 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Generation: Progressive Latent Diffusion for Text-Guided Molecular Design
Nov 14, 2025


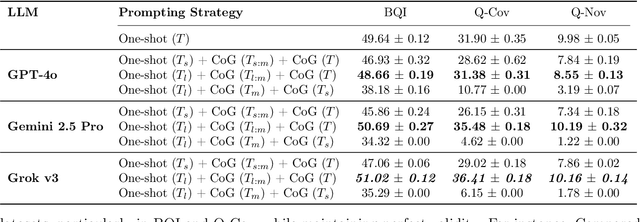
Text-conditioned molecular generation aims to translate natural-language descriptions into chemical structures, enabling scientists to specify functional groups, scaffolds, and physicochemical constraints without handcrafted rules. Diffusion-based models, particularly latent diffusion models (LDMs), have recently shown promise by performing stochastic search in a continuous latent space that compactly captures molecular semantics. Yet existing methods rely on one-shot conditioning, where the entire prompt is encoded once and applied throughout diffusion, making it hard to satisfy all the requirements in the prompt. We discuss three outstanding challenges of one-shot conditioning generation, including the poor interpretability of the generated components, the failure to generate all substructures, and the overambition in considering all requirements simultaneously. We then propose three principles to address those challenges, motivated by which we propose Chain-of-Generation (CoG), a training-free multi-stage latent diffusion framework. CoG decomposes each prompt into curriculum-ordered semantic segments and progressively incorporates them as intermediate goals, guiding the denoising trajectory toward molecules that satisfy increasingly rich linguistic constraints. To reinforce semantic guidance, we further introduce a post-alignment learning phase that strengthens the correspondence between textual and molecular latent spaces. Extensive experiments on benchmark and real-world tasks demonstrate that CoG yields higher semantic alignment, diversity, and controllability than one-shot baselines, producing molecules that more faithfully reflect complex, compositional prompts while offering transparent insight into the generation process.
Gentle Manipulation Policy Learning via Demonstrations from VLM Planned Atomic Skills
Nov 08, 2025Autonomous execution of long-horizon, contact-rich manipulation tasks traditionally requires extensive real-world data and expert engineering, posing significant cost and scalability challenges. This paper proposes a novel framework integrating hierarchical semantic decomposition, reinforcement learning (RL), visual language models (VLMs), and knowledge distillation to overcome these limitations. Complex tasks are decomposed into atomic skills, with RL-trained policies for each primitive exclusively in simulation. Crucially, our RL formulation incorporates explicit force constraints to prevent object damage during delicate interactions. VLMs perform high-level task decomposition and skill planning, generating diverse expert demonstrations. These are distilled into a unified policy via Visual-Tactile Diffusion Policy for end-to-end execution. We conduct comprehensive ablation studies exploring different VLM-based task planners to identify optimal demonstration generation pipelines, and systematically compare imitation learning algorithms for skill distillation. Extensive simulation experiments and physical deployment validate that our approach achieves policy learning for long-horizon manipulation without costly human demonstrations, while the VLM-guided atomic skill framework enables scalable generalization to diverse tasks.
Unraveling LoRA Interference: Orthogonal Subspaces for Robust Model Merging
May 28, 2025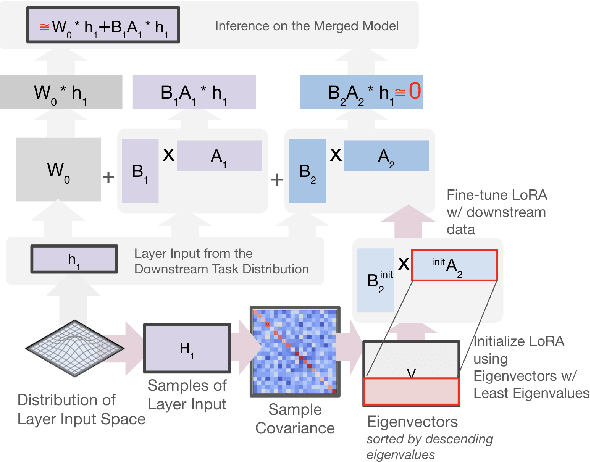
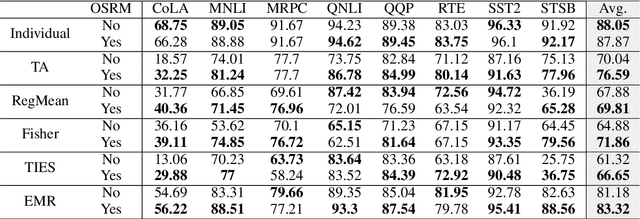
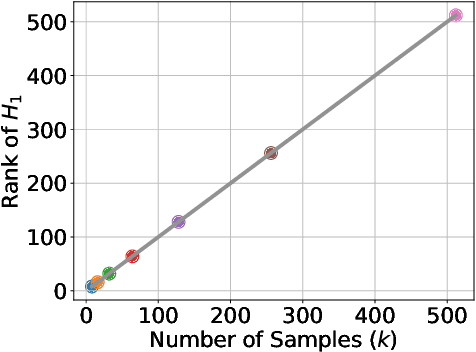
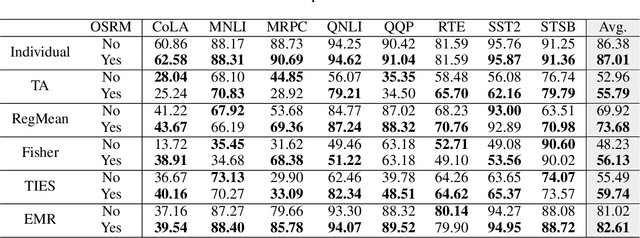
Fine-tuning large language models (LMs) for individual tasks yields strong performance but is expensive for deployment and storage. Recent works explore model merging to combine multiple task-specific models into a single multi-task model without additional training. However, existing merging methods often fail for models fine-tuned with low-rank adaptation (LoRA), due to significant performance degradation. In this paper, we show that this issue arises from a previously overlooked interplay between model parameters and data distributions. We propose Orthogonal Subspaces for Robust model Merging (OSRM) to constrain the LoRA subspace *prior* to fine-tuning, ensuring that updates relevant to one task do not adversely shift outputs for others. Our approach can seamlessly integrate with most existing merging algorithms, reducing the unintended interference among tasks. Extensive experiments on eight datasets, tested with three widely used LMs and two large LMs, demonstrate that our method not only boosts merging performance but also preserves single-task accuracy. Furthermore, our approach exhibits greater robustness to the hyperparameters of merging. These results highlight the importance of data-parameter interaction in model merging and offer a plug-and-play solution for merging LoRA models.
Dynamic Uncertainty Ranking: Enhancing In-Context Learning for Long-Tail Knowledge in LLMs
Oct 31, 2024Large language models (LLMs) can learn vast amounts of knowledge from diverse domains during pre-training. However, long-tail knowledge from specialized domains is often scarce and underrepresented, rarely appearing in the models' memorization. Prior work has shown that in-context learning (ICL) with retriever augmentation can help LLMs better capture long-tail knowledge, reducing their reliance on pre-trained data. Despite these advances, we observe that LLM predictions for long-tail questions remain uncertain to variations in retrieved samples. To take advantage of the uncertainty in ICL for guiding LLM predictions toward correct answers on long-tail samples, we propose a reinforcement learning-based dynamic uncertainty ranking method for ICL that accounts for the varying impact of each retrieved sample on LLM predictions. Our approach prioritizes more informative and stable samples while demoting misleading ones, updating rankings based on the feedback from the LLM w.r.t. each retrieved sample. To enhance training efficiency and reduce query costs, we introduce a learnable dynamic ranking threshold, adjusted when the model encounters negative prediction shifts. Experimental results on various question-answering datasets from different domains show that our method outperforms the best baseline by $2.76\%$, with a notable $5.96\%$ boost in accuracy on long-tail questions that elude zero-shot inference.
Distributed In-Context Learning under Non-IID Among Clients
Jul 31, 2024
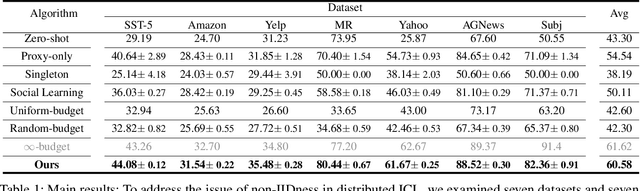
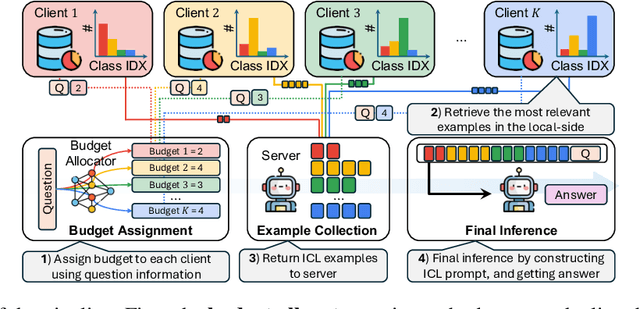
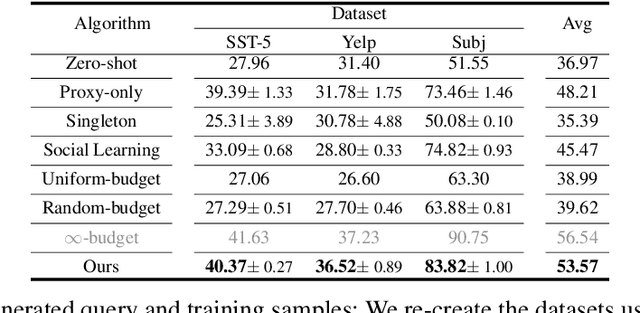
Advancements in large language models (LLMs) have shown their effectiveness in multiple complicated natural language reasoning tasks. A key challenge remains in adapting these models efficiently to new or unfamiliar tasks. In-context learning (ICL) provides a promising solution for few-shot adaptation by retrieving a set of data points relevant to a query, called in-context examples (ICE), from a training dataset and providing them during the inference as context. Most existing studies utilize a centralized training dataset, yet many real-world datasets may be distributed among multiple clients, and remote data retrieval can be associated with costs. Especially when the client data are non-identical independent distributions (non-IID), retrieving from clients a proper set of ICEs needed for a test query presents critical challenges. In this paper, we first show that in this challenging setting, test queries will have different preferences among clients because of non-IIDness, and equal contribution often leads to suboptimal performance. We then introduce a novel approach to tackle the distributed non-IID ICL problem when a data usage budget is present. The principle is that each client's proper contribution (budget) should be designed according to the preference of each query for that client. Our approach uses a data-driven manner to allocate a budget for each client, tailored to each test query. Through extensive empirical studies on diverse datasets, our framework demonstrates superior performance relative to competing baselines.
Augmented Risk Prediction for the Onset of Alzheimer's Disease from Electronic Health Records with Large Language Models
May 26, 2024



Alzheimer's disease (AD) is the fifth-leading cause of death among Americans aged 65 and older. Screening and early detection of AD and related dementias (ADRD) are critical for timely intervention and for identifying clinical trial participants. The widespread adoption of electronic health records (EHRs) offers an important resource for developing ADRD screening tools such as machine learning based predictive models. Recent advancements in large language models (LLMs) demonstrate their unprecedented capability of encoding knowledge and performing reasoning, which offers them strong potential for enhancing risk prediction. This paper proposes a novel pipeline that augments risk prediction by leveraging the few-shot inference power of LLMs to make predictions on cases where traditional supervised learning methods (SLs) may not excel. Specifically, we develop a collaborative pipeline that combines SLs and LLMs via a confidence-driven decision-making mechanism, leveraging the strengths of SLs in clear-cut cases and LLMs in more complex scenarios. We evaluate this pipeline using a real-world EHR data warehouse from Oregon Health \& Science University (OHSU) Hospital, encompassing EHRs from over 2.5 million patients and more than 20 million patient encounters. Our results show that our proposed approach effectively combines the power of SLs and LLMs, offering significant improvements in predictive performance. This advancement holds promise for revolutionizing ADRD screening and early detection practices, with potential implications for better strategies of patient management and thus improving healthcare.
Distributed Harmonization: Federated Clustered Batch Effect Adjustment and Generalization
May 23, 2024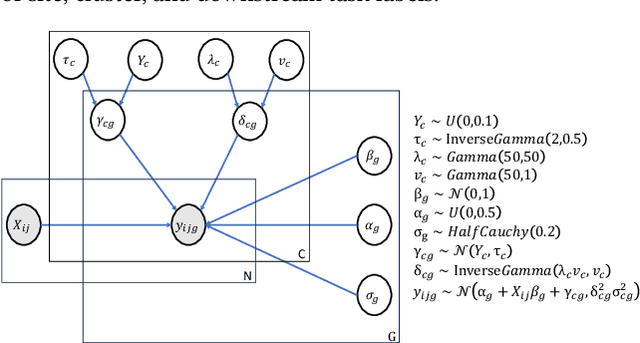

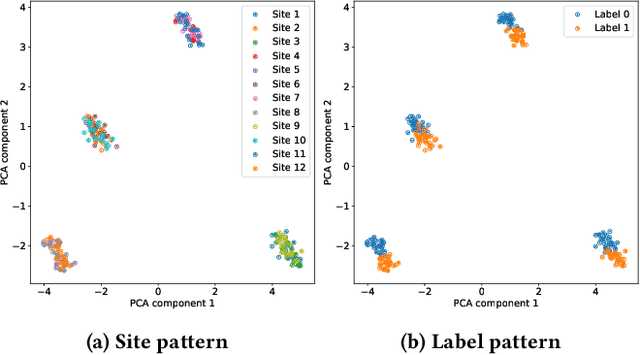

Independent and identically distributed (i.i.d.) data is essential to many data analysis and modeling techniques. In the medical domain, collecting data from multiple sites or institutions is a common strategy that guarantees sufficient clinical diversity, determined by the decentralized nature of medical data. However, data from various sites are easily biased by the local environment or facilities, thereby violating the i.i.d. rule. A common strategy is to harmonize the site bias while retaining important biological information. The ComBat is among the most popular harmonization approaches and has recently been extended to handle distributed sites. However, when faced with situations involving newly joined sites in training or evaluating data from unknown/unseen sites, ComBat lacks compatibility and requires retraining with data from all the sites. The retraining leads to significant computational and logistic overhead that is usually prohibitive. In this work, we develop a novel Cluster ComBat harmonization algorithm, which leverages cluster patterns of the data in different sites and greatly advances the usability of ComBat harmonization. We use extensive simulation and real medical imaging data from ADNI to demonstrate the superiority of the proposed approach.
Towards Stability of Parameter-free Optimization
May 07, 2024



Hyperparameter tuning, particularly the selection of an appropriate learning rate in adaptive gradient training methods, remains a challenge. To tackle this challenge, in this paper, we propose a novel parameter-free optimizer, AdamG (Adam with the golden step size), designed to automatically adapt to diverse optimization problems without manual tuning. The core technique underlying AdamG is our golden step size derived for the AdaGrad-Norm algorithm, which is expected to help AdaGrad-Norm preserve the tuning-free convergence and approximate the optimal step size in expectation w.r.t. various optimization scenarios. To better evaluate tuning-free performance, we propose a novel evaluation criterion, stability, to comprehensively assess the efficacy of parameter-free optimizers in addition to classical performance criteria. Empirical results demonstrate that compared with other parameter-free baselines, AdamG achieves superior performance, which is consistently on par with Adam using a manually tuned learning rate across various optimization tasks.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Apr 23, 2024



Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process. Cloud and edge servers hosting FL clients may exhibit diverse carbon footprints influenced by their geographical locations with varying power sources, offering opportunities to reduce carbon emissions by training local models with adaptive computations and communications. In this paper, we propose FedGreen, a carbon-aware FL approach to efficiently train models by adopting adaptive model sizes shared with clients based on their carbon profiles and locations using ordered dropout as a model compression technique. We theoretically analyze the trade-offs between the produced carbon emissions and the convergence accuracy, considering the carbon intensity discrepancy across countries to choose the parameters optimally. Empirical studies show that FedGreen can substantially reduce the carbon footprints of FL compared to the state-of-the-art while maintaining competitive model accuracy.
On the Generalization Ability of Unsupervised Pretraining
Mar 11, 2024


Recent advances in unsupervised learning have shown that unsupervised pre-training, followed by fine-tuning, can improve model generalization. However, a rigorous understanding of how the representation function learned on an unlabeled dataset affects the generalization of the fine-tuned model is lacking. Existing theoretical research does not adequately account for the heterogeneity of the distribution and tasks in pre-training and fine-tuning stage. To bridge this gap, this paper introduces a novel theoretical framework that illuminates the critical factor influencing the transferability of knowledge acquired during unsupervised pre-training to the subsequent fine-tuning phase, ultimately affecting the generalization capabilities of the fine-tuned model on downstream tasks. We apply our theoretical framework to analyze generalization bound of two distinct scenarios: Context Encoder pre-training with deep neural networks and Masked Autoencoder pre-training with deep transformers, followed by fine-tuning on a binary classification task. Finally, inspired by our findings, we propose a novel regularization method during pre-training to further enhances the generalization of fine-tuned model. Overall, our results contribute to a better understanding of unsupervised pre-training and fine-tuning paradigm, and can shed light on the design of more effective pre-training algorithms.