 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFSPMNet: Cross-subject Fourier-guided Spatial-Patch Mamba Network for EEG Motor Imagery Decoding in Stroke Patients
May 11, 2026Motor imagery electroencephalography (MI-EEG) decoding offers a non-invasive route for post-stroke rehabilitation, but cross-patient use remains difficult because pathological neural reorganization changes task-related EEG dynamics, aperiodic activity, local excitability, cross-regional coordination, and trial-level brain-state context. This makes source-learned MI representations unreliable for unseen patients. To address this problem, we propose CFSPMNet, a cross-patient adaptation framework that models post-stroke MI-EEG as latent neural-state organization. CFSPMNet combines a Fourier-Reorganized State Mamba Network (FRSM) with Shared-Private Prototype Matching (SPPM). FRSM represents each trial as a latent physiological token sequence, reorganizes token states in the Fourier domain, and uses Fourier-derived trial context to guide Mamba state-space propagation. SPPM improves target pseudo-label updating by combining semantic confidence with shared-private physiological consistency, filtering confident but physiologically inconsistent target predictions. Leave-one-subject-out experiments on two stroke MI-EEG datasets show that CFSPMNet outperforms representative CNN-, Transformer-, Mamba-, and adaptation-based baselines, achieving average accuracies of 68.23% on XW-Stroke and 73.33% on 2019-Stroke, with gains of 5.63 and 8.25 percentage points over the strongest competitors. Ablation, sensitivity, feature-alignment, pseudo-label selection, and neurophysiological visualization analyses further support the roles of Fourier-domain token-state reorganization and calibrated pseudo-label updating. These results suggest that latent neural-state modeling can improve rehabilitation-oriented cross-patient BCI decoding. Code is available at https://github.com/wxk1224/CFSPMNet.
Reinforcement Learning for Speculative Trading under Exploratory Framework
Apr 02, 2026We study a speculative trading problem within the exploratory reinforcement learning (RL) framework of Wang et al. [2020]. The problem is formulated as a sequential optimal stopping problem over entry and exit times under general utility function and price process. We first consider a relaxed version of the problem in which the stopping times are modeled by the jump times of Cox processes driven by bounded, non-randomized intensity controls. Under the exploratory formulation, the agent's randomized control is characterized via the probability measure over the jump intensities, and their objective function is regularized by Shannon's differential entropy. This yields a system of the exploratory HJB equations and Gibbs distributions in closed-form as the optimal policy. Error estimates and convergence of the RL objective to the value function of the original problem are established. Finally, an RL algorithm is designed, and its implementation is showcased in a pairs-trading application.
Non-Invasive Reconstruction of Intracranial EEG Across the Deep Temporal Lobe from Scalp EEG based on Conditional Normalizing Flow
Feb 27, 2026Although obtaining deep brain activity from non-invasive scalp electroencephalography (sEEG) is crucial for neuroscience and clinical diagnosis, directly generating high-fidelity intracranial electroencephalography (iEEG) signals remains a largely unexplored field, limiting our understanding of deep brain dynamics. Current research primarily focuses on traditional signal processing or source localization methods, which struggle to capture the complex waveforms and random characteristics of iEEG. To address this critical challenge, this paper introduces NeuroFlowNet, a novel cross-modal generative framework whose core contribution lies in the first-ever reconstruction of iEEG signals from the entire deep temporal lobe region using sEEG signals. NeuroFlowNet is built on Conditional Normalizing Flow (CNF), which directly models complex conditional probability distributions through reversible transformations, thereby explicitly capturing the randomness of brain signals and fundamentally avoiding the pattern collapse issues common in existing generative models. Additionally, the model integrates a multi-scale architecture and self-attention mechanisms to robustly capture fine-grained temporal details and long-range dependencies. Validation results on a publicly available synchronized sEEG-iEEG dataset demonstrate NeuroFlowNet's effectiveness in terms of temporal waveform fidelity, spectral feature reproduction, and functional connectivity restoration. This study establishes a more reliable and scalable new paradigm for non-invasive analysis of deep brain dynamics. The code of this study is available in https://github.com/hdy6438/NeuroFlowNet
ML-DCN: Masked Low-Rank Deep Crossing Network Towards Scalable Ads Click-through Rate Prediction at Pinterest
Feb 09, 2026Deep learning recommendation systems rely on feature interaction modules to model complex user-item relationships across sparse categorical and dense features. In large-scale ad ranking, increasing model capacity is a promising path to improving both predictive performance and business outcomes, yet production serving budgets impose strict constraints on latency and FLOPs. This creates a central tension: we want interaction modules that both scale effectively with additional compute and remain compute-efficient at serving time. In this work, we study how to scale feature interaction modules under a fixed serving budget. We find that naively scaling DCNv2 and MaskNet, despite their widespread adoption in industry, yields rapidly diminishing offline gains in the Pinterest ads ranking system. To overcome aforementioned limitations, we propose ML-DCN, an interaction module that integrates an instance-conditioned mask into a low-rank crossing layer, enabling per-example selection and amplification of salient interaction directions while maintaining efficient computation. This novel architecture combines the strengths of DCNv2 and MaskNet, scales efficiently with increased compute, and achieves state-of-the-art performance. Experiments on a large internal Pinterest ads dataset show that ML-DCN achieves higher AUC than DCNv2, MaskNet, and recent scaling-oriented alternatives at matched FLOPs, and it scales more favorably overall as compute increases, exhibiting a stronger AUC-FLOPs trade-off. Finally, online A/B tests demonstrate statistically significant improvements in key ads metrics (including CTR and click-quality measures) and ML-DCN has been deployed in the production system with neutral serving cost.
Hi-DREAM: Brain Inspired Hierarchical Diffusion for fMRI Reconstruction via ROI Encoder and visuAl Mapping
Nov 14, 2025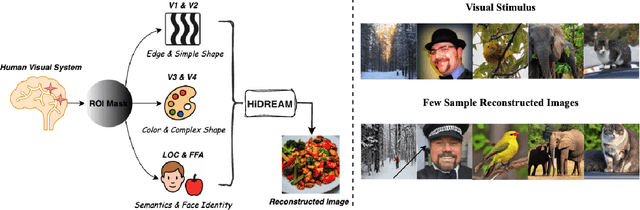
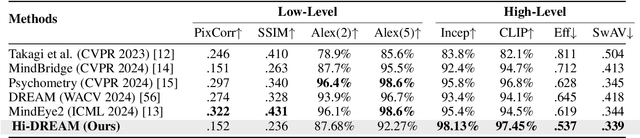
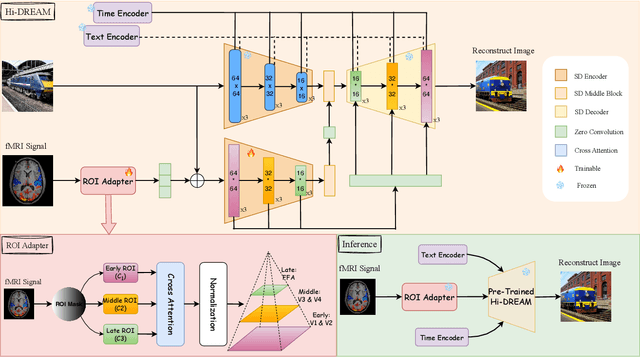
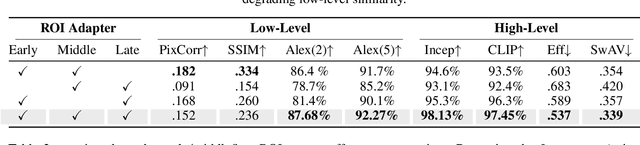
Mapping human brain activity to natural images offers a new window into vision and cognition, yet current diffusion-based decoders face a core difficulty: most condition directly on fMRI features without analyzing how visual information is organized across the cortex. This overlooks the brain's hierarchical processing and blurs the roles of early, middle, and late visual areas. We propose Hi-DREAM, a brain-inspired conditional diffusion framework that makes the cortical organization explicit. A region-of-interest (ROI) adapter groups fMRI into early/mid/late streams and converts them into a multi-scale cortical pyramid aligned with the U-Net depth (shallow scales preserve layout and edges; deeper scales emphasize objects and semantics). A lightweight, depth-matched ControlNet injects these scale-specific hints during denoising. The result is an efficient and interpretable decoder in which each signal plays a brain-like role, allowing the model not only to reconstruct images but also to illuminate functional contributions of different visual areas. Experiments on the Natural Scenes Dataset (NSD) show that Hi-DREAM attains state-of-the-art performance on high-level semantic metrics while maintaining competitive low-level fidelity. These findings suggest that structuring conditioning by cortical hierarchy is a powerful alternative to purely data-driven embeddings and provides a useful lens for studying the visual cortex.
Fractional-Boundary-Regularized Deep Galerkin Method for Variational Inequalities in Mixed Optimal Stopping and Control
May 25, 2025



Mixed optimal stopping and stochastic control problems define variational inequalities with non-linear Hamilton-Jacobi-Bellman (HJB) operators, whose numerical solution is notoriously difficult and lack of reliable benchmarks. We first use the dual approach to transform it into a linear operator, and then introduce a Fractional-Boundary-Regularized Deep Galerkin Method (FBR-DGM) that augments the classical $L^2$ loss with Sobolev-Slobodeckij norms on the parabolic boundary, enforcing regularity and yielding consistent improvements in the network approximation and its derivatives. The improved accuracy allows the network to be converted back to the original solution using the dual transform. The self-consistency and stability of the network can be tested by checking the primal-dual relationship among optimal value, optimal wealth, and optimal control, offering innovative benchmarks in the absence of analytical solutions.
From General to Specific: Tailoring Large Language Models for Personalized Healthcare
Dec 20, 2024



The rapid development of large language models (LLMs) has transformed many industries, including healthcare. However, previous medical LLMs have largely focused on leveraging general medical knowledge to provide responses, without accounting for patient variability and lacking true personalization at the individual level. To address this, we propose a novel method called personalized medical language model (PMLM), which explores and optimizes personalized LLMs through recommendation systems and reinforcement learning (RL). Specifically, by utilizing self-informed and peer-informed personalization, PMLM captures changes in behaviors and preferences to design initial personalized prompts tailored to individual needs. We further refine these initial personalized prompts through RL, ultimately enhancing the precision of LLM guidance. Notably, the personalized prompt are hard prompt, which grants PMLM high adaptability and reusability, allowing it to directly leverage high-quality proprietary LLMs. We evaluate PMLM using real-world obstetrics and gynecology data, and the experimental results demonstrate that PMLM achieves personalized responses, and it provides more refined and individualized services, offering a potential way for personalized medical LLMs.
High-speed and High-quality Vision Reconstruction of Spike Camera with Spike Stability Theorem
Dec 16, 2024



Neuromorphic vision sensors, such as the dynamic vision sensor (DVS) and spike camera, have gained increasing attention in recent years. The spike camera can detect fine textures by mimicking the fovea in the human visual system, and output a high-frequency spike stream. Real-time high-quality vision reconstruction from the spike stream can build a bridge to high-level vision task applications of the spike camera. To realize high-speed and high-quality vision reconstruction of the spike camera, we propose a new spike stability theorem that reveals the relationship between spike stream characteristics and stable light intensity. Based on the spike stability theorem, two parameter-free algorithms are designed for the real-time vision reconstruction of the spike camera. To demonstrate the performances of our algorithms, two datasets (a public dataset PKU-Spike-High-Speed and a newly constructed dataset SpikeCityPCL) are used to compare the reconstruction quality and speed of various reconstruction methods. Experimental results show that, compared with the current state-of-the-art (SOTA) reconstruction methods, our reconstruction methods obtain the best tradeoff between the reconstruction quality and speed. Additionally, we design the FPGA implementation method of our algorithms to realize the real-time (running at 20,000 FPS) visual reconstruction. Our work provides new theorem and algorithm foundations for the real-time edge-end vision processing of the spike camera.
SimpleBEV: Improved LiDAR-Camera Fusion Architecture for 3D Object Detection
Nov 08, 2024



More and more research works fuse the LiDAR and camera information to improve the 3D object detection of the autonomous driving system. Recently, a simple yet effective fusion framework has achieved an excellent detection performance, fusing the LiDAR and camera features in a unified bird's-eye-view (BEV) space. In this paper, we propose a LiDAR-camera fusion framework, named SimpleBEV, for accurate 3D object detection, which follows the BEV-based fusion framework and improves the camera and LiDAR encoders, respectively. Specifically, we perform the camera-based depth estimation using a cascade network and rectify the depth results with the depth information derived from the LiDAR points. Meanwhile, an auxiliary branch that implements the 3D object detection using only the camera-BEV features is introduced to exploit the camera information during the training phase. Besides, we improve the LiDAR feature extractor by fusing the multi-scaled sparse convolutional features. Experimental results demonstrate the effectiveness of our proposed method. Our method achieves 77.6\% NDS accuracy on the nuScenes dataset, showcasing superior performance in the 3D object detection track.
SimpleLLM4AD: An End-to-End Vision-Language Model with Graph Visual Question Answering for Autonomous Driving
Jul 31, 2024



Many fields could benefit from the rapid development of the large language models (LLMs). The end-to-end autonomous driving (e2eAD) is one of the typically fields facing new opportunities as the LLMs have supported more and more modalities. Here, by utilizing vision-language model (VLM), we proposed an e2eAD method called SimpleLLM4AD. In our method, the e2eAD task are divided into four stages, which are perception, prediction, planning, and behavior. Each stage consists of several visual question answering (VQA) pairs and VQA pairs interconnect with each other constructing a graph called Graph VQA (GVQA). By reasoning each VQA pair in the GVQA through VLM stage by stage, our method could achieve e2e driving with language. In our method, vision transformers (ViT) models are employed to process nuScenes visual data, while VLM are utilized to interpret and reason about the information extracted from the visual inputs. In the perception stage, the system identifies and classifies objects from the driving environment. The prediction stage involves forecasting the potential movements of these objects. The planning stage utilizes the gathered information to develop a driving strategy, ensuring the safety and efficiency of the autonomous vehicle. Finally, the behavior stage translates the planned actions into executable commands for the vehicle. Our experiments demonstrate that SimpleLLM4AD achieves competitive performance in complex driving scenarios.