 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs
Aug 13, 2025Forecasting in real-world settings requires models to integrate not only historical data but also relevant contextual information, often available in textual form. While recent work has shown that large language models (LLMs) can be effective context-aided forecasters via na\"ive direct prompting, their full potential remains underexplored. We address this gap with 4 strategies, providing new insights into the zero-shot capabilities of LLMs in this setting. ReDP improves interpretability by eliciting explicit reasoning traces, allowing us to assess the model's reasoning over the context independently from its forecast accuracy. CorDP leverages LLMs solely to refine existing forecasts with context, enhancing their applicability in real-world forecasting pipelines. IC-DP proposes embedding historical examples of context-aided forecasting tasks in the prompt, substantially improving accuracy even for the largest models. Finally, RouteDP optimizes resource efficiency by using LLMs to estimate task difficulty, and routing the most challenging tasks to larger models. Evaluated on different kinds of context-aided forecasting tasks from the CiK benchmark, our strategies demonstrate distinct benefits over na\"ive prompting across LLMs of different sizes and families. These results open the door to further simple yet effective improvements in LLM-based context-aided forecasting.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
dsld: A Socially Relevant Tool for Teaching Statistics
Nov 06, 2024


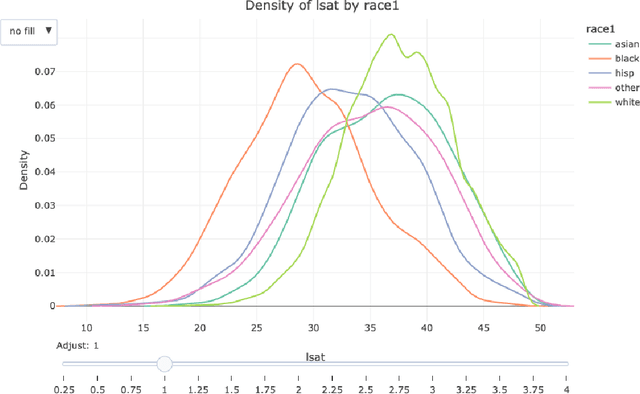
The growing power of data science can play a crucial role in addressing social discrimination, necessitating nuanced understanding and effective mitigation strategies of potential biases. Data Science Looks At Discrimination (dsld) is an R and Python package designed to provide users with a comprehensive toolkit of statistical and graphical methods for assessing possible discrimination related to protected groups, such as race, gender, and age. Our software offers techniques for discrimination analysis by identifying and mitigating confounding variables, along with methods for reducing bias in predictive models. In educational settings, dsld offers instructors powerful tools to teach important statistical principles through motivating real world examples of discrimination analysis. The inclusion of an 80-page Quarto book further supports users, from statistics educators to legal professionals, in effectively applying these analytical tools to real world scenarios.
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .
Lag-Llama: Towards Foundation Models for Time Series Forecasting
Oct 12, 2023
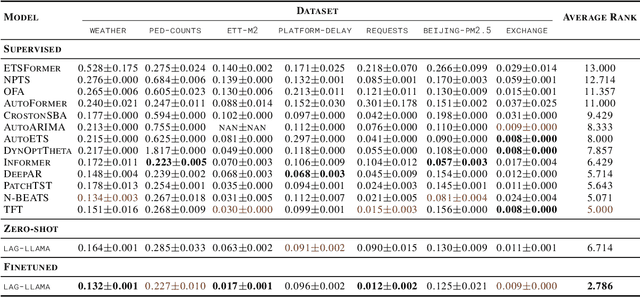

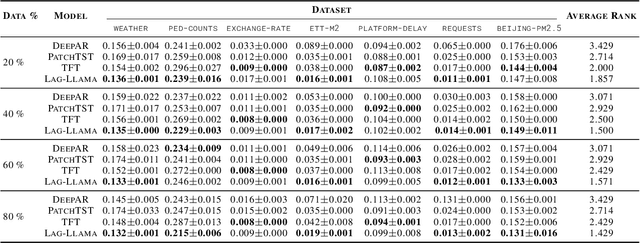
Aiming to build foundation models for time-series forecasting and study their scaling behavior, we present here our work-in-progress on Lag-Llama, a general-purpose univariate probabilistic time-series forecasting model trained on a large collection of time-series data. The model shows good zero-shot prediction capabilities on unseen "out-of-distribution" time-series datasets, outperforming supervised baselines. We use smoothly broken power-laws to fit and predict model scaling behavior. The open source code is made available at https://github.com/kashif/pytorch-transformer-ts.
TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series
Oct 02, 2023



We introduce a new model for multivariate probabilistic time series prediction, designed to flexibly address a range of tasks including forecasting, interpolation, and their combinations. Building on copula theory, we propose a simplified objective for the recently-introduced transformer-based attentional copulas (TACTiS), wherein the number of distributional parameters now scales linearly with the number of variables instead of factorially. The new objective requires the introduction of a training curriculum, which goes hand-in-hand with necessary changes to the original architecture. We show that the resulting model has significantly better training dynamics and achieves state-of-the-art performance across diverse real-world forecasting tasks, while maintaining the flexibility of prior work, such as seamless handling of unaligned and unevenly-sampled time series.
Extremely Simple Activation Shaping for Out-of-Distribution Detection
Sep 20, 2022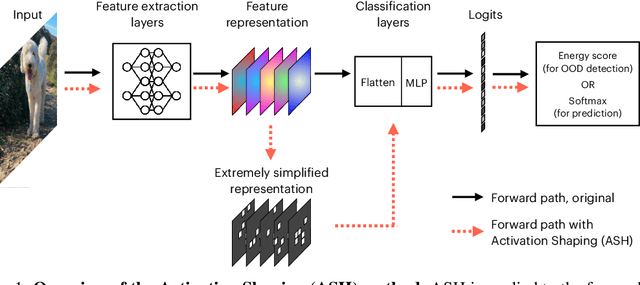

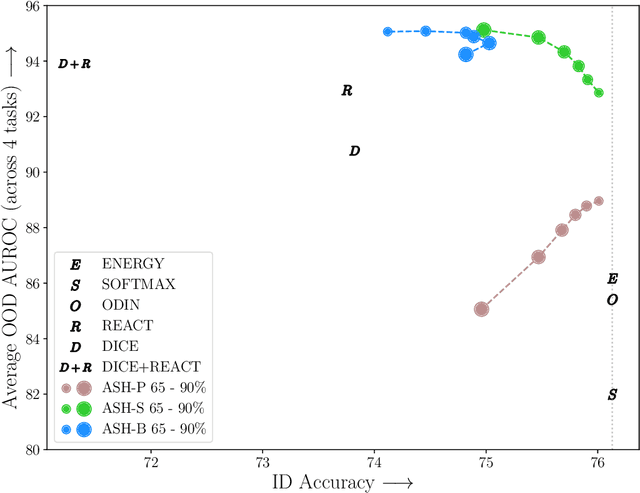
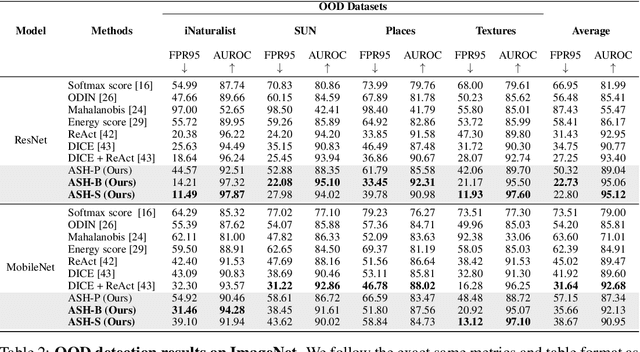
The separation between training and deployment of machine learning models implies that not all scenarios encountered in deployment can be anticipated during training, and therefore relying solely on advancements in training has its limits. Out-of-distribution (OOD) detection is an important area that stress-tests a model's ability to handle unseen situations: Do models know when they don't know? Existing OOD detection methods either incur extra training steps, additional data or make nontrivial modifications to the trained network. In contrast, in this work, we propose an extremely simple, post-hoc, on-the-fly activation shaping method, ASH, where a large portion (e.g. 90%) of a sample's activation at a late layer is removed, and the rest (e.g. 10%) simplified or lightly adjusted. The shaping is applied at inference time, and does not require any statistics calculated from training data. Experiments show that such a simple treatment enhances in-distribution and out-of-distribution sample distinction so as to allow state-of-the-art OOD detection on ImageNet, and does not noticeably deteriorate the in-distribution accuracy. We release alongside the paper two calls for explanation and validation, believing the collective power to further validate and understand the discovery. Calls, video and code can be found at: https://andrijazz.github.io/ash
Class-Incremental Learning with Cross-Space Clustering and Controlled Transfer
Aug 16, 2022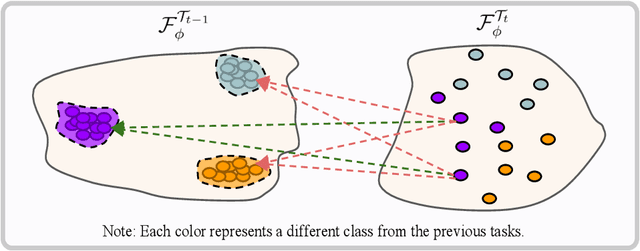
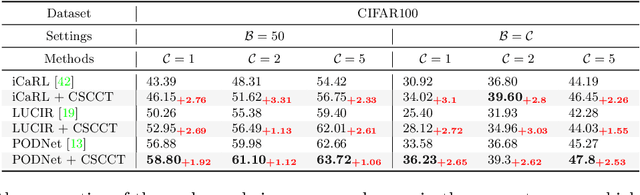
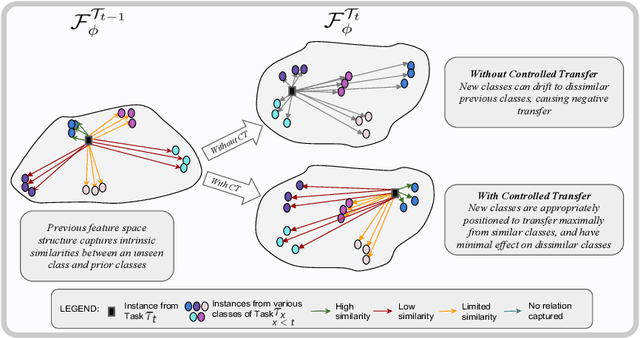
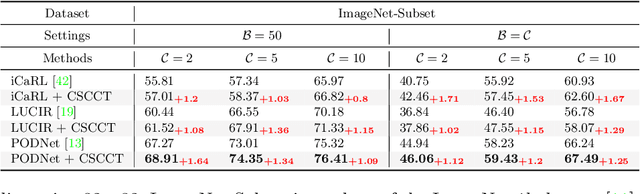
In class-incremental learning, the model is expected to learn new classes continually while maintaining knowledge on previous classes. The challenge here lies in preserving the model's ability to effectively represent prior classes in the feature space, while adapting it to represent incoming new classes. We propose two distillation-based objectives for class incremental learning that leverage the structure of the feature space to maintain accuracy on previous classes, as well as enable learning the new classes. In our first objective, termed cross-space clustering (CSC), we propose to use the feature space structure of the previous model to characterize directions of optimization that maximally preserve the class: directions that all instances of a specific class should collectively optimize towards, and those that they should collectively optimize away from. Apart from minimizing forgetting, this indirectly encourages the model to cluster all instances of a class in the current feature space, and gives rise to a sense of herd-immunity, allowing all samples of a class to jointly combat the model from forgetting the class. Our second objective termed controlled transfer (CT) tackles incremental learning from an understudied perspective of inter-class transfer. CT explicitly approximates and conditions the current model on the semantic similarities between incrementally arriving classes and prior classes. This allows the model to learn classes in such a way that it maximizes positive forward transfer from similar prior classes, thus increasing plasticity, and minimizes negative backward transfer on dissimilar prior classes, whereby strengthening stability. We perform extensive experiments on two benchmark datasets, adding our method (CSCCT) on top of three prominent class-incremental learning methods. We observe consistent performance improvement on a variety of experimental settings.
Learning Modular Structures That Generalize Out-of-Distribution
Aug 07, 2022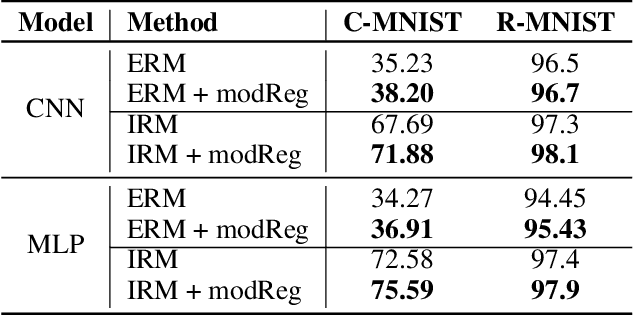
Out-of-distribution (O.O.D.) generalization remains to be a key challenge for real-world machine learning systems. We describe a method for O.O.D. generalization that, through training, encourages models to only preserve features in the network that are well reused across multiple training domains. Our method combines two complementary neuron-level regularizers with a probabilistic differentiable binary mask over the network, to extract a modular sub-network that achieves better O.O.D. performance than the original network. Preliminary evaluation on two benchmark datasets corroborates the promise of our method.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

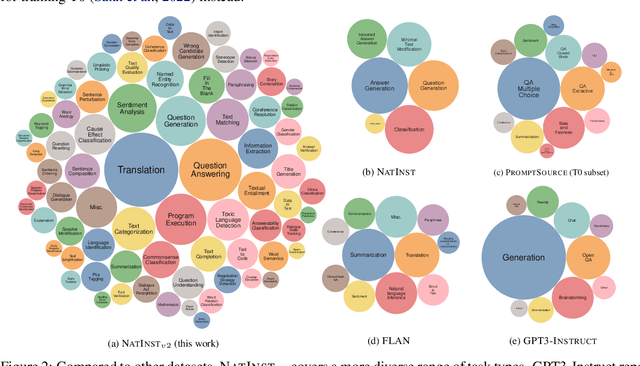
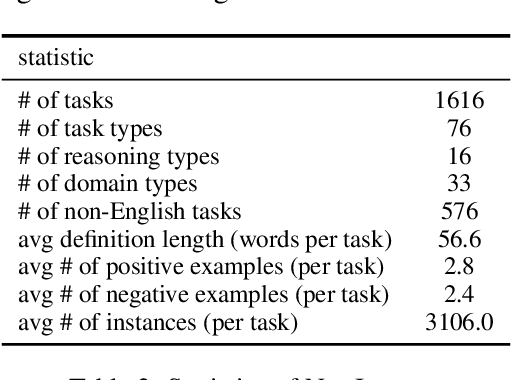
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.