 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoBrain: Learning Adaptive Frame Sampling for Long Video Understanding
Feb 04, 2026Long-form video understanding remains challenging for Vision-Language Models (VLMs) due to the inherent tension between computational constraints and the need to capture information distributed across thousands of frames. Existing approaches either sample frames uniformly (risking information loss) or select keyframes in a single pass (with no recovery from poor choices). We propose VideoBrain, an end-to-end framework that enables VLMs to adaptively acquire visual information through learned sampling policies. Our approach features dual complementary agents: a CLIP-based agent for semantic retrieval across the video and a Uniform agent for dense temporal sampling within intervals. Unlike prior agent-based methods that rely on text-only LLMs orchestrating visual tools, our VLM directly perceives frames and reasons about information sufficiency. To prevent models from invoking agents indiscriminately to maximize rewards, we introduce a behavior-aware reward function coupled with a data classification pipeline that teaches the model when agent invocation is genuinely beneficial. Experiments on four long video benchmarks demonstrate that VideoBrain achieves +3.5% to +9.0% improvement over the baseline while using 30-40% fewer frames, with strong cross-dataset generalization to short video benchmarks.
DeepSport: A Multimodal Large Language Model for Comprehensive Sports Video Reasoning via Agentic Reinforcement Learning
Nov 17, 2025Sports video understanding presents unique challenges, requiring models to perceive high-speed dynamics, comprehend complex rules, and reason over long temporal contexts. While Multimodal Large Language Models (MLLMs) have shown promise in genral domains, the current state of research in sports remains narrowly focused: existing approaches are either single-sport centric, limited to specific tasks, or rely on training-free paradigms that lack robust, learned reasoning process. To address this gap, we introduce DeepSport, the first end-to-end trained MLLM framework designed for multi-task, multi-sport video understanding. DeepSport shifts the paradigm from passive frame processing to active, iterative reasoning, empowering the model to ``think with videos'' by dynamically interrogating content via a specialized frame-extraction tool. To enable this, we propose a data distillation pipeline that synthesizes high-quality Chain-of-Thought (CoT) trajectories from 10 diverse data source, creating a unified resource of 78k training data. We then employ a two-stage training strategy, Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) with a novel gated tool-use reward, to optimize the model's reasoning process. Extensive experiments on the testing benchmark of 6.7k questions demonstrate that DeepSport achieves state-of-the-art performance, significantly outperforming baselines of both proprietary model and open-source models. Our work establishes a new foundation for domain-specific video reasoning to address the complexities of diverse sports.
SportR: A Benchmark for Multimodal Large Language Model Reasoning in Sports
Nov 17, 2025Deeply understanding sports requires an intricate blend of fine-grained visual perception and rule-based reasoning - a challenge that pushes the limits of current multimodal models. To succeed, models must master three critical capabilities: perceiving nuanced visual details, applying abstract sport rule knowledge, and grounding that knowledge in specific visual evidence. Current sports benchmarks either cover single sports or lack the detailed reasoning chains and precise visual grounding needed to robustly evaluate these core capabilities in a multi-sport context. To address this gap, we introduce SportR, the first multi-sports large-scale benchmark designed to train and evaluate MLLMs on the fundamental reasoning required for sports intelligence. Our benchmark provides a dataset of 5,017 images and 2,101 videos. To enable granular evaluation, we structure our benchmark around a progressive hierarchy of question-answer (QA) pairs designed to probe reasoning at increasing depths - from simple infraction identification to complex penalty prediction. For the most advanced tasks requiring multi-step reasoning, such as determining penalties or explaining tactics, we provide 7,118 high-quality, human-authored Chain of Thought (CoT) annotations. In addition, our benchmark incorporates both image and video modalities and provides manual bounding box annotations to test visual grounding in the image part directly. Extensive experiments demonstrate the profound difficulty of our benchmark. State-of-the-art baseline models perform poorly on our most challenging tasks. While training on our data via Supervised Fine-Tuning and Reinforcement Learning improves these scores, they remain relatively low, highlighting a significant gap in current model capabilities. SportR presents a new challenge for the community, providing a critical resource to drive future research in multimodal sports reasoning.
LightAgent: Production-level Open-source Agentic AI Framework
Sep 11, 2025With the rapid advancement of large language models (LLMs), Multi-agent Systems (MAS) have achieved significant progress in various application scenarios. However, substantial challenges remain in designing versatile, robust, and efficient platforms for agent deployment. To address these limitations, we propose \textbf{LightAgent}, a lightweight yet powerful agentic framework, effectively resolving the trade-off between flexibility and simplicity found in existing frameworks. LightAgent integrates core functionalities such as Memory (mem0), Tools, and Tree of Thought (ToT), while maintaining an extremely lightweight structure. As a fully open-source solution, it seamlessly integrates with mainstream chat platforms, enabling developers to easily build self-learning agents. We have released LightAgent at \href{https://github.com/wxai-space/LightAgent}{https://github.com/wxai-space/LightAgent}
Time-Varying Home Field Advantage in Football: Learning from a Non-Stationary Causal Process
Jun 13, 2025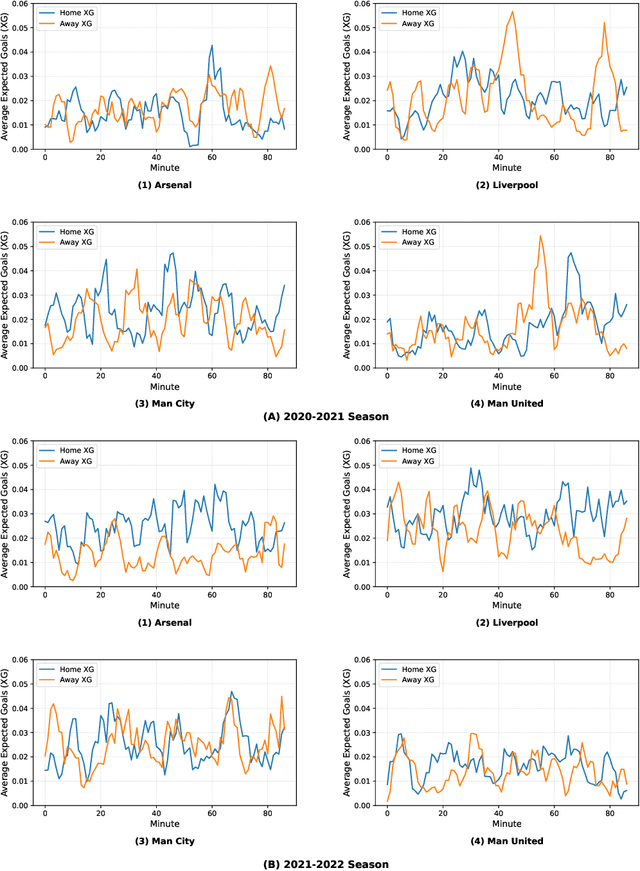



In sports analytics, home field advantage is a robust phenomenon where the home team wins more games than the away team. However, discovering the causal factors behind home field advantage presents unique challenges due to the non-stationary, time-varying environment of sports matches. In response, we propose a novel causal discovery method, DYnamic Non-stAtionary local M-estimatOrs (DYNAMO), to learn the time-varying causal structures of home field advantage. DYNAMO offers flexibility by integrating various loss functions, making it practical for learning linear and non-linear causal structures from a general class of non-stationary causal processes. By leveraging local information, we provide theoretical guarantees for the identifiability and estimation consistency of non-stationary causal structures without imposing additional assumptions. Simulation studies validate the efficacy of DYNAMO in recovering time-varying causal structures. We apply our method to high-resolution event data from the 2020-2021 and 2021-2022 English Premier League seasons, during which the former season had no audience presence. Our results reveal intriguing, time-varying, team-specific field advantages influenced by referee bias, which differ significantly with and without crowd support. Furthermore, the time-varying causal structures learned by our method improve goal prediction accuracy compared to existing methods.
From Images to Detection: Machine Learning for Blood Pattern Classification
Jan 04, 2025



Bloodstain Pattern Analysis (BPA) helps us understand how bloodstains form, with a focus on their size, shape, and distribution. This aids in crime scene reconstruction and provides insight into victim positions and crime investigation. One challenge in BPA is distinguishing between different types of bloodstains, such as those from firearms, impacts, or other mechanisms. Our study focuses on differentiating impact spatter bloodstain patterns from gunshot bloodstain patterns. We distinguish patterns by extracting well-designed individual stain features, applying effective data consolidation methods, and selecting boosting classifiers. As a result, we have developed a model that excels in both accuracy and efficiency. In addition, we use outside data sources from previous studies to discuss the challenges and future directions for BPA.
SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
Oct 11, 2024



Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.
Sports Intelligence: Assessing the Sports Understanding Capabilities of Language Models through Question Answering from Text to Video
Jun 21, 2024Understanding sports is crucial for the advancement of Natural Language Processing (NLP) due to its intricate and dynamic nature. Reasoning over complex sports scenarios has posed significant challenges to current NLP technologies which require advanced cognitive capabilities. Toward addressing the limitations of existing benchmarks on sports understanding in the NLP field, we extensively evaluated mainstream large language models for various sports tasks. Our evaluation spans from simple queries on basic rules and historical facts to complex, context-specific reasoning, leveraging strategies from zero-shot to few-shot learning, and chain-of-thought techniques. In addition to unimodal analysis, we further assessed the sports reasoning capabilities of mainstream video language models to bridge the gap in multimodal sports understanding benchmarking. Our findings highlighted the critical challenges of sports understanding for NLP. We proposed a new benchmark based on a comprehensive overview of existing sports datasets and provided extensive error analysis which we hope can help identify future research priorities in this field.
Language and Multimodal Models in Sports: A Survey of Datasets and Applications
Jun 18, 2024

Recent integration of Natural Language Processing (NLP) and multimodal models has advanced the field of sports analytics. This survey presents a comprehensive review of the datasets and applications driving these innovations post-2020. We overviewed and categorized datasets into three primary types: language-based, multimodal, and convertible datasets. Language-based and multimodal datasets are for tasks involving text or multimodality (e.g., text, video, audio), respectively. Convertible datasets, initially single-modal (video), can be enriched with additional annotations, such as explanations of actions and video descriptions, to become multimodal, offering future potential for richer and more diverse applications. Our study highlights the contributions of these datasets to various applications, from improving fan experiences to supporting tactical analysis and medical diagnostics. We also discuss the challenges and future directions in dataset development, emphasizing the need for diverse, high-quality data to support real-time processing and personalized user experiences. This survey provides a foundational resource for researchers and practitioners aiming to leverage NLP and multimodal models in sports, offering insights into current trends and future opportunities in the field.
SportQA: A Benchmark for Sports Understanding in Large Language Models
Feb 24, 2024



A deep understanding of sports, a field rich in strategic and dynamic content, is crucial for advancing Natural Language Processing (NLP). This holds particular significance in the context of evaluating and advancing Large Language Models (LLMs), given the existing gap in specialized benchmarks. To bridge this gap, we introduce SportQA, a novel benchmark specifically designed for evaluating LLMs in the context of sports understanding. SportQA encompasses over 70,000 multiple-choice questions across three distinct difficulty levels, each targeting different aspects of sports knowledge from basic historical facts to intricate, scenario-based reasoning tasks. We conducted a thorough evaluation of prevalent LLMs, mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting. Our results reveal that while LLMs exhibit competent performance in basic sports knowledge, they struggle with more complex, scenario-based sports reasoning, lagging behind human expertise. The introduction of SportQA marks a significant step forward in NLP, offering a tool for assessing and enhancing sports understanding in LLMs.