 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds for Advection-Diffusion Equations: An Exploration with AI-Generated Proofs
May 20, 2026We establish explicit lower bounds for advection-diffusion equations in three settings: a polynomial $\dot H^{-1}$ bound for inviscid shears with $u\in L^\infty_t W^{1,1}_y$, a uniform positive lower bound on the mixing scale for diffusive shears, and an exponential $L^2$ bound for rapidly oscillating time-periodic flows. All constants are explicit in the data. The proofs were generated entirely by a multi-agent math proving system, QED, without expert human intervention, serving as a test of AI's capability to produce rigorous mathematics.
QED: An Open-Source Multi-Agent System for Generating Mathematical Proofs on Open Problems
Apr 27, 2026We explore a central question in AI for mathematics: can AI systems produce original, nontrivial proofs for open research problems? Despite strong benchmark performance, producing genuinely novel proofs remains an outstanding challenge for LLMs. Through systematic experiments with frontier LLMs on research-level proof tasks, we identify seven failure modes that prevent reliable proof generation, including context contamination, citation hallucination, hand-waving on key steps and misallocation of proof effort, unstable proof plans, unfocused verification, problem modification and single-model bottleneck. We argue that the gap between benchmark success and research-level proving is primarily one of system design, due to those failure modes. We present QED, an open-source multi-agent proof system in which each architectural decision directly addresses a specific failure mode. Evaluated on five open problems in applied analysis and PDEs contributed by domain experts, QED produces correct proofs for three problems, each verified by the contributing experts as original and nontrivial. QED is released as open-source software at https://github.com/proofQED/QED.
The Price of Format: Diversity Collapse in LLMs
May 25, 2025



Instruction-tuned large language models (LLMs) employ structured templates, such as role markers and special tokens, to enforce format consistency during inference. However, we identify a critical limitation of such formatting: it induces a phenomenon we term diversity collapse, where the model generates semantically similar outputs for open-ended inputs, undermining creativity and variability. We systematically evaluate this effect across tasks like story completion and free-form generation, finding that (1) diversity collapse persists even under high-temperature sampling, and (2) structural tokens in templates significantly constrain the model's output space. To contextualize these findings, we fine-tune the same model using a range of structured prompts and then evaluate them across three axes: downstream task performance, alignment behavior, and output diversity. Our analysis shows that format consistency between fine-tuning and inference is crucial for structure-sensitive tasks (e.g., GSM8K, IFEval), but has marginal influence on knowledge-heavy tasks (e.g., MMLU, WebQuestions). In contrast, output diversity is primarily governed by the presence or absence of structural tokens, with minimal formatting yielding the most diverse outputs. These findings reveal that current prompting conventions, while beneficial for alignment, may inadvertently suppress output diversity, underscoring the need for diversity-aware prompt design and instruction tuning.
Linear Correlation in LM's Compositional Generalization and Hallucination
Feb 06, 2025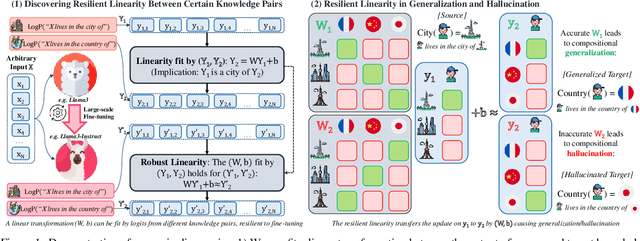

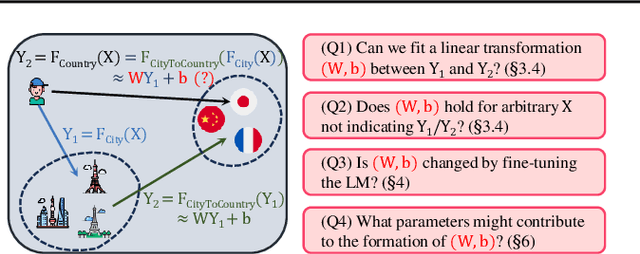

The generalization of language models (LMs) is undergoing active debates, contrasting their potential for general intelligence with their struggles with basic knowledge composition (e.g., reverse/transition curse). This paper uncovers the phenomenon of linear correlations in LMs during knowledge composition. For explanation, there exists a linear transformation between certain related knowledge that maps the next token prediction logits from one prompt to another, e.g., "X lives in the city of" $\rightarrow$ "X lives in the country of" for every given X. This mirrors the linearity in human knowledge composition, such as Paris $\rightarrow$ France. Our findings indicate that the linear transformation is resilient to large-scale fine-tuning, generalizing updated knowledge when aligned with real-world relationships, but causing hallucinations when it deviates. Empirical results suggest that linear correlation can serve as a potential identifier of LM's generalization. Finally, we show such linear correlations can be learned with a single feedforward network and pre-trained vocabulary representations, indicating LM generalization heavily relies on the latter.
Diffusion-Augmented Coreset Expansion for Scalable Dataset Distillation
Dec 05, 2024



With the rapid scaling of neural networks, data storage and communication demands have intensified. Dataset distillation has emerged as a promising solution, condensing information from extensive datasets into a compact set of synthetic samples by solving a bilevel optimization problem. However, current methods face challenges in computational efficiency, particularly with high-resolution data and complex architectures. Recently, knowledge-distillation-based dataset condensation approaches have made this process more computationally feasible. Yet, with the recent developments of generative foundation models, there is now an opportunity to achieve even greater compression, enhance the quality of distilled data, and introduce valuable diversity into the data representation. In this work, we propose a two-stage solution. First, we compress the dataset by selecting only the most informative patches to form a coreset. Next, we leverage a generative foundation model to dynamically expand this compressed set in real-time, enhancing the resolution of these patches and introducing controlled variability to the coreset. Our extensive experiments demonstrate the robustness and efficiency of our approach across a range of dataset distillation benchmarks. We demonstrate a significant improvement of over 10% compared to the state-of-the-art on several large-scale dataset distillation benchmarks. The code will be released soon.
Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
Oct 30, 2024



In the field of large language model (LLM)-based proof generation, despite being trained on extensive corpora such as OpenWebMath and Arxiv, these models still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the suboptimal order of each proof data used in training. Published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. However, this order aims to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders are substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order.
Correlation and Navigation in the Vocabulary Key Representation Space of Language Models
Oct 03, 2024



Language model (LM) decoding is based on the next-token prediction (NTP) probability distribution. For neural LMs (e.g., Transformer-based), NTP distribution is essentially a softmax-regularized dot product between an encoded input context (query) and fixed vocabulary representations (keys). In this paper, we study the effect of the key distribution on the NTP distribution, with a focus on whether the similarity between keys will trigger spurious correlations in NTP. Through knowledge-probing tasks, we show that in the NTP distribution, the few top-ranked tokens are typically accurate. However, the middle-ranked prediction is highly biased towards the tokens that are distributionally (not necessarily semantically) similar to these top ones. For instance, if "P" is predicted as the top-1 token, "A"-"Z" will all be ranked high in NTP, no matter whether they can lead to correct decoding results. This hurts the sampling diversity and makes the sampling of correct, long-tail results hopeless and noisy. We attempt to alleviate this issue via a novel in-context method that iteratively pushes the query representation away from explored regions. Specifically, we include the explored decoding results in the context and prompt the LM to generate something else, which encourages the LM to produce a query representation that has small dot products with explored keys. Experiments on knowledge-probing tasks show that our method leads to efficient navigation away from explored keys to correct new keys. We further extend our method to open-ended and chain-of-thought (for reasoning) generation. Experiment results show that ICN contributes to better generation diversity and improved self-consistency voting performance. Finally, we discuss potential training issues caused by the fixed key space together with the challenges and possible ways to address them in future research.
Learn from Failure: Fine-Tuning LLMs with Trial-and-Error Data for Intuitionistic Propositional Logic Proving
Apr 10, 2024



Recent advances in Automated Theorem Proving have shown the effectiveness of leveraging a (large) language model that generates tactics (i.e. proof steps) to search through proof states. The current model, while trained solely on successful proof paths, faces a discrepancy at the inference stage, as it must sample and try various tactics at each proof state until finding success, unlike its training which does not incorporate learning from failed attempts. Intuitively, a tactic that leads to a failed search path would indicate that similar tactics should receive less attention during the following trials. In this paper, we demonstrate the benefit of training models that additionally learn from failed search paths. Facing the lack of such trial-and-error data in existing open-source theorem-proving datasets, we curate a dataset on intuitionistic propositional logic theorems and formalize it in Lean, such that we can reliably check the correctness of proofs. We compare our model trained on relatively short trial-and-error information (TrialMaster) with models trained only on the correct paths and discover that the former solves more unseen theorems with lower trial searches.