 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Correlation in LM's Compositional Generalization and Hallucination
Paper and Code
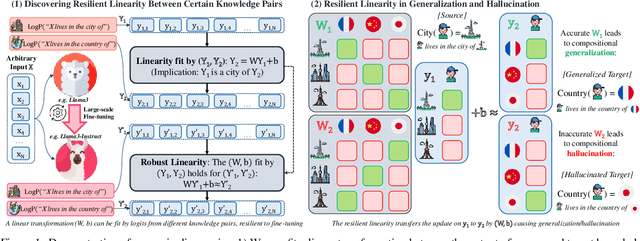

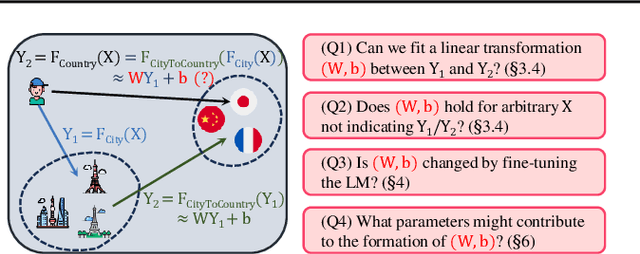

The generalization of language models (LMs) is undergoing active debates, contrasting their potential for general intelligence with their struggles with basic knowledge composition (e.g., reverse/transition curse). This paper uncovers the phenomenon of linear correlations in LMs during knowledge composition. For explanation, there exists a linear transformation between certain related knowledge that maps the next token prediction logits from one prompt to another, e.g., "X lives in the city of" $\rightarrow$ "X lives in the country of" for every given X. This mirrors the linearity in human knowledge composition, such as Paris $\rightarrow$ France. Our findings indicate that the linear transformation is resilient to large-scale fine-tuning, generalizing updated knowledge when aligned with real-world relationships, but causing hallucinations when it deviates. Empirical results suggest that linear correlation can serve as a potential identifier of LM's generalization. Finally, we show such linear correlations can be learned with a single feedforward network and pre-trained vocabulary representations, indicating LM generalization heavily relies on the latter.