 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Prove Robotic Path Planning Optimality? A Benchmark for Research-Level Algorithm Verification
Mar 19, 2026Robotic path planning problems are often NP-hard, and practical solutions typically rely on approximation algorithms with provable performance guarantees for general cases. While designing such algorithms is challenging, formally proving their approximation optimality is even more demanding, which requires domain-specific geometric insights and multi-step mathematical reasoning over complex operational constraints. Recent Large Language Models (LLMs) have demonstrated strong performance on mathematical reasoning benchmarks, yet their ability to assist with research-level optimality proofs in robotic path planning remains under-explored. In this work, we introduce the first benchmark for evaluating LLMs on approximation-ratio proofs of robotic path planning algorithms. The benchmark consists of 34 research-grade proof tasks spanning diverse planning problem types and complexity levels, each requiring structured reasoning over algorithm descriptions, problem constraints, and theoretical guarantees. Our evaluation of state-of-the-art proprietary and open-source LLMs reveals that even the strongest models struggle to produce fully valid proofs without external domain knowledge. However, providing LLMs with task-specific in-context lemmas substantially improves reasoning quality, a factor that is more effective than generic chain-of-thought prompting or supplying the ground-truth approximation ratio as posterior knowledge. We further provide fine-grained error analysis to characterize common logical failures and hallucinations, and demonstrate how each error type can be mitigated through targeted context augmentation.
CATNIP: LLM Unlearning via Calibrated and Tokenized Negative Preference Alignment
Feb 02, 2026Pretrained knowledge memorized in LLMs raises critical concerns over safety and privacy, which has motivated LLM Unlearning as a technique for selectively removing the influences of undesirable knowledge. Existing approaches, rooted in Gradient Ascent (GA), often degrade general domain knowledge while relying on retention data or curated contrastive pairs, which can be either impractical or data and computationally prohibitive. Negative Preference Alignment has been explored for unlearning to tackle the limitations of GA, which, however, remains confined by its choice of reference model and shows undermined performance in realistic data settings. These limitations raise two key questions: i) Can we achieve effective unlearning that quantifies model confidence in undesirable knowledge and uses it to calibrate gradient updates more precisely, thus reducing catastrophic forgetting? ii) Can we make unlearning robust to data scarcity and length variation? We answer both questions affirmatively with CATNIP (Calibrated and Tokenized Negative Preference Alignment), a principled method that rescales unlearning effects in proportion to the model's token-level confidence, thus ensuring fine-grained control over forgetting. Extensive evaluations on MUSE and WMDP benchmarks demonstrated that our work enables effective unlearning without requiring retention data or contrastive unlearning response pairs, with stronger knowledge forgetting and preservation tradeoffs than state-of-the-art methods.
DUET: Distilled LLM Unlearning from an Efficiently Contextualized Teacher
Jan 29, 2026LLM unlearning is a technique to remove the impacts of undesirable knowledge from the model without retraining from scratch, which is indispensable towards trustworthy AI. Existing unlearning methods face significant limitations: conventional tuning-based unlearning is computationally heavy and prone to catastrophic forgetting. In contrast, in-contextualized unlearning is lightweight for precise unlearning but vulnerable to prompt removal or reverse engineering attacks. In response, we propose Distilled Unlearning from an Efficient Teacher (DUET), a novel distillation-based unlearning method that combines the merits of these two lines of work. It learns a student model to imitate the behavior of a prompt-steered teacher that effectively refuses undesirable knowledge generation while preserving general domain knowledge. Extensive evaluations on existing benchmarks with our enriched evaluation protocols demonstrate that DUET achieves higher performance in both forgetting and utility preservation, while being orders of magnitude more data-efficient than state-of-the-art unlearning methods.
Web IP at Risk: Prevent Unauthorized Real-Time Retrieval by Large Language Models
May 19, 2025



Protecting cyber Intellectual Property (IP) such as web content is an increasingly critical concern. The rise of large language models (LLMs) with online retrieval capabilities presents a double-edged sword that enables convenient access to information but often undermines the rights of original content creators. As users increasingly rely on LLM-generated responses, they gradually diminish direct engagement with original information sources, significantly reducing the incentives for IP creators to contribute, and leading to a saturating cyberspace with more AI-generated content. In response, we propose a novel defense framework that empowers web content creators to safeguard their web-based IP from unauthorized LLM real-time extraction by leveraging the semantic understanding capability of LLMs themselves. Our method follows principled motivations and effectively addresses an intractable black-box optimization problem. Real-world experiments demonstrated that our methods improve defense success rates from 2.5% to 88.6% on different LLMs, outperforming traditional defenses such as configuration-based restrictions.
Dialogue is Better Than Monologue: Instructing Medical LLMs via Strategical Conversations
Jan 29, 2025Current medical AI systems often fail to replicate real-world clinical reasoning, as they are predominantly trained and evaluated on static text and question-answer tasks. These tuning methods and benchmarks overlook critical aspects like evidence-based reasoning and handling distracting information. To bridge this gap, we introduce a novel benchmark that simulates real-world diagnostic scenarios, integrating noise and difficulty levels aligned with USMLE standards. Moreover, we explore dialogue-based fine-tuning, which transforms static datasets into conversational formats to better capture iterative reasoning processes. Experiments show that dialogue-tuned models outperform traditional methods, with improvements of $9.64\%$ in multi-round reasoning scenarios and $6.18\%$ in accuracy in a noisy environment. Our findings highlight dialogue tuning as a promising approach for advancing clinically aligned and robust medical AI systems.
Sports Intelligence: Assessing the Sports Understanding Capabilities of Language Models through Question Answering from Text to Video
Jun 21, 2024Understanding sports is crucial for the advancement of Natural Language Processing (NLP) due to its intricate and dynamic nature. Reasoning over complex sports scenarios has posed significant challenges to current NLP technologies which require advanced cognitive capabilities. Toward addressing the limitations of existing benchmarks on sports understanding in the NLP field, we extensively evaluated mainstream large language models for various sports tasks. Our evaluation spans from simple queries on basic rules and historical facts to complex, context-specific reasoning, leveraging strategies from zero-shot to few-shot learning, and chain-of-thought techniques. In addition to unimodal analysis, we further assessed the sports reasoning capabilities of mainstream video language models to bridge the gap in multimodal sports understanding benchmarking. Our findings highlighted the critical challenges of sports understanding for NLP. We proposed a new benchmark based on a comprehensive overview of existing sports datasets and provided extensive error analysis which we hope can help identify future research priorities in this field.
Language and Multimodal Models in Sports: A Survey of Datasets and Applications
Jun 18, 2024

Recent integration of Natural Language Processing (NLP) and multimodal models has advanced the field of sports analytics. This survey presents a comprehensive review of the datasets and applications driving these innovations post-2020. We overviewed and categorized datasets into three primary types: language-based, multimodal, and convertible datasets. Language-based and multimodal datasets are for tasks involving text or multimodality (e.g., text, video, audio), respectively. Convertible datasets, initially single-modal (video), can be enriched with additional annotations, such as explanations of actions and video descriptions, to become multimodal, offering future potential for richer and more diverse applications. Our study highlights the contributions of these datasets to various applications, from improving fan experiences to supporting tactical analysis and medical diagnostics. We also discuss the challenges and future directions in dataset development, emphasizing the need for diverse, high-quality data to support real-time processing and personalized user experiences. This survey provides a foundational resource for researchers and practitioners aiming to leverage NLP and multimodal models in sports, offering insights into current trends and future opportunities in the field.
Topology-aware Federated Learning in Edge Computing: A Comprehensive Survey
Feb 06, 2023



The ultra-low latency requirements of 5G/6G applications and privacy constraints call for distributed machine learning systems to be deployed at the edge. With its simple yet effective approach, federated learning (FL) is proved to be a natural solution for massive user-owned devices in edge computing with distributed and private training data. Most vanilla FL algorithms based on FedAvg follow a naive star topology, ignoring the heterogeneity and hierarchy of the volatile edge computing architectures and topologies in reality. In this paper, we conduct a comprehensive survey on the existing work of optimized FL models, frameworks, and algorithms with a focus on their network topologies. After a brief recap of FL and edge computing networks, we introduce various types of edge network topologies, along with the optimizations under the aforementioned network topologies. Lastly, we discuss the remaining challenges and future works for applying FL in topology-specific edge networks.
Data-Free Knowledge Distillation for Heterogeneous Federated Learning
Jun 09, 2021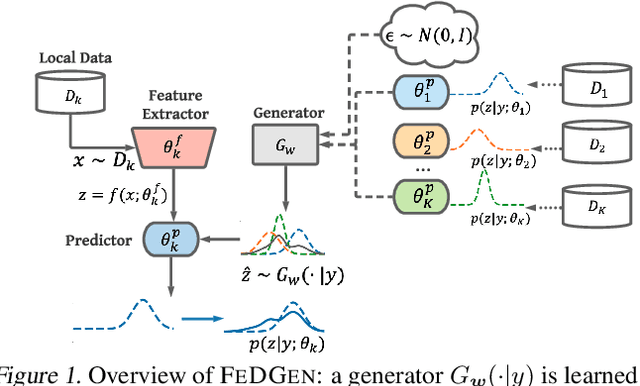
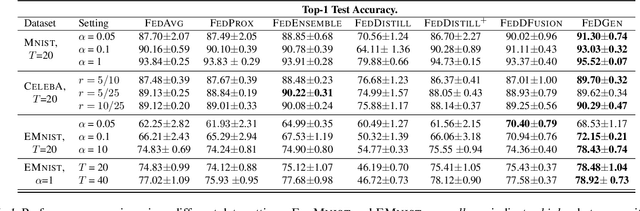


Federated Learning (FL) is a decentralized machine-learning paradigm, in which a global server iteratively averages the model parameters of local users without accessing their data. User heterogeneity has imposed significant challenges to FL, which can incur drifted global models that are slow to converge. Knowledge Distillation has recently emerged to tackle this issue, by refining the server model using aggregated knowledge from heterogeneous users, other than directly averaging their model parameters. This approach, however, depends on a proxy dataset, making it impractical unless such a prerequisite is satisfied. Moreover, the ensemble knowledge is not fully utilized to guide local model learning, which may in turn affect the quality of the aggregated model. Inspired by the prior art, we propose a data-free knowledge distillation} approach to address heterogeneous FL, where the server learns a lightweight generator to ensemble user information in a data-free manner, which is then broadcasted to users, regulating local training using the learned knowledge as an inductive bias. Empirical studies powered by theoretical implications show that, our approach facilitates FL with better generalization performance using fewer communication rounds, compared with the state-of-the-art.
Off-Policy Imitation Learning from Observations
Feb 25, 2021

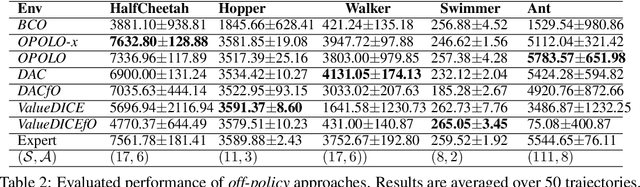
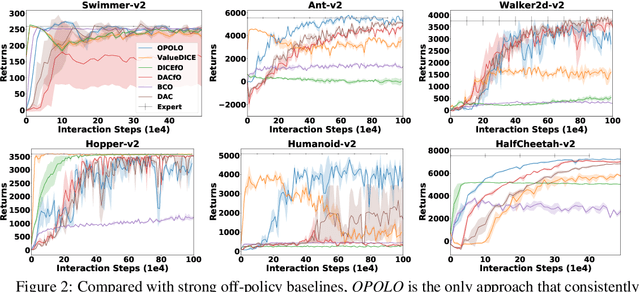
Learning from Observations (LfO) is a practical reinforcement learning scenario from which many applications can benefit through the reuse of incomplete resources. Compared to conventional imitation learning (IL), LfO is more challenging because of the lack of expert action guidance. In both conventional IL and LfO, distribution matching is at the heart of their foundation. Traditional distribution matching approaches are sample-costly which depend on on-policy transitions for policy learning. Towards sample-efficiency, some off-policy solutions have been proposed, which, however, either lack comprehensive theoretical justifications or depend on the guidance of expert actions. In this work, we propose a sample-efficient LfO approach that enables off-policy optimization in a principled manner. To further accelerate the learning procedure, we regulate the policy update with an inverse action model, which assists distribution matching from the perspective of mode-covering. Extensive empirical results on challenging locomotion tasks indicate that our approach is comparable with state-of-the-art in terms of both sample-efficiency and asymptotic performance.