 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine-Tuning versus Reinforcement Learning: A Study of Post-Training Methods for Large Language Models
Mar 14, 2026Pre-trained Large Language Model (LLM) exhibits broad capabilities, yet, for specific tasks or domains their attainment of higher accuracy and more reliable reasoning generally depends on post-training through Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). Although often treated as distinct methodologies, recent theoretical and empirical developments demonstrate that SFT and RL are closely connected. This study presents a comprehensive and unified perspective on LLM post-training with SFT and RL. We first provide an in-depth overview of both techniques, examining their objectives, algorithmic structures, and data requirements. We then systematically analyze their interplay, highlighting frameworks that integrate SFT and RL, hybrid training pipelines, and methods that leverage their complementary strengths. Drawing on a representative set of recent application studies from 2023 to 2025, we identify emerging trends, characterize the rapid shift toward hybrid post-training paradigms, and distill key takeaways that clarify when and why each method is most effective. By synthesizing theoretical insights, practical methodologies, and empirical evidence, this study establishes a coherent understanding of SFT and RL within a unified framework and outlines promising directions for future research in scalable, efficient, and generalizable LLM post-training.
PABU: Progress-Aware Belief Update for Efficient LLM Agents
Feb 09, 2026Large Language Model (LLM) agents commonly condition actions on full action-observation histories, which introduce task-irrelevant information that easily leads to redundant actions and higher inference cost. We propose Progress-Aware Belief Update (PABU), a belief-state framework that compactly represents an agent's state by explicitly modeling task progress and selectively retaining past actions and observations. At each step, the agent predicts its relative progress since the previous round and decides whether the newly encountered interaction should be stored, conditioning future decisions only on the retained subset. Across eight environments in the AgentGym benchmark, and using identical training trajectories, PABU achieves an 81.0% task completion rate, outperforming previous State of the art (SoTA) models with full-history belief by 23.9%. Additionally, PABU's progress-oriented action selection improves efficiency, reducing the average number of interaction steps to 9.5, corresponding to a 26.9% reduction. Ablation studies show that both explicit progress prediction and selective retention are necessary for robust belief learning and performance gains.
Time-Varying Home Field Advantage in Football: Learning from a Non-Stationary Causal Process
Jun 13, 2025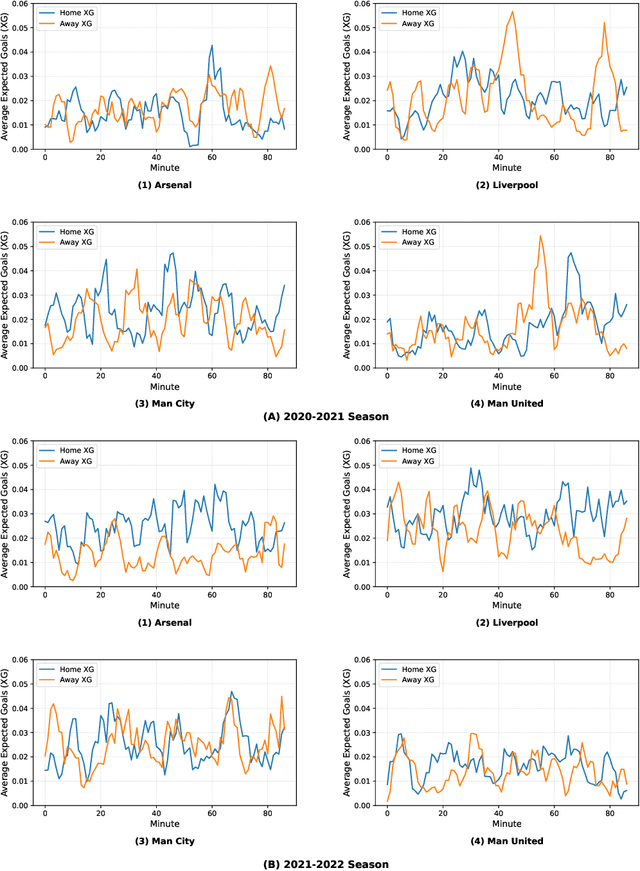



In sports analytics, home field advantage is a robust phenomenon where the home team wins more games than the away team. However, discovering the causal factors behind home field advantage presents unique challenges due to the non-stationary, time-varying environment of sports matches. In response, we propose a novel causal discovery method, DYnamic Non-stAtionary local M-estimatOrs (DYNAMO), to learn the time-varying causal structures of home field advantage. DYNAMO offers flexibility by integrating various loss functions, making it practical for learning linear and non-linear causal structures from a general class of non-stationary causal processes. By leveraging local information, we provide theoretical guarantees for the identifiability and estimation consistency of non-stationary causal structures without imposing additional assumptions. Simulation studies validate the efficacy of DYNAMO in recovering time-varying causal structures. We apply our method to high-resolution event data from the 2020-2021 and 2021-2022 English Premier League seasons, during which the former season had no audience presence. Our results reveal intriguing, time-varying, team-specific field advantages influenced by referee bias, which differ significantly with and without crowd support. Furthermore, the time-varying causal structures learned by our method improve goal prediction accuracy compared to existing methods.
A Review of Causal Decision Making
Feb 22, 2025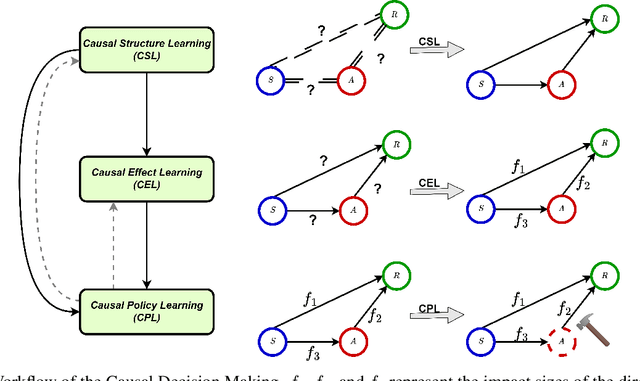

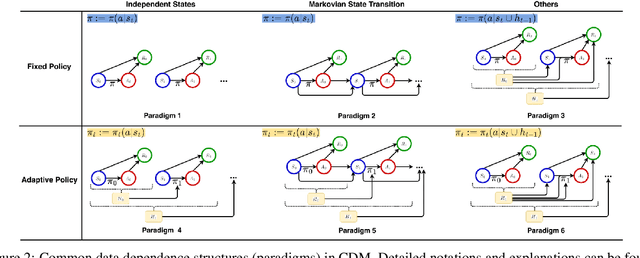
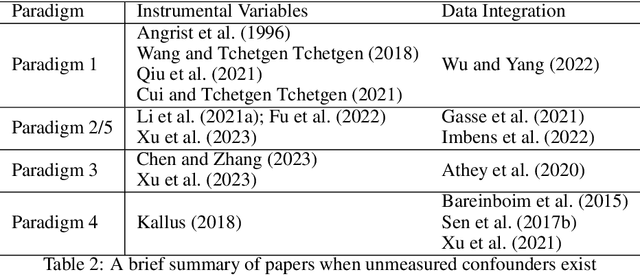
To make effective decisions, it is important to have a thorough understanding of the causal relationships among actions, environments, and outcomes. This review aims to surface three crucial aspects of decision-making through a causal lens: 1) the discovery of causal relationships through causal structure learning, 2) understanding the impacts of these relationships through causal effect learning, and 3) applying the knowledge gained from the first two aspects to support decision making via causal policy learning. Moreover, we identify challenges that hinder the broader utilization of causal decision-making and discuss recent advances in overcoming these challenges. Finally, we provide future research directions to address these challenges and to further enhance the implementation of causal decision-making in practice, with real-world applications illustrated based on the proposed causal decision-making. We aim to offer a comprehensive methodology and practical implementation framework by consolidating various methods in this area into a Python-based collection. URL: https://causaldm.github.io/Causal-Decision-Making.
Beyond the Singular: The Essential Role of Multiple Generations in Effective Benchmark Evaluation and Analysis
Feb 13, 2025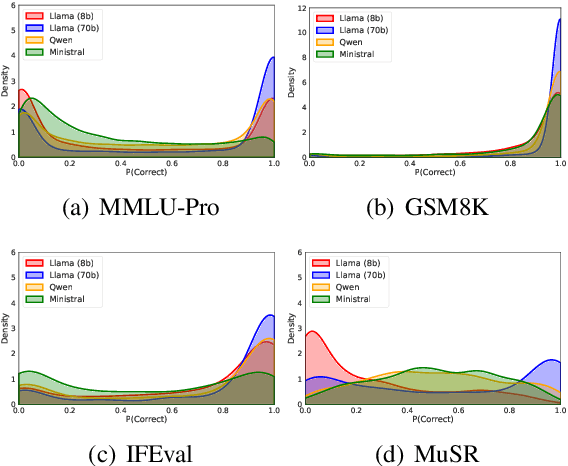
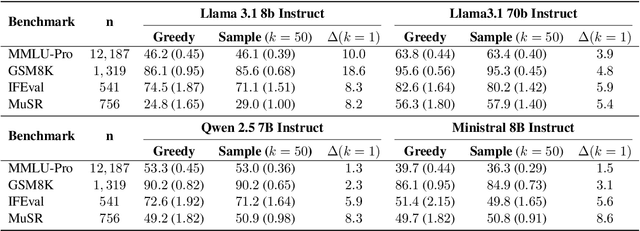
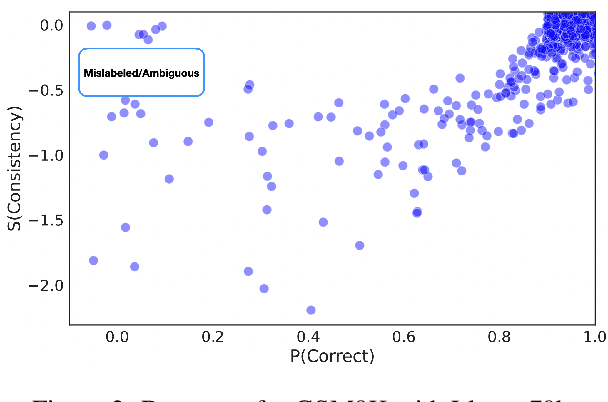
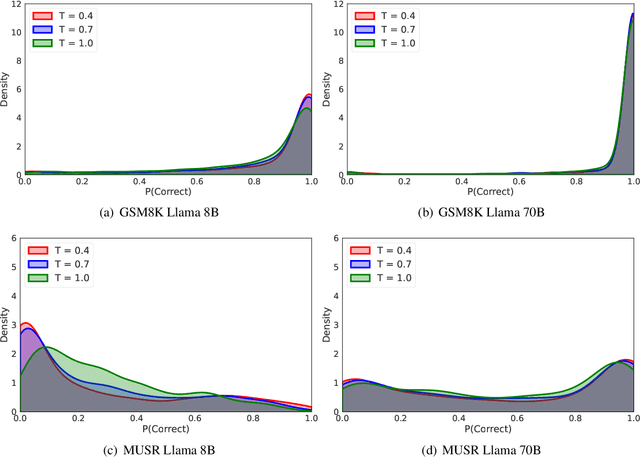
Large language models (LLMs) have demonstrated significant utilities in real-world applications, exhibiting impressive capabilities in natural language processing and understanding. Benchmark evaluations are crucial for assessing the capabilities of LLMs as they can provide a comprehensive assessment of their strengths and weaknesses. However, current evaluation methods often overlook the inherent randomness of LLMs by employing deterministic generation strategies or relying on a single random sample, resulting in unaccounted sampling variance and unreliable benchmark score estimates. In this paper, we propose a hierarchical statistical model that provides a more comprehensive representation of the benchmarking process by incorporating both benchmark characteristics and LLM randomness. We show that leveraging multiple generations improves the accuracy of estimating the benchmark score and reduces variance. We also introduce $\mathbb P\left(\text{correct}\right)$, a prompt-level difficulty score based on correct ratios, providing fine-grained insights into individual prompts. Additionally, we create a data map that visualizes difficulty and semantic prompts, enabling error detection and quality control in benchmark construction.
Defining Boundaries: A Spectrum of Task Feasibility for Large Language Models
Aug 11, 2024Large language models (LLMs) have shown remarkable performance in various tasks but often fail to handle queries that exceed their knowledge and capabilities, leading to incorrect or fabricated responses. This paper addresses the need for LLMs to recognize and refuse infeasible tasks due to the required skills surpassing their capabilities. We first systematically conceptualize infeasible tasks for LLMs, providing formal definitions and categorizations that cover a spectrum of related hallucinations. We develop and benchmark a new dataset comprising diverse infeasible and feasible tasks to test multiple LLMs' abilities on task feasibility. Furthermore, we explore the potential of training enhancements to increase LLMs' refusal capabilities with fine-tuning. Experiments validate the effectiveness of our methods, offering promising directions for refining the operational boundaries of LLMs in real applications.
Conformal Diffusion Models for Individual Treatment Effect Estimation and Inference
Aug 02, 2024Estimating treatment effects from observational data is of central interest across numerous application domains. Individual treatment effect offers the most granular measure of treatment effect on an individual level, and is the most useful to facilitate personalized care. However, its estimation and inference remain underdeveloped due to several challenges. In this article, we propose a novel conformal diffusion model-based approach that addresses those intricate challenges. We integrate the highly flexible diffusion modeling, the model-free statistical inference paradigm of conformal inference, along with propensity score and covariate local approximation that tackle distributional shifts. We unbiasedly estimate the distributions of potential outcomes for individual treatment effect, construct an informative confidence interval, and establish rigorous theoretical guarantees. We demonstrate the competitive performance of the proposed method over existing solutions through extensive numerical studies.
Is Knowledge All Large Language Models Needed for Causal Reasoning?
Dec 30, 2023



This paper explores the causal reasoning of large language models (LLMs) to enhance their interpretability and reliability in advancing artificial intelligence. Despite the proficiency of LLMs in a range of tasks, their potential for understanding causality requires further exploration. We propose a novel causal attribution model that utilizes "do-operators" for constructing counterfactual scenarios, allowing us to systematically quantify the influence of input numerical data and LLMs' pre-existing knowledge on their causal reasoning processes. Our newly developed experimental setup assesses LLMs' reliance on contextual information and inherent knowledge across various domains. Our evaluation reveals that LLMs' causal reasoning ability depends on the context and domain-specific knowledge provided, and supports the argument that "knowledge is, indeed, what LLMs principally require for sound causal reasoning". On the contrary, in the absence of knowledge, LLMs still maintain a degree of causal reasoning using the available numerical data, albeit with limitations in the calculations.
Towards Trustworthy Explanation: On Causal Rationalization
Jun 25, 2023With recent advances in natural language processing, rationalization becomes an essential self-explaining diagram to disentangle the black box by selecting a subset of input texts to account for the major variation in prediction. Yet, existing association-based approaches on rationalization cannot identify true rationales when two or more snippets are highly inter-correlated and thus provide a similar contribution to prediction accuracy, so-called spuriousness. To address this limitation, we novelly leverage two causal desiderata, non-spuriousness and efficiency, into rationalization from the causal inference perspective. We formally define a series of probabilities of causation based on a newly proposed structural causal model of rationalization, with its theoretical identification established as the main component of learning necessary and sufficient rationales. The superior performance of the proposed causal rationalization is demonstrated on real-world review and medical datasets with extensive experiments compared to state-of-the-art methods.
Sequential Knockoffs for Variable Selection in Reinforcement Learning
Mar 24, 2023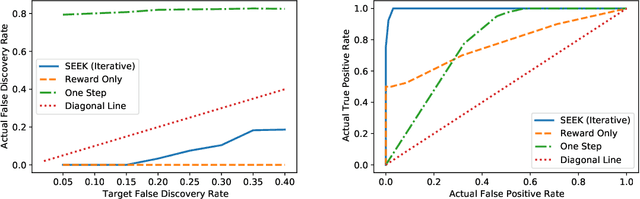


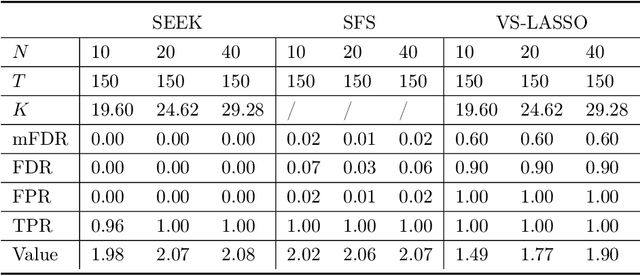
In real-world applications of reinforcement learning, it is often challenging to obtain a state representation that is parsimonious and satisfies the Markov property without prior knowledge. Consequently, it is common practice to construct a state which is larger than necessary, e.g., by concatenating measurements over contiguous time points. However, needlessly increasing the dimension of the state can slow learning and obfuscate the learned policy. We introduce the notion of a minimal sufficient state in a Markov decision process (MDP) as the smallest subvector of the original state under which the process remains an MDP and shares the same optimal policy as the original process. We propose a novel sequential knockoffs (SEEK) algorithm that estimates the minimal sufficient state in a system with high-dimensional complex nonlinear dynamics. In large samples, the proposed method controls the false discovery rate, and selects all sufficient variables with probability approaching one. As the method is agnostic to the reinforcement learning algorithm being applied, it benefits downstream tasks such as policy optimization. Empirical experiments verify theoretical results and show the proposed approach outperforms several competing methods in terms of variable selection accuracy and regret.