 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
May 13, 2026Text image super-resolution (Text-SR) requires more than visually plausible detail synthesis: slight errors in stroke topology may alter character identity and break readability. Existing methods improve text fidelity with stronger recognition-based or generative priors, yet they still face two unresolved challenges under severe degradation: the text condition extracted from low-quality inputs can itself be unreliable, and a plausible global prior does not fully determine fine-grained stroke boundaries. We present PRISM, a single-step diffusion-based Text-SR framework that addresses these two challenges through Flow-Matching Prior Rectification (FMPR) and a Structure-guided Uncertainty-aware Residual Encoder (SURE). FMPR constructs a privileged training-time prior from paired low-quality/high-quality latents and learns a flow matching that transports degraded embeddings toward this restoration-oriented prior space, yielding more accurate and reliable global text guidance. SURE further predicts uncertainty-aware structural residuals to selectively absorb reliable local boundary evidence while suppressing ambiguous stroke cues. Together, these components enable explicit global prior rectification and local structure refinement within a single diffusion restoration pass. Experiments on both synthetic and real-world benchmarks show that PRISM achieves state-of-the-art performance with millisecond-level inference. Our dataset and code will be available at https://github.com/faithxuz/PRISM.
Stable Adaptive Thinking via Advantage Shaping and Length-Aware Gradient Regulation
Feb 26, 2026Large reasoning models (LRMs) achieve strong performance through extended reasoning traces, but they often exhibit overthinking behavior for low-complexity queries. Existing efforts to mitigate this issue are fundamentally limited by unstable accuracy-efficiency trade-offs and poor robustness to heterogeneous reasoning behaviors. To address these challenges, we propose a two-stage framework for stable adaptive thinking in LRMs. The framework first applies Hybrid Fine-Tuning to expose the model to both thinking and no-thinking behaviors, establishing well-conditioned initialization. It then performs adaptive reinforcement learning with Correctness-Preserving Advantage Shaping (CPAS) to avoid suppressing correct long-chain reasoning, and Length-Aware Gradient Regulation (LAGR) to stabilize optimization under severe reasoning-length heterogeneity. Extensive experiments on Qwen2.5-1.5B and 7B show consistent improvements over strong baselines, achieving up to +3.7/+3.6 accuracy points while reducing generated tokens by 40.6%/43.9%. Further analyses across varying problem difficulties and out-of-distribution tasks confirm the robustness and generalization of our approach.
FideDiff: Efficient Diffusion Model for High-Fidelity Image Motion Deblurring
Oct 02, 2025

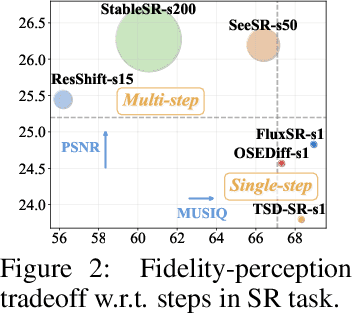

Recent advancements in image motion deblurring, driven by CNNs and transformers, have made significant progress. Large-scale pre-trained diffusion models, which are rich in true-world modeling, have shown great promise for high-quality image restoration tasks such as deblurring, demonstrating stronger generative capabilities than CNN and transformer-based methods. However, challenges such as unbearable inference time and compromised fidelity still limit the full potential of the diffusion models. To address this, we introduce FideDiff, a novel single-step diffusion model designed for high-fidelity deblurring. We reformulate motion deblurring as a diffusion-like process where each timestep represents a progressively blurred image, and we train a consistency model that aligns all timesteps to the same clean image. By reconstructing training data with matched blur trajectories, the model learns temporal consistency, enabling accurate one-step deblurring. We further enhance model performance by integrating Kernel ControlNet for blur kernel estimation and introducing adaptive timestep prediction. Our model achieves superior performance on full-reference metrics, surpassing previous diffusion-based methods and matching the performance of other state-of-the-art models. FideDiff offers a new direction for applying pre-trained diffusion models to high-fidelity image restoration tasks, establishing a robust baseline for further advancing diffusion models in real-world industrial applications. Our dataset and code will be available at https://github.com/xyLiu339/FideDiff.
JoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing
Jan 03, 2025



Significant progress has been made in talking-face video generation research; however, precise lip-audio synchronization and high visual quality remain challenging in editing lip shapes based on input audio. This paper introduces JoyGen, a novel two-stage framework for talking-face generation, comprising audio-driven lip motion generation and visual appearance synthesis. In the first stage, a 3D reconstruction model and an audio2motion model predict identity and expression coefficients respectively. Next, by integrating audio features with a facial depth map, we provide comprehensive supervision for precise lip-audio synchronization in facial generation. Additionally, we constructed a Chinese talking-face dataset containing 130 hours of high-quality video. JoyGen is trained on the open-source HDTF dataset and our curated dataset. Experimental results demonstrate superior lip-audio synchronization and visual quality achieved by our method.
Defining Boundaries: A Spectrum of Task Feasibility for Large Language Models
Aug 11, 2024Large language models (LLMs) have shown remarkable performance in various tasks but often fail to handle queries that exceed their knowledge and capabilities, leading to incorrect or fabricated responses. This paper addresses the need for LLMs to recognize and refuse infeasible tasks due to the required skills surpassing their capabilities. We first systematically conceptualize infeasible tasks for LLMs, providing formal definitions and categorizations that cover a spectrum of related hallucinations. We develop and benchmark a new dataset comprising diverse infeasible and feasible tasks to test multiple LLMs' abilities on task feasibility. Furthermore, we explore the potential of training enhancements to increase LLMs' refusal capabilities with fine-tuning. Experiments validate the effectiveness of our methods, offering promising directions for refining the operational boundaries of LLMs in real applications.
Beyond the Turn-Based Game: Enabling Real-Time Conversations with Duplex Models
Jun 22, 2024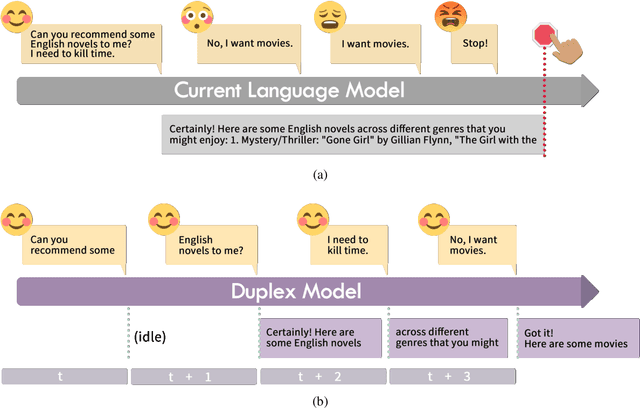
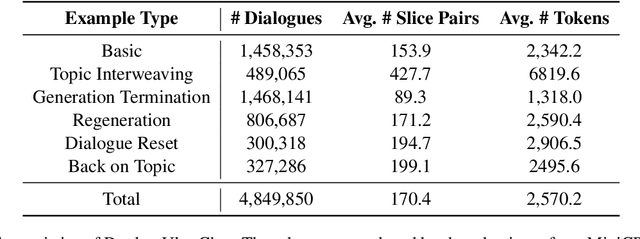

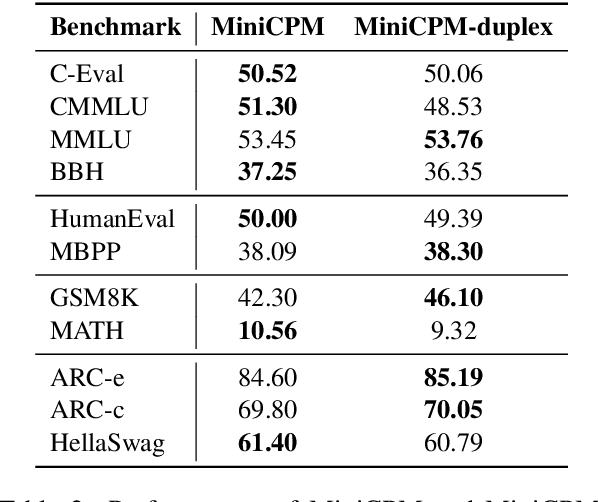
As large language models (LLMs) increasingly permeate daily lives, there is a growing demand for real-time interactions that mirror human conversations. Traditional turn-based chat systems driven by LLMs prevent users from verbally interacting with the system while it is generating responses. To overcome these limitations, we adapt existing LLMs to \textit{duplex models} so that these LLMs can listen for users while generating output and dynamically adjust themselves to provide users with instant feedback. % such as in response to interruptions. Specifically, we divide the queries and responses of conversations into several time slices and then adopt a time-division-multiplexing (TDM) encoding-decoding strategy to pseudo-simultaneously process these slices. Furthermore, to make LLMs proficient enough to handle real-time conversations, we build a fine-tuning dataset consisting of alternating time slices of queries and responses as well as covering typical feedback types in instantaneous interactions. Our experiments show that although the queries and responses of conversations are segmented into incomplete slices for processing, LLMs can preserve their original performance on standard benchmarks with a few fine-tuning steps on our dataset. Automatic and human evaluation indicate that duplex models make user-AI interactions more natural and human-like, and greatly improve user satisfaction compared to vanilla LLMs. Our duplex model and dataset will be released.
$\infty$Bench: Extending Long Context Evaluation Beyond 100K Tokens
Feb 24, 2024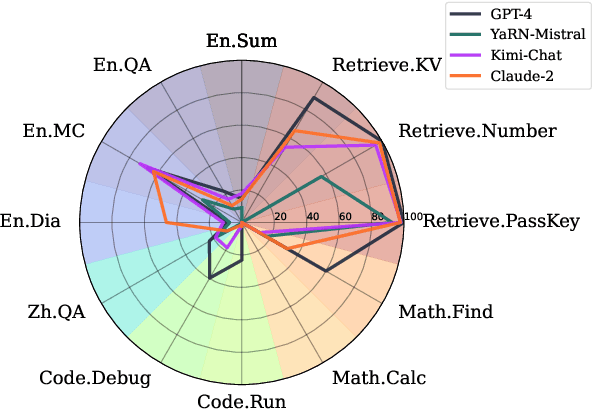
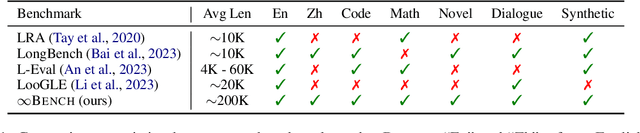
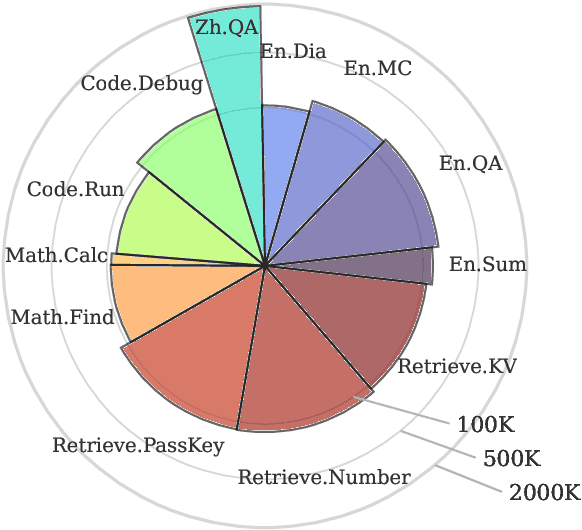
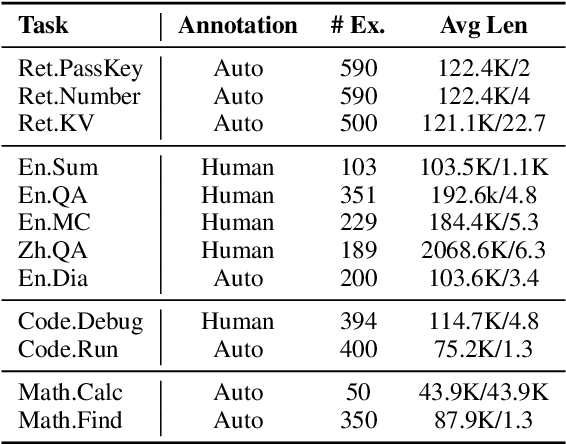
Processing and reasoning over long contexts is crucial for many practical applications of Large Language Models (LLMs), such as document comprehension and agent construction. Despite recent strides in making LLMs process contexts with more than 100K tokens, there is currently a lack of a standardized benchmark to evaluate this long-context capability. Existing public benchmarks typically focus on contexts around 10K tokens, limiting the assessment and comparison of LLMs in processing longer contexts. In this paper, we propose $\infty$Bench, the first LLM benchmark featuring an average data length surpassing 100K tokens. $\infty$Bench comprises synthetic and realistic tasks spanning diverse domains, presented in both English and Chinese. The tasks in $\infty$Bench are designed to require well understanding of long dependencies in contexts, and make simply retrieving a limited number of passages from contexts not sufficient for these tasks. In our experiments, based on $\infty$Bench, we evaluate the state-of-the-art proprietary and open-source LLMs tailored for processing long contexts. The results indicate that existing long context LLMs still require significant advancements to effectively process 100K+ context. We further present three intriguing analyses regarding the behavior of LLMs processing long context.
Generative Input: Towards Next-Generation Input Methods Paradigm
Nov 02, 2023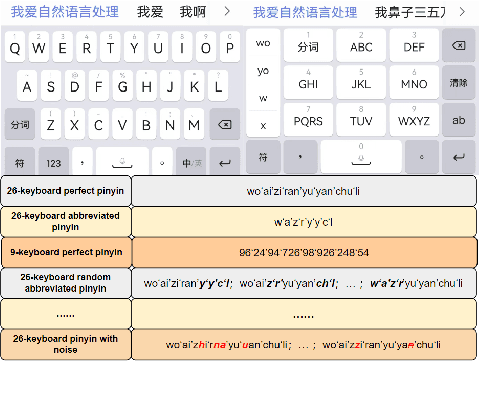
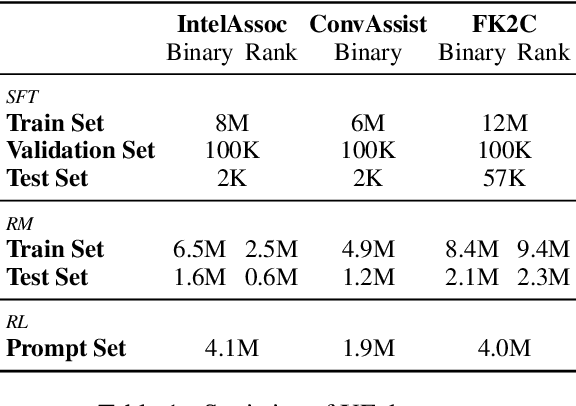
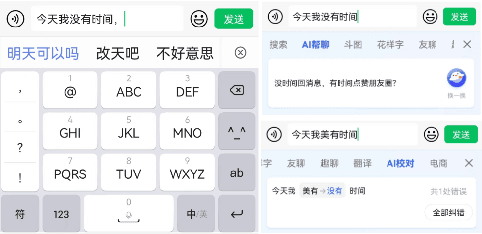

Since the release of ChatGPT, generative models have achieved tremendous success and become the de facto approach for various NLP tasks. However, its application in the field of input methods remains under-explored. Many neural network approaches have been applied to the construction of Chinese input method engines(IMEs).Previous research often assumed that the input pinyin was correct and focused on Pinyin-to-character(P2C) task, which significantly falls short of meeting users' demands. Moreover, previous research could not leverage user feedback to optimize the model and provide personalized results. In this study, we propose a novel Generative Input paradigm named GeneInput. It uses prompts to handle all input scenarios and other intelligent auxiliary input functions, optimizing the model with user feedback to deliver personalized results. The results demonstrate that we have achieved state-of-the-art performance for the first time in the Full-mode Key-sequence to Characters(FK2C) task. We propose a novel reward model training method that eliminates the need for additional manual annotations and the performance surpasses GPT-4 in tasks involving intelligent association and conversational assistance. Compared to traditional paradigms, GeneInput not only demonstrates superior performance but also exhibits enhanced robustness, scalability, and online learning capabilities.
ASC: Appearance and Structure Consistency for Unsupervised Domain Adaptation in Fetal Brain MRI Segmentation
Oct 22, 2023Automatic tissue segmentation of fetal brain images is essential for the quantitative analysis of prenatal neurodevelopment. However, producing voxel-level annotations of fetal brain imaging is time-consuming and expensive. To reduce labeling costs, we propose a practical unsupervised domain adaptation (UDA) setting that adapts the segmentation labels of high-quality fetal brain atlases to unlabeled fetal brain MRI data from another domain. To address the task, we propose a new UDA framework based on Appearance and Structure Consistency, named ASC. We adapt the segmentation model to the appearances of different domains by constraining the consistency before and after a frequency-based image transformation, which is to swap the appearance between brain MRI data and atlases. Consider that even in the same domain, the fetal brain images of different gestational ages could have significant variations in the anatomical structures. To make the model adapt to the structural variations in the target domain, we further encourage prediction consistency under different structural perturbations. Extensive experiments on FeTA 2021 benchmark demonstrate the effectiveness of our ASC in comparison to registration-based, semi-supervised learning-based, and existing UDA-based methods.
IDOL: Indicator-oriented Logic Pre-training for Logical Reasoning
Jun 27, 2023



In the field of machine reading comprehension (MRC), existing systems have surpassed the average performance of human beings in many tasks like SQuAD. However, there is still a long way to go when it comes to logical reasoning. Although some methods for it have been put forward, they either are designed in a quite complicated way or rely too much on external structures. In this paper, we proposed IDOL (InDicator-Oriented Logic Pre-training), an easy-to-understand but highly effective further pre-training task which logically strengthens the pre-trained models with the help of 6 types of logical indicators and a logically rich dataset LGP (LoGic Pre-training). IDOL achieves state-of-the-art performance on ReClor and LogiQA, the two most representative benchmarks in logical reasoning MRC, and is proven to be capable of generalizing to different pre-trained models and other types of MRC benchmarks like RACE and SQuAD 2.0 while keeping competitive general language understanding ability through testing on tasks in GLUE. Besides, at the beginning of the era of large language models, we take several of them like ChatGPT into comparison and find that IDOL still shows its advantage.