 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating High-Degree Heterogeneity: Federated Learning in Aerial and Space Networks
Jun 25, 2024



Federated learning offers a compelling solution to the challenges of networking and data privacy within aerial and space networks by utilizing vast private edge data and computing capabilities accessible through drones, balloons, and satellites. While current research has focused on optimizing the learning process, computing efficiency, and minimizing communication overhead, the issue of heterogeneity and class imbalance remains a significant barrier to rapid model convergence. In our study, we explore the influence of heterogeneity on class imbalance, which diminishes performance in ASN-based federated learning. We illustrate the correlation between heterogeneity and class imbalance within grouped data and show how constraints such as battery life exacerbate the class imbalance challenge. Our findings indicate that ASN-based FL faces heightened class imbalance issues even with similar levels of heterogeneity compared to other scenarios. Finally, we analyze the impact of varying degrees of heterogeneity on FL training and evaluate the efficacy of current state-of-the-art algorithms under these conditions. Our results reveal that the heterogeneity challenge is more pronounced in ASN-based federated learning and that prevailing algorithms often fail to effectively address high levels of heterogeneity.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Apr 23, 2024



Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process. Cloud and edge servers hosting FL clients may exhibit diverse carbon footprints influenced by their geographical locations with varying power sources, offering opportunities to reduce carbon emissions by training local models with adaptive computations and communications. In this paper, we propose FedGreen, a carbon-aware FL approach to efficiently train models by adopting adaptive model sizes shared with clients based on their carbon profiles and locations using ordered dropout as a model compression technique. We theoretically analyze the trade-offs between the produced carbon emissions and the convergence accuracy, considering the carbon intensity discrepancy across countries to choose the parameters optimally. Empirical studies show that FedGreen can substantially reduce the carbon footprints of FL compared to the state-of-the-art while maintaining competitive model accuracy.
WeiAvg: Federated Learning Model Aggregation Promoting Data Diversity
May 24, 2023



Federated learning provides a promising privacy-preserving way for utilizing large-scale private edge data from massive Internet-of-Things (IoT) devices. While existing research extensively studied optimizing the learning process, computing efficiency, and communication overhead, one important and often overlooked aspect is that participants contribute predictive knowledge from their data, impacting the quality of the federated models learned. While FedAvg treats each client equally and assigns weight solely based on the number of samples, the diversity of samples on each client could greatly affect the local update performance and the final aggregated model. In this paper, we propose a novel approach to address this issue by introducing a Weighted Averaging (WeiAvg) framework that emphasizes updates from high-diversity clients and diminishes the influence of those from low-diversity clients. Specifically, we introduced a projection-based approximation method to estimate the diversity of client data, instead of the computation of an entropy. We use the approximation because the locally computed entropy may not be transmitted due to excess privacy risk. Extensive experimental results show that WeiAvg converges faster and achieves higher accuracy than the original FedAvg algorithm and FedProx.
A Privacy-Preserving Hybrid Federated Learning Framework for Financial Crime Detection
Feb 23, 2023



The recent decade witnessed a surge of increase in financial crimes across the public and private sectors, with an average cost of scams of \$102m to financial institutions in 2022. Developing a mechanism for battling financial crimes is an impending task that requires in-depth collaboration from multiple institutions, and yet such collaboration imposed significant technical challenges due to the privacy and security requirements of distributed financial data. For example, consider the Society for Worldwide Interbank Financial Telecommunications (SWIFT) system, which generates 42 million transactions per day across its 11,000 global institutions. Training a detection model of fraudulent transactions requires not only secured SWIFT transactions but also the private account activities of those involved in each transaction from corresponding bank systems. The distributed nature of both samples and features prevents most existing learning systems from being directly adopted to handle the data mining task. In this paper, we collectively address these challenges by proposing a hybrid federated learning system that offers secure and privacy-aware learning and inference for financial crime detection. We conduct extensive empirical studies to evaluate the proposed framework's detection performance and privacy-protection capability, evaluating its robustness against common malicious attacks of collaborative learning. We release our source code at https://github.com/illidanlab/HyFL .
Topology-aware Federated Learning in Edge Computing: A Comprehensive Survey
Feb 06, 2023



The ultra-low latency requirements of 5G/6G applications and privacy constraints call for distributed machine learning systems to be deployed at the edge. With its simple yet effective approach, federated learning (FL) is proved to be a natural solution for massive user-owned devices in edge computing with distributed and private training data. Most vanilla FL algorithms based on FedAvg follow a naive star topology, ignoring the heterogeneity and hierarchy of the volatile edge computing architectures and topologies in reality. In this paper, we conduct a comprehensive survey on the existing work of optimized FL models, frameworks, and algorithms with a focus on their network topologies. After a brief recap of FL and edge computing networks, we introduce various types of edge network topologies, along with the optimizations under the aforementioned network topologies. Lastly, we discuss the remaining challenges and future works for applying FL in topology-specific edge networks.
Learning under Concept Drift: A Review
Apr 13, 2020
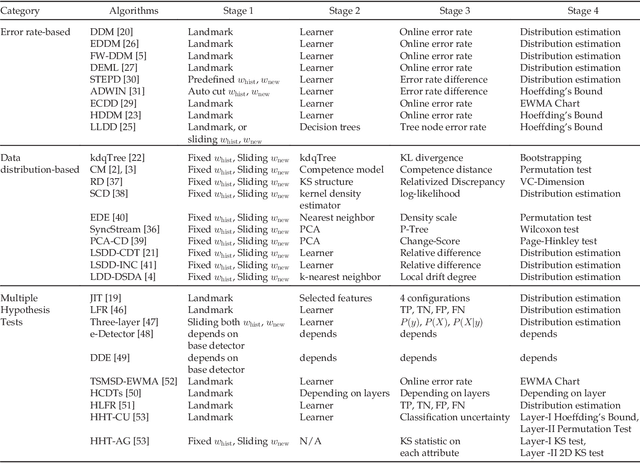
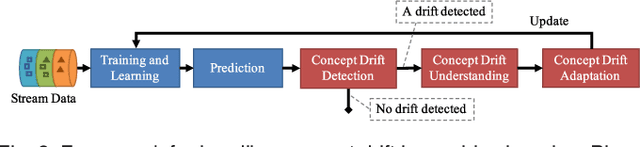
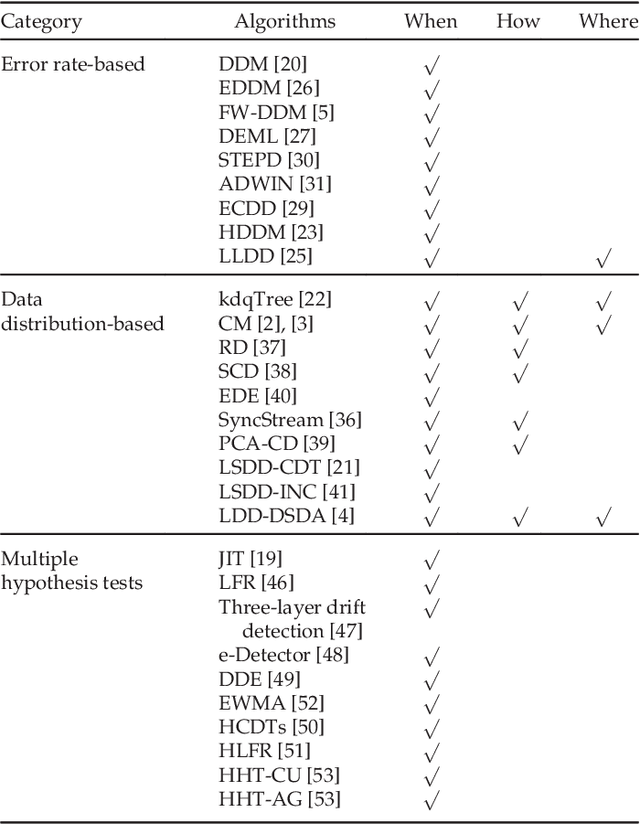
Concept drift describes unforeseeable changes in the underlying distribution of streaming data over time. Concept drift research involves the development of methodologies and techniques for drift detection, understanding and adaptation. Data analysis has revealed that machine learning in a concept drift environment will result in poor learning results if the drift is not addressed. To help researchers identify which research topics are significant and how to apply related techniques in data analysis tasks, it is necessary that a high quality, instructive review of current research developments and trends in the concept drift field is conducted. In addition, due to the rapid development of concept drift in recent years, the methodologies of learning under concept drift have become noticeably systematic, unveiling a framework which has not been mentioned in literature. This paper reviews over 130 high quality publications in concept drift related research areas, analyzes up-to-date developments in methodologies and techniques, and establishes a framework of learning under concept drift including three main components: concept drift detection, concept drift understanding, and concept drift adaptation. This paper lists and discusses 10 popular synthetic datasets and 14 publicly available benchmark datasets used for evaluating the performance of learning algorithms aiming at handling concept drift. Also, concept drift related research directions are covered and discussed. By providing state-of-the-art knowledge, this survey will directly support researchers in their understanding of research developments in the field of learning under concept drift.