 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Sum SVD: Balancing Loss Sensitivity for Low Rank LLM Compression
Feb 02, 2026Advances in large language models have driven strong performance across many tasks, but their memory and compute costs still hinder deployment. SVD-based compression reduces storage and can speed up inference via low-rank factors, yet performance depends on how rank is allocated under a global compression ratio. Prior methods often use homogeneous ranks for similarly sized matrices, despite large differences in loss sensitivity, or rely on expensive iterative pre-truncation optimization to determine per matrix ranks. We propose \textbf{Zero Sum SVD} (\textbf{ZS-SVD}), a post-training method that performs \emph{global} singular component selection using activation whitening and first-order calibration loss estimates in whitened coordinates. \textbf{ZS-SVD} prunes components across the whole model with a \textbf{zero sum} rule that keeps the cumulative predicted loss change near zero, automatically yielding heterogeneous ranks without solving a rank allocation optimization. Motivated by evidence that gradients near pretrained solutions exhibit low rank structure, we also introduce an optional lightweight correction that applies a \textbf{single} projected gradient update after truncation, followed by re-truncation. Extensive experiments across multiple LLM architectures show consistent gains across diverse benchmarks and compression ratios. Code is available at https://github.com/mint-vu/Zero-Sum-SVD
LUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025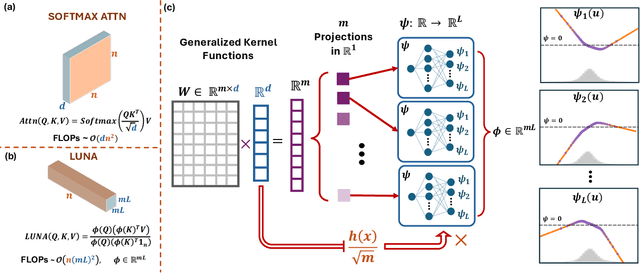
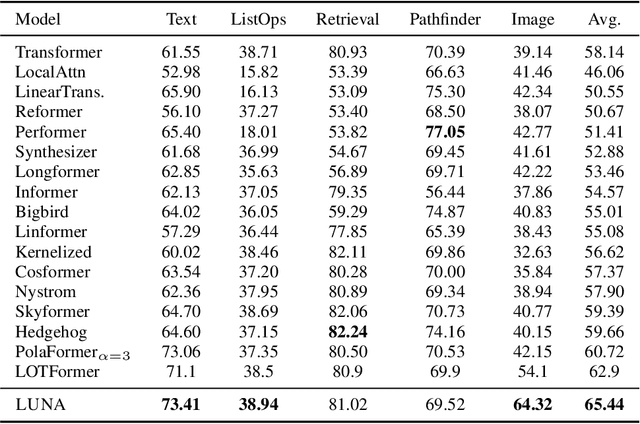
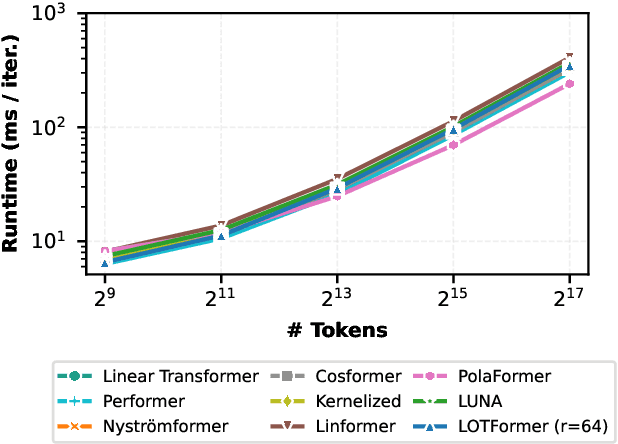
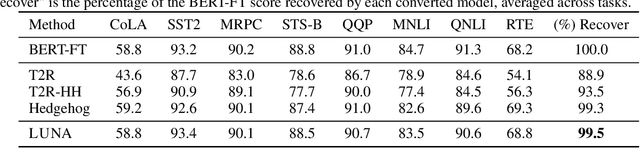
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025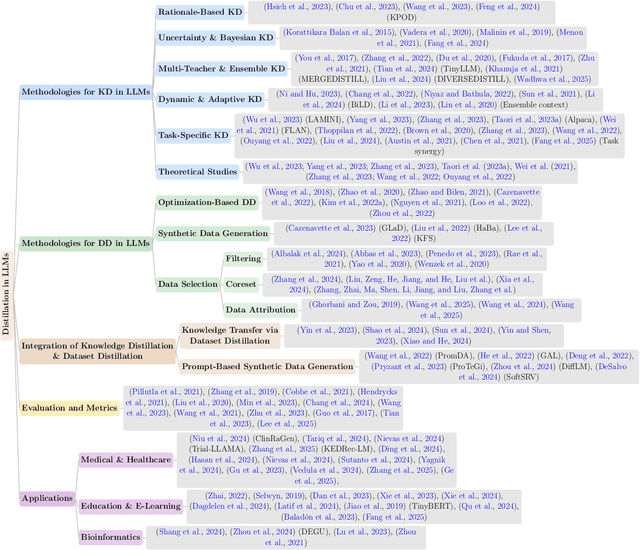
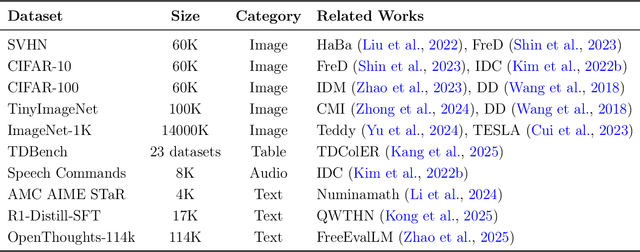
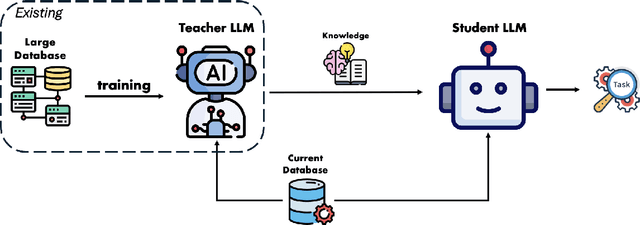

The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
Diffusion-Augmented Coreset Expansion for Scalable Dataset Distillation
Dec 05, 2024



With the rapid scaling of neural networks, data storage and communication demands have intensified. Dataset distillation has emerged as a promising solution, condensing information from extensive datasets into a compact set of synthetic samples by solving a bilevel optimization problem. However, current methods face challenges in computational efficiency, particularly with high-resolution data and complex architectures. Recently, knowledge-distillation-based dataset condensation approaches have made this process more computationally feasible. Yet, with the recent developments of generative foundation models, there is now an opportunity to achieve even greater compression, enhance the quality of distilled data, and introduce valuable diversity into the data representation. In this work, we propose a two-stage solution. First, we compress the dataset by selecting only the most informative patches to form a coreset. Next, we leverage a generative foundation model to dynamically expand this compressed set in real-time, enhancing the resolution of these patches and introducing controlled variability to the coreset. Our extensive experiments demonstrate the robustness and efficiency of our approach across a range of dataset distillation benchmarks. We demonstrate a significant improvement of over 10% compared to the state-of-the-art on several large-scale dataset distillation benchmarks. The code will be released soon.
Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
Oct 30, 2024



In the field of large language model (LLM)-based proof generation, despite being trained on extensive corpora such as OpenWebMath and Arxiv, these models still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the suboptimal order of each proof data used in training. Published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. However, this order aims to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders are substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order.
MCNC: Manifold Constrained Network Compression
Jun 27, 2024



The outstanding performance of large foundational models across diverse tasks-from computer vision to speech and natural language processing-has significantly increased their demand. However, storing and transmitting these models pose significant challenges due to their massive size (e.g., 350GB for GPT-3). Recent literature has focused on compressing the original weights or reducing the number of parameters required for fine-tuning these models. These compression methods typically involve constraining the parameter space, for example, through low-rank reparametrization (e.g., LoRA) or quantization (e.g., QLoRA) during model training. In this paper, we present MCNC as a novel model compression method that constrains the parameter space to low-dimensional pre-defined and frozen nonlinear manifolds, which effectively cover this space. Given the prevalence of good solutions in over-parameterized deep neural networks, we show that by constraining the parameter space to our proposed manifold, we can identify high-quality solutions while achieving unprecedented compression rates across a wide variety of tasks. Through extensive experiments in computer vision and natural language processing tasks, we demonstrate that our method, MCNC, significantly outperforms state-of-the-art baselines in terms of compression, accuracy, and/or model reconstruction time.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Apr 23, 2024



Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process. Cloud and edge servers hosting FL clients may exhibit diverse carbon footprints influenced by their geographical locations with varying power sources, offering opportunities to reduce carbon emissions by training local models with adaptive computations and communications. In this paper, we propose FedGreen, a carbon-aware FL approach to efficiently train models by adopting adaptive model sizes shared with clients based on their carbon profiles and locations using ordered dropout as a model compression technique. We theoretically analyze the trade-offs between the produced carbon emissions and the convergence accuracy, considering the carbon intensity discrepancy across countries to choose the parameters optimally. Empirical studies show that FedGreen can substantially reduce the carbon footprints of FL compared to the state-of-the-art while maintaining competitive model accuracy.
One Category One Prompt: Dataset Distillation using Diffusion Models
Mar 11, 2024



The extensive amounts of data required for training deep neural networks pose significant challenges on storage and transmission fronts. Dataset distillation has emerged as a promising technique to condense the information of massive datasets into a much smaller yet representative set of synthetic samples. However, traditional dataset distillation approaches often struggle to scale effectively with high-resolution images and more complex architectures due to the limitations in bi-level optimization. Recently, several works have proposed exploiting knowledge distillation with decoupled optimization schemes to scale up dataset distillation. Although these methods effectively address the scalability issue, they rely on extensive image augmentations requiring the storage of soft labels for augmented images. In this paper, we introduce Dataset Distillation using Diffusion Models (D3M) as a novel paradigm for dataset distillation, leveraging recent advancements in generative text-to-image foundation models. Our approach utilizes textual inversion, a technique for fine-tuning text-to-image generative models, to create concise and informative representations for large datasets. By employing these learned text prompts, we can efficiently store and infer new samples for introducing data variability within a fixed memory budget. We show the effectiveness of our method through extensive experiments across various computer vision benchmark datasets with different memory budgets.
Dynamic Online Modulation Recognition using Incremental Learning
Dec 07, 2023



Modulation recognition is a fundamental task in communication systems as the accurate identification of modulation schemes is essential for reliable signal processing, interference mitigation for coexistent communication technologies, and network optimization. Incorporating deep learning (DL) models into modulation recognition has demonstrated promising results in various scenarios. However, conventional DL models often fall short in online dynamic contexts, particularly in class incremental scenarios where new modulation schemes are encountered during online deployment. Retraining these models on all previously seen modulation schemes is not only time-consuming but may also not be feasible due to storage limitations. On the other hand, training solely on new modulation schemes often results in catastrophic forgetting of previously learned classes. This issue renders DL-based modulation recognition models inapplicable in real-world scenarios because the dynamic nature of communication systems necessitate the effective adaptability to new modulation schemes. This paper addresses this challenge by evaluating the performance of multiple Incremental Learning (IL) algorithms in dynamic modulation recognition scenarios, comparing them against conventional DL-based modulation recognition. Our results demonstrate that modulation recognition frameworks based on IL effectively prevent catastrophic forgetting, enabling models to perform robustly in dynamic scenarios.
BrainWash: A Poisoning Attack to Forget in Continual Learning
Nov 24, 2023



Continual learning has gained substantial attention within the deep learning community, offering promising solutions to the challenging problem of sequential learning. Yet, a largely unexplored facet of this paradigm is its susceptibility to adversarial attacks, especially with the aim of inducing forgetting. In this paper, we introduce "BrainWash," a novel data poisoning method tailored to impose forgetting on a continual learner. By adding the BrainWash noise to a variety of baselines, we demonstrate how a trained continual learner can be induced to forget its previously learned tasks catastrophically, even when using these continual learning baselines. An important feature of our approach is that the attacker requires no access to previous tasks' data and is armed merely with the model's current parameters and the data belonging to the most recent task. Our extensive experiments highlight the efficacy of BrainWash, showcasing degradation in performance across various regularization-based continual learning methods.