 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFideDiff: Efficient Diffusion Model for High-Fidelity Image Motion Deblurring
Oct 02, 2025


Recent advancements in image motion deblurring, driven by CNNs and transformers, have made significant progress. Large-scale pre-trained diffusion models, which are rich in true-world modeling, have shown great promise for high-quality image restoration tasks such as deblurring, demonstrating stronger generative capabilities than CNN and transformer-based methods. However, challenges such as unbearable inference time and compromised fidelity still limit the full potential of the diffusion models. To address this, we introduce FideDiff, a novel single-step diffusion model designed for high-fidelity deblurring. We reformulate motion deblurring as a diffusion-like process where each timestep represents a progressively blurred image, and we train a consistency model that aligns all timesteps to the same clean image. By reconstructing training data with matched blur trajectories, the model learns temporal consistency, enabling accurate one-step deblurring. We further enhance model performance by integrating Kernel ControlNet for blur kernel estimation and introducing adaptive timestep prediction. Our model achieves superior performance on full-reference metrics, surpassing previous diffusion-based methods and matching the performance of other state-of-the-art models. FideDiff offers a new direction for applying pre-trained diffusion models to high-fidelity image restoration tasks, establishing a robust baseline for further advancing diffusion models in real-world industrial applications. Our dataset and code will be available at https://github.com/xyLiu339/FideDiff.
Freqformer: Image-Demoiréing Transformer via Efficient Frequency Decomposition
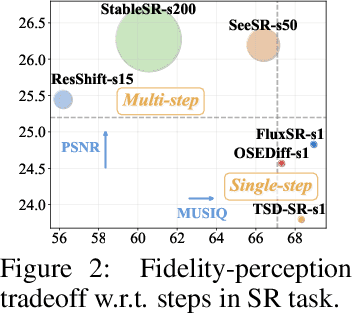
May 25, 2025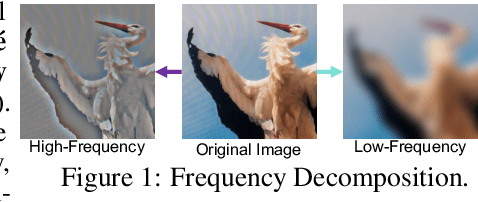

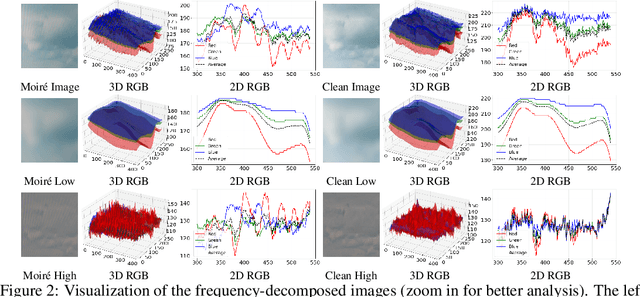
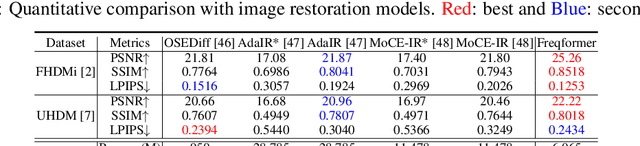
Image demoir\'eing remains a challenging task due to the complex interplay between texture corruption and color distortions caused by moir\'e patterns. Existing methods, especially those relying on direct image-to-image restoration, often fail to disentangle these intertwined artifacts effectively. While wavelet-based frequency-aware approaches offer a promising direction, their potential remains underexplored. In this paper, we present Freqformer, a Transformer-based framework specifically designed for image demoir\'eing through targeted frequency separation. Our method performs an effective frequency decomposition that explicitly splits moir\'e patterns into high-frequency spatially-localized textures and low-frequency scale-robust color distortions, which are then handled by a dual-branch architecture tailored to their distinct characteristics. We further propose a learnable Frequency Composition Transform (FCT) module to adaptively fuse the frequency-specific outputs, enabling consistent and high-fidelity reconstruction. To better aggregate the spatial dependencies and the inter-channel complementary information, we introduce a Spatial-Aware Channel Attention (SA-CA) module that refines moir\'e-sensitive regions without incurring high computational cost. Extensive experiments on various demoir\'eing benchmarks demonstrate that Freqformer achieves state-of-the-art performance with a compact model size. The code is publicly available at https://github.com/xyLiu339/Freqformer.
Q-Agent: Quality-Driven Chain-of-Thought Image Restoration Agent through Robust Multimodal Large Language Model
Apr 09, 2025Image restoration (IR) often faces various complex and unknown degradations in real-world scenarios, such as noise, blurring, compression artifacts, and low resolution, etc. Training specific models for specific degradation may lead to poor generalization. To handle multiple degradations simultaneously, All-in-One models might sacrifice performance on certain types of degradation and still struggle with unseen degradations during training. Existing IR agents rely on multimodal large language models (MLLM) and a time-consuming rolling-back selection strategy neglecting image quality. As a result, they may misinterpret degradations and have high time and computational costs to conduct unnecessary IR tasks with redundant order. To address these, we propose a Quality-Driven agent (Q-Agent) via Chain-of-Thought (CoT) restoration. Specifically, our Q-Agent consists of robust degradation perception and quality-driven greedy restoration. The former module first fine-tunes MLLM, and uses CoT to decompose multi-degradation perception into single-degradation perception tasks to enhance the perception of MLLMs. The latter employs objective image quality assessment (IQA) metrics to determine the optimal restoration sequence and execute the corresponding restoration algorithms. Experimental results demonstrate that our Q-Agent achieves superior IR performance compared to existing All-in-One models.
One-Step Diffusion Model for Image Motion-Deblurring
Mar 09, 2025
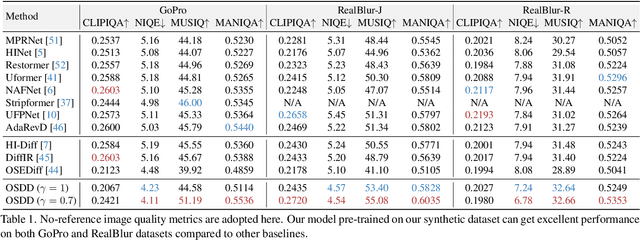

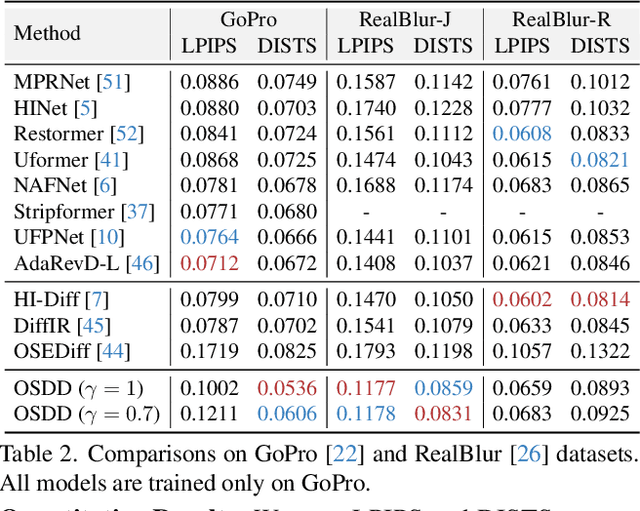
Currently, methods for single-image deblurring based on CNNs and transformers have demonstrated promising performance. However, these methods often suffer from perceptual limitations, poor generalization ability, and struggle with heavy or complex blur. While diffusion-based methods can partially address these shortcomings, their multi-step denoising process limits their practical usage. In this paper, we conduct an in-depth exploration of diffusion models in deblurring and propose a one-step diffusion model for deblurring (OSDD), a novel framework that reduces the denoising process to a single step, significantly improving inference efficiency while maintaining high fidelity. To tackle fidelity loss in diffusion models, we introduce an enhanced variational autoencoder (eVAE), which improves structural restoration. Additionally, we construct a high-quality synthetic deblurring dataset to mitigate perceptual collapse and design a dynamic dual-adapter (DDA) to enhance perceptual quality while preserving fidelity. Extensive experiments demonstrate that our method achieves strong performance on both full and no-reference metrics. Our code and pre-trained model will be publicly available at https://github.com/xyLiu339/OSDD.
One Diffusion Step to Real-World Super-Resolution via Flow Trajectory Distillation
Feb 04, 2025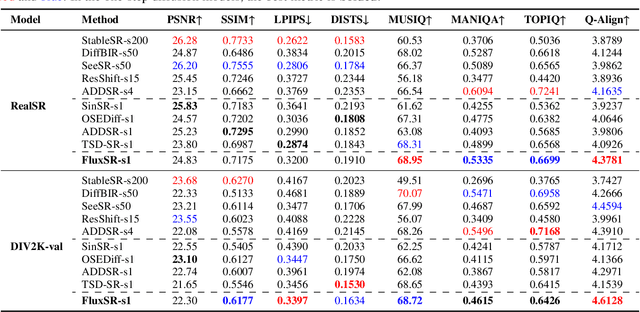
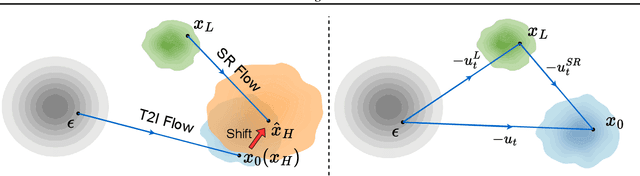
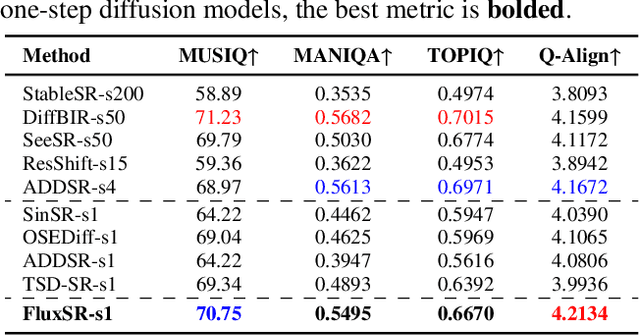
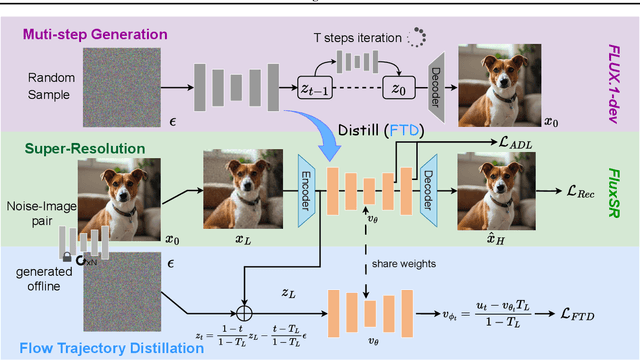
Diffusion models (DMs) have significantly advanced the development of real-world image super-resolution (Real-ISR), but the computational cost of multi-step diffusion models limits their application. One-step diffusion models generate high-quality images in a one sampling step, greatly reducing computational overhead and inference latency. However, most existing one-step diffusion methods are constrained by the performance of the teacher model, where poor teacher performance results in image artifacts. To address this limitation, we propose FluxSR, a novel one-step diffusion Real-ISR technique based on flow matching models. We use the state-of-the-art diffusion model FLUX.1-dev as both the teacher model and the base model. First, we introduce Flow Trajectory Distillation (FTD) to distill a multi-step flow matching model into a one-step Real-ISR. Second, to improve image realism and address high-frequency artifact issues in generated images, we propose TV-LPIPS as a perceptual loss and introduce Attention Diversification Loss (ADL) as a regularization term to reduce token similarity in transformer, thereby eliminating high-frequency artifacts. Comprehensive experiments demonstrate that our method outperforms existing one-step diffusion-based Real-ISR methods. The code and model will be released at https://github.com/JianzeLi-114/FluxSR.
MEMO-Bench: A Multiple Benchmark for Text-to-Image and Multimodal Large Language Models on Human Emotion Analysis
Nov 18, 2024



Artificial Intelligence (AI) has demonstrated significant capabilities in various fields, and in areas such as human-computer interaction (HCI), embodied intelligence, and the design and animation of virtual digital humans, both practitioners and users are increasingly concerned with AI's ability to understand and express emotion. Consequently, the question of whether AI can accurately interpret human emotions remains a critical challenge. To date, two primary classes of AI models have been involved in human emotion analysis: generative models and Multimodal Large Language Models (MLLMs). To assess the emotional capabilities of these two classes of models, this study introduces MEMO-Bench, a comprehensive benchmark consisting of 7,145 portraits, each depicting one of six different emotions, generated by 12 Text-to-Image (T2I) models. Unlike previous works, MEMO-Bench provides a framework for evaluating both T2I models and MLLMs in the context of sentiment analysis. Additionally, a progressive evaluation approach is employed, moving from coarse-grained to fine-grained metrics, to offer a more detailed and comprehensive assessment of the sentiment analysis capabilities of MLLMs. The experimental results demonstrate that existing T2I models are more effective at generating positive emotions than negative ones. Meanwhile, although MLLMs show a certain degree of effectiveness in distinguishing and recognizing human emotions, they fall short of human-level accuracy, particularly in fine-grained emotion analysis. The MEMO-Bench will be made publicly available to support further research in this area.
MambaSCI: Efficient Mamba-UNet for Quad-Bayer Patterned Video Snapshot Compressive Imaging
Oct 18, 2024



Color video snapshot compressive imaging (SCI) employs computational imaging techniques to capture multiple sequential video frames in a single Bayer-patterned measurement. With the increasing popularity of quad-Bayer pattern in mainstream smartphone cameras for capturing high-resolution videos, mobile photography has become more accessible to a wider audience. However, existing color video SCI reconstruction algorithms are designed based on the traditional Bayer pattern. When applied to videos captured by quad-Bayer cameras, these algorithms often result in color distortion and ineffective demosaicing, rendering them impractical for primary equipment. To address this challenge, we propose the MambaSCI method, which leverages the Mamba and UNet architectures for efficient reconstruction of quad-Bayer patterned color video SCI. To the best of our knowledge, our work presents the first algorithm for quad-Bayer patterned SCI reconstruction, and also the initial application of the Mamba model to this task. Specifically, we customize Residual-Mamba-Blocks, which residually connect the Spatial-Temporal Mamba (STMamba), Edge-Detail-Reconstruction (EDR) module, and Channel Attention (CA) module. Respectively, STMamba is used to model long-range spatial-temporal dependencies with linear complexity, EDR is for better edge-detail reconstruction, and CA is used to compensate for the missing channel information interaction in Mamba model. Experiments demonstrate that MambaSCI surpasses state-of-the-art methods with lower computational and memory costs. PyTorch style pseudo-code for the core modules is provided in the supplementary materials.
Distillation-Free One-Step Diffusion for Real-World Image Super-Resolution
Oct 05, 2024Diffusion models have been achieving excellent performance for real-world image super-resolution (Real-ISR) with considerable computational costs. Current approaches are trying to derive one-step diffusion models from multi-step counterparts through knowledge distillation. However, these methods incur substantial training costs and may constrain the performance of the student model by the teacher's limitations. To tackle these issues, we propose DFOSD, a Distillation-Free One-Step Diffusion model. Specifically, we propose a noise-aware discriminator (NAD) to participate in adversarial training, further enhancing the authenticity of the generated content. Additionally, we improve the perceptual loss with edge-aware DISTS (EA-DISTS) to enhance the model's ability to generate fine details. Our experiments demonstrate that, compared with previous diffusion-based methods requiring dozens or even hundreds of steps, our DFOSD attains comparable or even superior results in both quantitative metrics and qualitative evaluations. Our DFOSD also abtains higher performance and efficiency compared with other one-step diffusion methods. We will release code and models at \url{https://github.com/JianzeLi-114/DFOSD}.
Mipmap-GS: Let Gaussians Deform with Scale-specific Mipmap for Anti-aliasing Rendering
Aug 12, 20243D Gaussian Splatting (3DGS) has attracted great attention in novel view synthesis because of its superior rendering efficiency and high fidelity. However, the trained Gaussians suffer from severe zooming degradation due to non-adjustable representation derived from single-scale training. Though some methods attempt to tackle this problem via post-processing techniques such as selective rendering or filtering techniques towards primitives, the scale-specific information is not involved in Gaussians. In this paper, we propose a unified optimization method to make Gaussians adaptive for arbitrary scales by self-adjusting the primitive properties (e.g., color, shape and size) and distribution (e.g., position). Inspired by the mipmap technique, we design pseudo ground-truth for the target scale and propose a scale-consistency guidance loss to inject scale information into 3D Gaussians. Our method is a plug-in module, applicable for any 3DGS models to solve the zoom-in and zoom-out aliasing. Extensive experiments demonstrate the effectiveness of our method. Notably, our method outperforms 3DGS in PSNR by an average of 9.25 dB for zoom-in and 10.40 dB for zoom-out on the NeRF Synthetic dataset.
Deep Equilibrium Diffusion Restoration with Parallel Sampling
Nov 20, 2023



Diffusion-based image restoration (IR) methods aim to use diffusion models to recover high-quality (HQ) images from degraded images and achieve promising performance. Due to the inherent property of diffusion models, most of these methods need long serial sampling chains to restore HQ images step-by-step. As a result, it leads to expensive sampling time and high computation costs. Moreover, such long sampling chains hinder understanding the relationship between the restoration results and the inputs since it is hard to compute the gradients in the whole chains. In this work, we aim to rethink the diffusion-based IR models through a different perspective, i.e., a deep equilibrium (DEQ) fixed point system. Specifically, we derive an analytical solution by modeling the entire sampling chain in diffusion-based IR models as a joint multivariate fixed point system. With the help of the analytical solution, we are able to conduct single-image sampling in a parallel way and restore HQ images without training. Furthermore, we compute fast gradients in DEQ and found that initialization optimization can boost performance and control the generation direction. Extensive experiments on benchmarks demonstrate the effectiveness of our proposed method on typical IR tasks and real-world settings. The code and models will be made publicly available.