotic imitation learning faces a fundamental trade-off between modeling long-horizon dependencies and enabling fine-grained closed-loop control. Existing fixed-frequency action chunking approaches struggle to achieve both. Building on this insight, we propose HiPolicy, a hierarchical multi-frequency action chunking framework that jointly predicts action sequences at different frequencies to capture both coarse high-level plans and precise reactive motions. We extract and fuse hierarchical features from history observations aligned to each frequency for multi-frequency chunk generation, and introduce an entropy-guided execution mechanism that adaptively balances long-horizon planning with fine-grained control based on action uncertainty. Experiments on diverse simulated benchmarks and real-world manipulation tasks show that HiPolicy can be seamlessly integrated into existing 2D and 3D generative policies, delivering consistent improvements in performance while significantly enhancing execution efficiency.
FreeArtGS: Articulated Gaussian Splatting Under Free-moving Scenario
Mar 23, 2026The increasing demand for augmented reality and robotics is driving the need for articulated object reconstruction with high scalability. However, existing settings for reconstructing from discrete articulation states or casual monocular videos require non-trivial axis alignment or suffer from insufficient coverage, limiting their applicability. In this paper, we introduce FreeArtGS, a novel method for reconstructing articulated objects under free-moving scenario, a new setting with a simple setup and high scalability. FreeArtGS combines free-moving part segmentation with joint estimation and end-to-end optimization, taking only a monocular RGB-D video as input. By optimizing with the priors from off-the-shelf point-tracking and feature models, the free-moving part segmentation module identifies rigid parts from relative motion under unconstrained capture. The joint estimation module calibrates the unified object-to-camera poses and recovers joint type and axis robustly from part segmentation. Finally, 3DGS-based end-to-end optimization is implemented to jointly reconstruct visual textures, geometry, and joint angles of the articulated object. We conduct experiments on two benchmarks and real-world free-moving articulated objects. Experimental results demonstrate that FreeArtGS consistently excels in reconstructing free-moving articulated objects and remains highly competitive in previous reconstruction settings, proving itself a practical and effective solution for realistic asset generation. The project page is available at: https://freeartgs.github.io/
AnchorVLA4D: an Anchor-Based Spatial-Temporal Vision-Language-Action Model for Robotic Manipulation
Mar 13, 2026Since current Vision-Language-Action (VLA) systems suffer from limited spatial perception and the absence of memory throughout manipulation, we investigate visual anchors as a means to enhance spatial and temporal reasoning within VLA policies for robotic manipulation. Conventional VLAs generate actions by conditioning on a single current frame together with a language instruction. However, since the frame is encoded as a 2D image, it does not contain detailed spatial information, and the VLA similarly lacks any means to incorporate past context. As a result, it frequently forgets objects under occlusion and becomes spatially disoriented during the manipulation process. Thus, we propose AnchorVLA4D, a simple spatial-temporal VLA that augments the visual input with an anchor image to preserve the initial scene context throughout execution, and adds a lightweight spatial encoder that jointly processes the anchor and current frames to expose geometric relationships within an episode. Built on a Qwen2.5-VL backbone with a diffusion-based action head, AnchorVLA4D requires no additional sensing modalities (e.g., depth or point clouds) and introduces negligible inference overhead. Combining anchoring with a frozen pretrained spatial encoder yields further gains, realizing a 13.6% improvement on the Simpler WidowX benchmark and confirming the approach on real-world tasks, where it achieved an average success rate of 80%.
CaveAgent: Transforming LLMs into Stateful Runtime Operators
Jan 04, 2026LLM-based agents are increasingly capable of complex task execution, yet current agentic systems remain constrained by text-centric paradigms. Traditional approaches rely on procedural JSON-based function calling, which often struggles with long-horizon tasks due to fragile multi-turn dependencies and context drift. In this paper, we present CaveAgent, a framework that transforms the paradigm from "LLM-as-Text-Generator" to "LLM-as-Runtime-Operator." We introduce a Dual-stream Context Architecture that decouples state management into a lightweight semantic stream for reasoning and a persistent, deterministic Python Runtime stream for execution. In addition to leveraging code generation to efficiently resolve interdependent sub-tasks (e.g., loops, conditionals) in a single step, we introduce \textit{Stateful Runtime Management} in CaveAgent. Distinct from existing code-based approaches that remain text-bound and lack the support for external object injection and retrieval, CaveAgent injects, manipulates, and retrieves complex Python objects (e.g., DataFrames, database connections) that persist across turns. This persistence mechanism acts as a high-fidelity external memory to eliminate context drift, avoid catastrophic forgetting, while ensuring that processed data flows losslessly to downstream applications. Comprehensive evaluations on Tau$^2$-bench, BFCL and various case studies across representative SOTA LLMs demonstrate CaveAgent's superiority. Specifically, our framework achieves a 10.5\% success rate improvement on retail tasks and reduces total token consumption by 28.4\% in multi-turn scenarios. On data-intensive tasks, direct variable storage and retrieval reduces token consumption by 59\%, allowing CaveAgent to handle large-scale data that causes context overflow failures in both JSON-based and Code-based agents.
TwinAligner: Visual-Dynamic Alignment Empowers Physics-aware Real2Sim2Real for Robotic Manipulation
Dec 22, 2025The robotics field is evolving towards data-driven, end-to-end learning, inspired by multimodal large models. However, reliance on expensive real-world data limits progress. Simulators offer cost-effective alternatives, but the gap between simulation and reality challenges effective policy transfer. This paper introduces TwinAligner, a novel Real2Sim2Real system that addresses both visual and dynamic gaps. The visual alignment module achieves pixel-level alignment through SDF reconstruction and editable 3DGS rendering, while the dynamic alignment module ensures dynamic consistency by identifying rigid physics from robot-object interaction. TwinAligner improves robot learning by providing scalable data collection and establishing a trustworthy iterative cycle, accelerating algorithm development. Quantitative evaluations highlight TwinAligner's strong capabilities in visual and dynamic real-to-sim alignment. This system enables policies trained in simulation to achieve strong zero-shot generalization to the real world. The high consistency between real-world and simulated policy performance underscores TwinAligner's potential to advance scalable robot learning. Code and data will be released on https://twin-aligner.github.io
Real2Edit2Real: Generating Robotic Demonstrations via a 3D Control Interface
Dec 22, 2025Recent progress in robot learning has been driven by large-scale datasets and powerful visuomotor policy architectures, yet policy robustness remains limited by the substantial cost of collecting diverse demonstrations, particularly for spatial generalization in manipulation tasks. To reduce repetitive data collection, we present Real2Edit2Real, a framework that generates new demonstrations by bridging 3D editability with 2D visual data through a 3D control interface. Our approach first reconstructs scene geometry from multi-view RGB observations with a metric-scale 3D reconstruction model. Based on the reconstructed geometry, we perform depth-reliable 3D editing on point clouds to generate new manipulation trajectories while geometrically correcting the robot poses to recover physically consistent depth, which serves as a reliable condition for synthesizing new demonstrations. Finally, we propose a multi-conditional video generation model guided by depth as the primary control signal, together with action, edge, and ray maps, to synthesize spatially augmented multi-view manipulation videos. Experiments on four real-world manipulation tasks demonstrate that policies trained on data generated from only 1-5 source demonstrations can match or outperform those trained on 50 real-world demonstrations, improving data efficiency by up to 10-50x. Moreover, experimental results on height and texture editing demonstrate the framework's flexibility and extensibility, indicating its potential to serve as a unified data generation framework.
CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model
Aug 14, 2025Existing vision-and-language navigation models often deviate from the correct trajectory when executing instructions. However, these models lack effective error correction capability, hindering their recovery from errors. To address this challenge, we propose Self-correction Flywheel, a novel post-training paradigm. Instead of considering the model's error trajectories on the training set as a drawback, our paradigm emphasizes their significance as a valuable data source. We have developed a method to identify deviations in these error trajectories and devised innovative techniques to automatically generate self-correction data for perception and action. These self-correction data serve as fuel to power the model's continued training. The brilliance of our paradigm is revealed when we re-evaluate the model on the training set, uncovering new error trajectories. At this time, the self-correction flywheel begins to spin. Through multiple flywheel iterations, we progressively enhance our monocular RGB-based VLA navigation model CorrectNav. Experiments on R2R-CE and RxR-CE benchmarks show CorrectNav achieves new state-of-the-art success rates of 65.1% and 69.3%, surpassing prior best VLA navigation models by 8.2% and 16.4%. Real robot tests in various indoor and outdoor environments demonstrate \method's superior capability of error correction, dynamic obstacle avoidance, and long instruction following.
BiAssemble: Learning Collaborative Affordance for Bimanual Geometric Assembly
Jun 06, 2025Shape assembly, the process of combining parts into a complete whole, is a crucial robotic skill with broad real-world applications. Among various assembly tasks, geometric assembly--where broken parts are reassembled into their original form (e.g., reconstructing a shattered bowl)--is particularly challenging. This requires the robot to recognize geometric cues for grasping, assembly, and subsequent bimanual collaborative manipulation on varied fragments. In this paper, we exploit the geometric generalization of point-level affordance, learning affordance aware of bimanual collaboration in geometric assembly with long-horizon action sequences. To address the evaluation ambiguity caused by geometry diversity of broken parts, we introduce a real-world benchmark featuring geometric variety and global reproducibility. Extensive experiments demonstrate the superiority of our approach over both previous affordance-based and imitation-based methods. Project page: https://sites.google.com/view/biassembly/.
Interacted Object Grounding in Spatio-Temporal Human-Object Interactions
Dec 27, 2024



Spatio-temporal Human-Object Interaction (ST-HOI) understanding aims at detecting HOIs from videos, which is crucial for activity understanding. However, existing whole-body-object interaction video benchmarks overlook the truth that open-world objects are diverse, that is, they usually provide limited and predefined object classes. Therefore, we introduce a new open-world benchmark: Grounding Interacted Objects (GIO) including 1,098 interacted objects class and 290K interacted object boxes annotation. Accordingly, an object grounding task is proposed expecting vision systems to discover interacted objects. Even though today's detectors and grounding methods have succeeded greatly, they perform unsatisfactorily in localizing diverse and rare objects in GIO. This profoundly reveals the limitations of current vision systems and poses a great challenge. Thus, we explore leveraging spatio-temporal cues to address object grounding and propose a 4D question-answering framework (4D-QA) to discover interacted objects from diverse videos. Our method demonstrates significant superiority in extensive experiments compared to current baselines. Data and code will be publicly available at https://github.com/DirtyHarryLYL/HAKE-AVA.
Breast Cancer Immunohistochemical Image Generation: a Benchmark Dataset and Challenge Review
May 05, 2023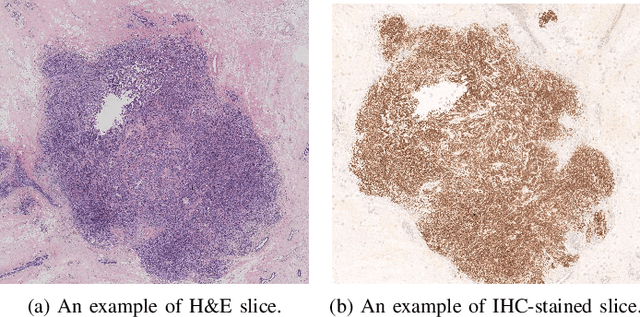
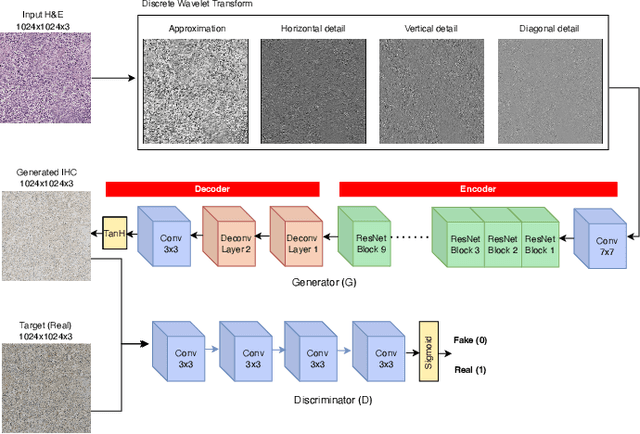

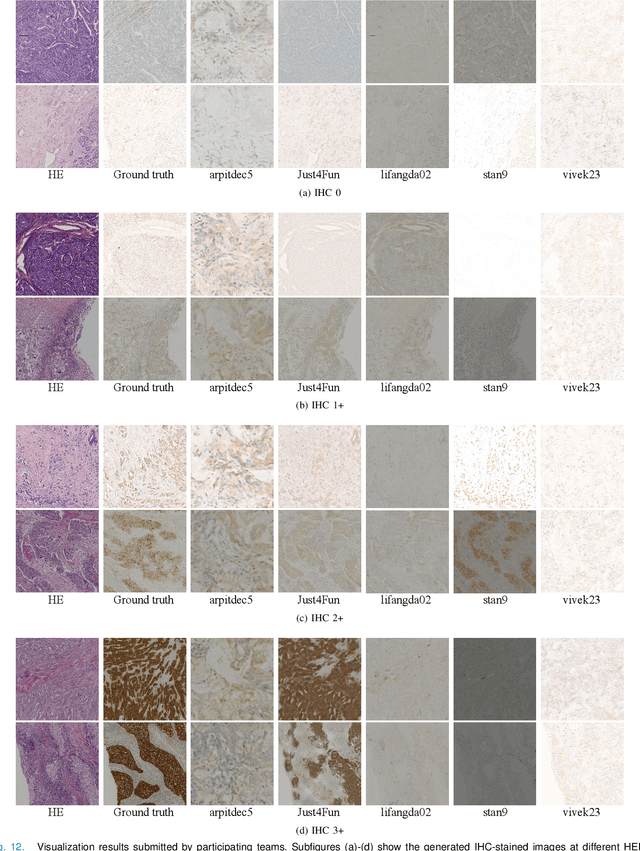
For invasive breast cancer, immunohistochemical (IHC) techniques are often used to detect the expression level of human epidermal growth factor receptor-2 (HER2) in breast tissue to formulate a precise treatment plan. From the perspective of saving manpower, material and time costs, directly generating IHC-stained images from hematoxylin and eosin (H&E) stained images is a valuable research direction. Therefore, we held the breast cancer immunohistochemical image generation challenge, aiming to explore novel ideas of deep learning technology in pathological image generation and promote research in this field. The challenge provided registered H&E and IHC-stained image pairs, and participants were required to use these images to train a model that can directly generate IHC-stained images from corresponding H&E-stained images. We selected and reviewed the five highest-ranking methods based on their PSNR and SSIM metrics, while also providing overviews of the corresponding pipelines and implementations. In this paper, we further analyze the current limitations in the field of breast cancer immunohistochemical image generation and forecast the future development of this field. We hope that the released dataset and the challenge will inspire more scholars to jointly study higher-quality IHC-stained image generation.