 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Models for Soil Parameter Prediction Based on Satellite, Weather, Clay and Yield Data
Mar 28, 2025



Efficient nutrient management and precise fertilization are essential for advancing modern agriculture, particularly in regions striving to optimize crop yields sustainably. The AgroLens project endeavors to address this challenge by develop ing Machine Learning (ML)-based methodologies to predict soil nutrient levels without reliance on laboratory tests. By leveraging state of the art techniques, the project lays a foundation for acionable insights to improve agricultural productivity in resource-constrained areas, such as Africa. The approach begins with the development of a robust European model using the LUCAS Soil dataset and Sentinel-2 satellite imagery to estimate key soil properties, including phosphorus, potassium, nitrogen, and pH levels. This model is then enhanced by integrating supplementary features, such as weather data, harvest rates, and Clay AI-generated embeddings. This report details the methodological framework, data preprocessing strategies, and ML pipelines employed in this project. Advanced algorithms, including Random Forests, Extreme Gradient Boosting (XGBoost), and Fully Connected Neural Networks (FCNN), were implemented and finetuned for precise nutrient prediction. Results showcase robust model performance, with root mean square error values meeting stringent accuracy thresholds. By establishing a reproducible and scalable pipeline for soil nutrient prediction, this research paves the way for transformative agricultural applications, including precision fertilization and improved resource allocation in underresourced regions like Africa.
Matching Skeleton-based Activity Representations with Heterogeneous Signals for HAR
Mar 17, 2025In human activity recognition (HAR), activity labels have typically been encoded in one-hot format, which has a recent shift towards using textual representations to provide contextual knowledge. Here, we argue that HAR should be anchored to physical motion data, as motion forms the basis of activity and applies effectively across sensing systems, whereas text is inherently limited. We propose SKELAR, a novel HAR framework that pretrains activity representations from skeleton data and matches them with heterogeneous HAR signals. Our method addresses two major challenges: (1) capturing core motion knowledge without context-specific details. We achieve this through a self-supervised coarse angle reconstruction task that recovers joint rotation angles, invariant to both users and deployments; (2) adapting the representations to downstream tasks with varying modalities and focuses. To address this, we introduce a self-attention matching module that dynamically prioritizes relevant body parts in a data-driven manner. Given the lack of corresponding labels in existing skeleton data, we establish MASD, a new HAR dataset with IMU, WiFi, and skeleton, collected from 20 subjects performing 27 activities. This is the first broadly applicable HAR dataset with time-synchronized data across three modalities. Experiments show that SKELAR achieves the state-of-the-art performance in both full-shot and few-shot settings. We also demonstrate that SKELAR can effectively leverage synthetic skeleton data to extend its use in scenarios without skeleton collections.
Orthogonal Calibration for Asynchronous Federated Learning
Feb 21, 2025Asynchronous federated learning mitigates the inefficiency of conventional synchronous aggregation by integrating updates as they arrive and adjusting their influence based on staleness. Due to asynchrony and data heterogeneity, learning objectives at the global and local levels are inherently inconsistent -- global optimization trajectories may conflict with ongoing local updates. Existing asynchronous methods simply distribute the latest global weights to clients, which can overwrite local progress and cause model drift. In this paper, we propose OrthoFL, an orthogonal calibration framework that decouples global and local learning progress and adjusts global shifts to minimize interference before merging them into local models. In OrthoFL, clients and the server maintain separate model weights. Upon receiving an update, the server aggregates it into the global weights via a moving average. For client weights, the server computes the global weight shift accumulated during the client's delay and removes the components aligned with the direction of the received update. The resulting parameters lie in a subspace orthogonal to the client update and preserve the maximal information from the global progress. The calibrated global shift is then merged into the client weights for further training. Extensive experiments show that OrthoFL improves accuracy by 9.6% and achieves a 12$\times$ speedup compared to synchronous methods. Moreover, it consistently outperforms state-of-the-art asynchronous baselines under various delay patterns and heterogeneity scenarios.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Learn from Failure: Fine-Tuning LLMs with Trial-and-Error Data for Intuitionistic Propositional Logic Proving
Apr 10, 2024



Recent advances in Automated Theorem Proving have shown the effectiveness of leveraging a (large) language model that generates tactics (i.e. proof steps) to search through proof states. The current model, while trained solely on successful proof paths, faces a discrepancy at the inference stage, as it must sample and try various tactics at each proof state until finding success, unlike its training which does not incorporate learning from failed attempts. Intuitively, a tactic that leads to a failed search path would indicate that similar tactics should receive less attention during the following trials. In this paper, we demonstrate the benefit of training models that additionally learn from failed search paths. Facing the lack of such trial-and-error data in existing open-source theorem-proving datasets, we curate a dataset on intuitionistic propositional logic theorems and formalize it in Lean, such that we can reliably check the correctness of proofs. We compare our model trained on relatively short trial-and-error information (TrialMaster) with models trained only on the correct paths and discover that the former solves more unseen theorems with lower trial searches.
Physics-Informed Data Denoising for Real-Life Sensing Systems
Nov 12, 2023
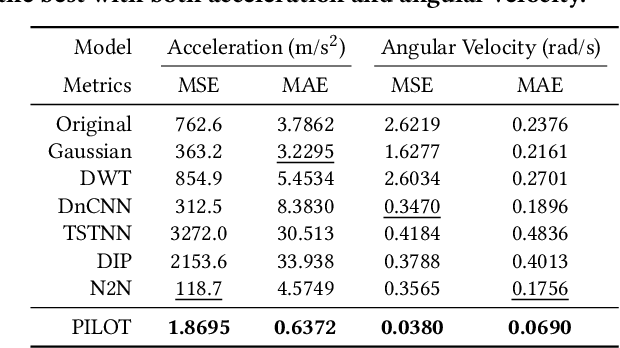


Sensors measuring real-life physical processes are ubiquitous in today's interconnected world. These sensors inherently bear noise that often adversely affects performance and reliability of the systems they support. Classic filtering-based approaches introduce strong assumptions on the time or frequency characteristics of sensory measurements, while learning-based denoising approaches typically rely on using ground truth clean data to train a denoising model, which is often challenging or prohibitive to obtain for many real-world applications. We observe that in many scenarios, the relationships between different sensor measurements (e.g., location and acceleration) are analytically described by laws of physics (e.g., second-order differential equation). By incorporating such physics constraints, we can guide the denoising process to improve even in the absence of ground truth data. In light of this, we design a physics-informed denoising model that leverages the inherent algebraic relationships between different measurements governed by the underlying physics. By obviating the need for ground truth clean data, our method offers a practical denoising solution for real-world applications. We conducted experiments in various domains, including inertial navigation, CO2 monitoring, and HVAC control, and achieved state-of-the-art performance compared with existing denoising methods. Our method can denoise data in real time (4ms for a sequence of 1s) for low-cost noisy sensors and produces results that closely align with those from high-precision, high-cost alternatives, leading to an efficient, cost-effective approach for more accurate sensor-based systems.
Federated Learning with Client-Exclusive Classes
Jan 01, 2023


Existing federated classification algorithms typically assume the local annotations at every client cover the same set of classes. In this paper, we aim to lift such an assumption and focus on a more general yet practical non-IID setting where every client can work on non-identical and even disjoint sets of classes (i.e., client-exclusive classes), and the clients have a common goal which is to build a global classification model to identify the union of these classes. Such heterogeneity in client class sets poses a new challenge: how to ensure different clients are operating in the same latent space so as to avoid the drift after aggregation? We observe that the classes can be described in natural languages (i.e., class names) and these names are typically safe to share with all parties. Thus, we formulate the classification problem as a matching process between data representations and class representations and break the classification model into a data encoder and a label encoder. We leverage the natural-language class names as the common ground to anchor the class representations in the label encoder. In each iteration, the label encoder updates the class representations and regulates the data representations through matching. We further use the updated class representations at each round to annotate data samples for locally-unaware classes according to similarity and distill knowledge to local models. Extensive experiments on four real-world datasets show that the proposed method can outperform various classical and state-of-the-art federated learning methods designed for learning with non-IID data.
Blacklight: Defending Black-Box Adversarial Attacks on Deep Neural Networks
Jun 24, 2020

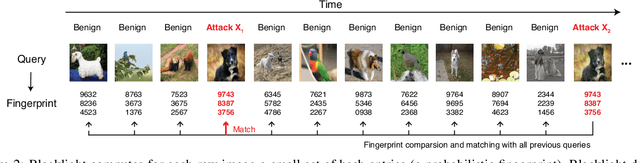

The vulnerability of deep neural networks (DNNs) to adversarial examples is well documented. Under the strong white-box threat model, where attackers have full access to DNN internals, recent work has produced continual advancements in defenses, often followed by more powerful attacks that break them. Meanwhile, research on the more realistic black-box threat model has focused almost entirely on reducing the query-cost of attacks, making them increasingly practical for ML models already deployed today. This paper proposes and evaluates Blacklight, a new defense against black-box adversarial attacks. Blacklight targets a key property of black-box attacks: to compute adversarial examples, they produce sequences of highly similar images while trying to minimize the distance from some initial benign input. To detect an attack, Blacklight computes for each query image a compact set of one-way hash values that form a probabilistic fingerprint. Variants of an image produce nearly identical fingerprints, and fingerprint generation is robust against manipulation. We evaluate Blacklight on 5 state-of-the-art black-box attacks, across a variety of models and classification tasks. While the most efficient attacks take thousands or tens of thousands of queries to complete, Blacklight identifies them all, often after only a handful of queries. Blacklight is also robust against several powerful countermeasures, including an optimal black-box attack that approximates white-box attacks in efficiency. Finally, Blacklight significantly outperforms the only known alternative in both detection coverage of attack queries and resistance against persistent attackers.
Fawkes: Protecting Personal Privacy against Unauthorized Deep Learning Models
Feb 19, 2020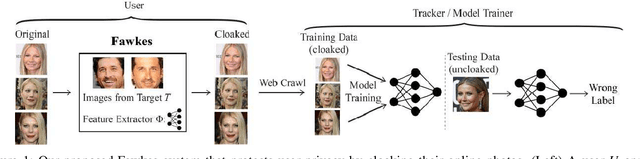

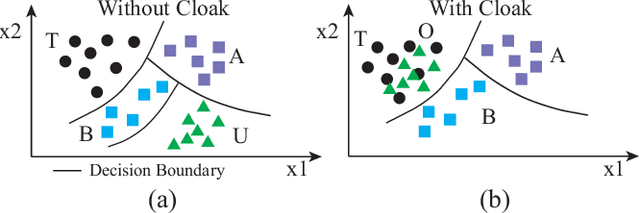
Today's proliferation of powerful facial recognition models poses a real threat to personal privacy. As Clearview.ai demonstrated, anyone can canvas the Internet for data, and train highly accurate facial recognition models of us without our knowledge. We need tools to protect ourselves from unauthorized facial recognition systems and their numerous potential misuses. Unfortunately, work in related areas are limited in practicality and effectiveness. In this paper, we propose Fawkes, a system that allow individuals to inoculate themselves against unauthorized facial recognition models. Fawkes achieves this by helping users adding imperceptible pixel-level changes (we call them "cloaks") to their own photos before publishing them online. When collected by a third-party "tracker" and used to train facial recognition models, these "cloaked" images produce functional models that consistently misidentify the user. We experimentally prove that Fawkes provides 95+% protection against user recognition regardless of how trackers train their models. Even when clean, uncloaked images are "leaked" to the tracker and used for training, Fawkes can still maintain a 80+% protection success rate. In fact, we perform real experiments against today's state-of-the-art facial recognition services and achieve 100% success. Finally, we show that Fawkes is robust against a variety of countermeasures that try to detect or disrupt cloaks.
A System-Level Solution for Low-Power Object Detection
Oct 19, 2019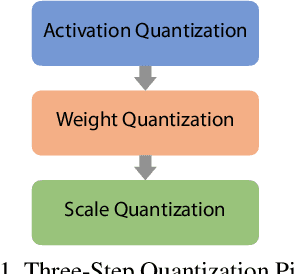
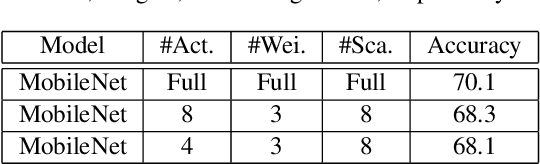
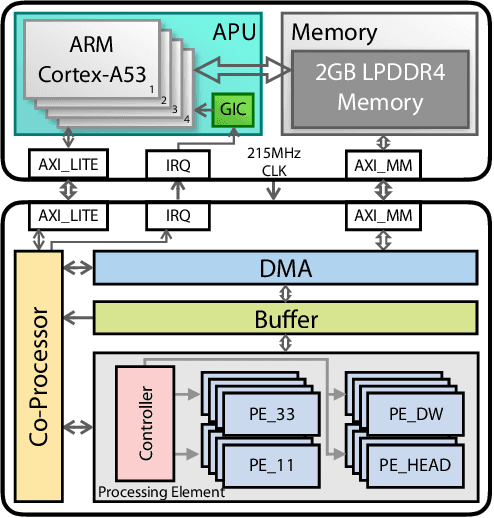

Object detection has made impressive progress in recent years with the help of deep learning. However, state-of-the-art algorithms are both computation and memory intensive. Though many lightweight networks are developed for a trade-off between accuracy and efficiency, it is still a challenge to make it practical on an embedded device. In this paper, we present a system-level solution for efficient object detection on a heterogeneous embedded device. The detection network is quantized to low bits and allows efficient implementation with shift operators. In order to make the most of the benefits of low-bit quantization, we design a dedicated accelerator with programmable logic. Inside the accelerator, a hybrid dataflow is exploited according to the heterogeneous property of different convolutional layers. We adopt a straightforward but resource-friendly column-prior tiling strategy to map the computation-intensive convolutional layers to the accelerator that can support arbitrary feature size. Other operations can be performed on the low-power CPU cores, and the entire system is executed in a pipelined manner. As a case study, we evaluate our object detection system on a real-world surveillance video with input size of 512x512, and it turns out that the system can achieve an inference speed of 18 fps at the cost of 6.9W (with display) with an mAP of 66.4 verified on the PASCAL VOC 2012 dataset.