 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation
Feb 04, 2026Reconstructing dynamic hand-object interactions from monocular videos is critical for dexterous manipulation data collection and creating realistic digital twins for robotics and VR. However, current methods face two prohibitive barriers: (1) reliance on neural rendering often yields fragmented, non-simulation-ready geometries under heavy occlusion, and (2) dependence on brittle Structure-from-Motion (SfM) initialization leads to frequent failures on in-the-wild footage. To overcome these limitations, we introduce AGILE, a robust framework that shifts the paradigm from reconstruction to agentic generation for interaction learning. First, we employ an agentic pipeline where a Vision-Language Model (VLM) guides a generative model to synthesize a complete, watertight object mesh with high-fidelity texture, independent of video occlusions. Second, bypassing fragile SfM entirely, we propose a robust anchor-and-track strategy. We initialize the object pose at a single interaction onset frame using a foundation model and propagate it temporally by leveraging the strong visual similarity between our generated asset and video observations. Finally, a contact-aware optimization integrates semantic, geometric, and interaction stability constraints to enforce physical plausibility. Extensive experiments on HO3D, DexYCB, and in-the-wild videos reveal that AGILE outperforms baselines in global geometric accuracy while demonstrating exceptional robustness on challenging sequences where prior art frequently collapses. By prioritizing physical validity, our method produces simulation-ready assets validated via real-to-sim retargeting for robotic applications.
BinaryDemoire: Moiré-Aware Binarization for Image Demoiréing
Feb 03, 2026Image demoiréing aims to remove structured moiré artifacts in recaptured imagery, where degradations are highly frequency-dependent and vary across scales and directions. While recent deep networks achieve high-quality restoration, their full-precision designs remain costly for deployment. Binarization offers an extreme compression regime by quantizing both activations and weights to 1-bit. Yet, it has been rarely studied for demoiréing and performs poorly when naively applied. In this work, we propose BinaryDemoire, a binarized demoiréing framework that explicitly accommodates the frequency structure of moiré degradations. First, we introduce a moiré-aware binary gate (MABG) that extracts lightweight frequency descriptors together with activation statistics. It predicts channel-wise gating coefficients to condition the aggregation of binary convolution responses. Second, we design a shuffle-grouped residual adapter (SGRA) that performs structured sparse shortcut alignment. It further integrates interleaved mixing to promote information exchange across different channel partitions. Extensive experiments on four benchmarks demonstrate that the proposed BinaryDemoire surpasses current binarization methods. Code: https://github.com/zhengchen1999/BinaryDemoire.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
FideDiff: Efficient Diffusion Model for High-Fidelity Image Motion Deblurring
Oct 02, 2025


Recent advancements in image motion deblurring, driven by CNNs and transformers, have made significant progress. Large-scale pre-trained diffusion models, which are rich in true-world modeling, have shown great promise for high-quality image restoration tasks such as deblurring, demonstrating stronger generative capabilities than CNN and transformer-based methods. However, challenges such as unbearable inference time and compromised fidelity still limit the full potential of the diffusion models. To address this, we introduce FideDiff, a novel single-step diffusion model designed for high-fidelity deblurring. We reformulate motion deblurring as a diffusion-like process where each timestep represents a progressively blurred image, and we train a consistency model that aligns all timesteps to the same clean image. By reconstructing training data with matched blur trajectories, the model learns temporal consistency, enabling accurate one-step deblurring. We further enhance model performance by integrating Kernel ControlNet for blur kernel estimation and introducing adaptive timestep prediction. Our model achieves superior performance on full-reference metrics, surpassing previous diffusion-based methods and matching the performance of other state-of-the-art models. FideDiff offers a new direction for applying pre-trained diffusion models to high-fidelity image restoration tasks, establishing a robust baseline for further advancing diffusion models in real-world industrial applications. Our dataset and code will be available at https://github.com/xyLiu339/FideDiff.
ASSESS: A Semantic and Structural Evaluation Framework for Statement Similarity
Sep 26, 2025Statement autoformalization, the automated translation of statements from natural language into formal languages, has seen significant advancements, yet the development of automated evaluation metrics remains limited. Existing metrics for formal statement similarity often fail to balance semantic and structural information. String-based approaches capture syntactic structure but ignore semantic meaning, whereas proof-based methods validate semantic equivalence but disregard structural nuances and, critically, provide no graded similarity score in the event of proof failure. To address these issues, we introduce ASSESS (A Semantic and Structural Evaluation Framework for Statement Similarity), which comprehensively integrates semantic and structural information to provide a continuous similarity score. Our framework first transforms formal statements into Operator Trees to capture their syntactic structure and then computes a similarity score using our novel TransTED (Transformation Tree Edit Distance) Similarity metric, which enhances traditional Tree Edit Distance by incorporating semantic awareness through transformations. For rigorous validation, we present EPLA (Evaluating Provability and Likeness for Autoformalization), a new benchmark of 524 expert-annotated formal statement pairs derived from miniF2F and ProofNet, with labels for both semantic provability and structural likeness. Experiments on EPLA demonstrate that TransTED Similarity outperforms existing methods, achieving state-of-the-art accuracy and the highest Kappa coefficient. The benchmark, and implementation code will be made public soon.
Pre-training Autoencoder for Acoustic Event Classification via Blinky
Sep 18, 2025In the acoustic event classification (AEC) framework that employs Blinkies, audio signals are converted into LED light emissions and subsequently captured by a single video camera. However, the 30 fps optical transmission channel conveys only about 0.2% of the normal audio bandwidth and is highly susceptible to noise. We propose a novel sound-to-light conversion method that leverages the encoder of a pre-trained autoencoder (AE) to distill compact, discriminative features from the recorded audio. To pre-train the AE, we adopt a noise-robust learning strategy in which artificial noise is injected into the encoder's latent representations during training, thereby enhancing the model's robustness against channel noise. The encoder architecture is specifically designed for the memory footprint of contemporary edge devices such as the Raspberry Pi 4. In a simulation experiment on the ESC-50 dataset under a stringent 15 Hz bandwidth constraint, the proposed method achieved higher macro-F1 scores than conventional sound-to-light conversion approaches.
Generalized Tree Edit Distance (GTED): A Faithful Evaluation Metric for Statement Autoformalization
Jul 10, 2025Statement autoformalization, the automated translation of statement from natural language into formal languages, has become a subject of extensive research, yet the development of robust automated evaluation metrics remains limited. Existing evaluation methods often lack semantic understanding, face challenges with high computational costs, and are constrained by the current progress of automated theorem proving. To address these issues, we propose GTED (Generalized Tree Edit Distance), a novel evaluation framework that first standardizes formal statements and converts them into operator trees, then determines the semantic similarity using the eponymous GTED metric. On the miniF2F and ProofNet benchmarks, GTED outperforms all baseline metrics by achieving the highest accuracy and Kappa scores, thus providing the community with a more faithful metric for automated evaluation. The code and experimental results are available at https://github.com/XiaoyangLiu-sjtu/GTED.
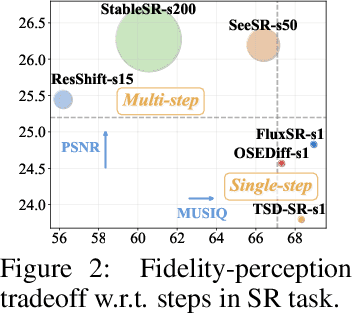
Freqformer: Image-Demoiréing Transformer via Efficient Frequency Decomposition
May 25, 2025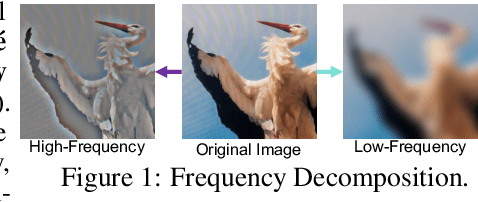

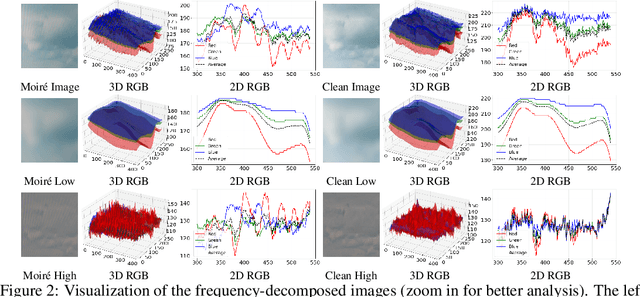
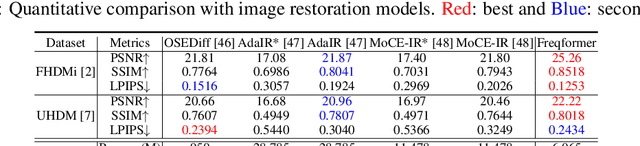
Image demoir\'eing remains a challenging task due to the complex interplay between texture corruption and color distortions caused by moir\'e patterns. Existing methods, especially those relying on direct image-to-image restoration, often fail to disentangle these intertwined artifacts effectively. While wavelet-based frequency-aware approaches offer a promising direction, their potential remains underexplored. In this paper, we present Freqformer, a Transformer-based framework specifically designed for image demoir\'eing through targeted frequency separation. Our method performs an effective frequency decomposition that explicitly splits moir\'e patterns into high-frequency spatially-localized textures and low-frequency scale-robust color distortions, which are then handled by a dual-branch architecture tailored to their distinct characteristics. We further propose a learnable Frequency Composition Transform (FCT) module to adaptively fuse the frequency-specific outputs, enabling consistent and high-fidelity reconstruction. To better aggregate the spatial dependencies and the inter-channel complementary information, we introduce a Spatial-Aware Channel Attention (SA-CA) module that refines moir\'e-sensitive regions without incurring high computational cost. Extensive experiments on various demoir\'eing benchmarks demonstrate that Freqformer achieves state-of-the-art performance with a compact model size. The code is publicly available at https://github.com/xyLiu339/Freqformer.
One-Step Diffusion Model for Image Motion-Deblurring
Mar 09, 2025
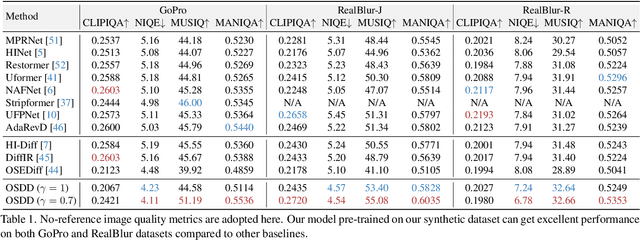

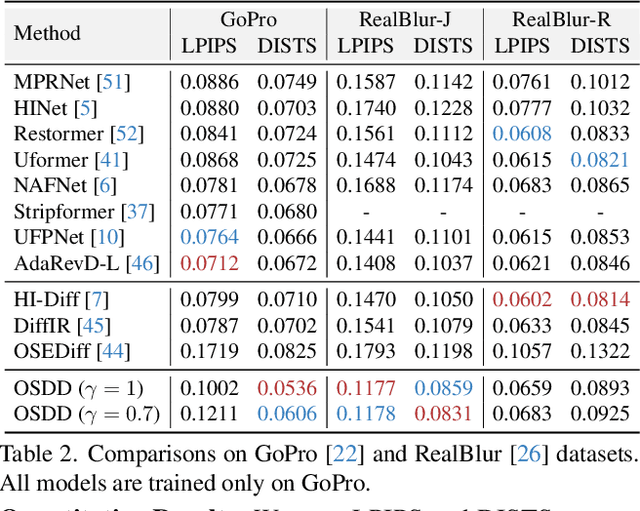
Currently, methods for single-image deblurring based on CNNs and transformers have demonstrated promising performance. However, these methods often suffer from perceptual limitations, poor generalization ability, and struggle with heavy or complex blur. While diffusion-based methods can partially address these shortcomings, their multi-step denoising process limits their practical usage. In this paper, we conduct an in-depth exploration of diffusion models in deblurring and propose a one-step diffusion model for deblurring (OSDD), a novel framework that reduces the denoising process to a single step, significantly improving inference efficiency while maintaining high fidelity. To tackle fidelity loss in diffusion models, we introduce an enhanced variational autoencoder (eVAE), which improves structural restoration. Additionally, we construct a high-quality synthetic deblurring dataset to mitigate perceptual collapse and design a dynamic dual-adapter (DDA) to enhance perceptual quality while preserving fidelity. Extensive experiments demonstrate that our method achieves strong performance on both full and no-reference metrics. Our code and pre-trained model will be publicly available at https://github.com/xyLiu339/OSDD.
ATLAS: Autoformalizing Theorems through Lifting, Augmentation, and Synthesis of Data
Feb 08, 2025Autoformalization, the process of automatically translating natural language mathematics into machine-verifiable formal language, has demonstrated advancements with the progress of large language models (LLMs). However, a key obstacle to further advancements is the scarcity of paired datasets that align natural language with formal language. To address this challenge, we introduce ATLAS (Autoformalizing Theorems through Lifting, Augmentation, and Synthesis of Data), an iterative data generation framework designed to produce large-scale, high-quality parallel theorem statements. With the proposed ATLAS running for 10 iterations, we construct an undergraduate-level dataset comprising 300k theorem statements and develop the ATLAS translator, achieving accuracies of 80.59% (pass@8) and 92.99% (pass@128) on ProofNet, significantly outperforming the base model (23.99% and 47.17%) and InternLM2-Math-Plus-7B (50.94% and 80.32%). Furthermore, the ATLAS translator also achieves state-of-the-art performance on both the high-school-level miniF2F dataset and the graduate-level MathQual dataset introduced in this work. The datasets, model, and code will be released to the public soon.