 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Temporal Attention Fusion (CTAF) for Multimodal Physiological Signals in Self-Supervised Learning
Feb 02, 2026We study multimodal affect modeling when EEG and peripheral physiology are asynchronous, which most fusion methods ignore or handle with costly warping. We propose Cross-Temporal Attention Fusion (CTAF), a self-supervised module that learns soft bidirectional alignments between modalities and builds a robust clip embedding using time-aware cross attention, a lightweight fusion gate, and alignment-regularized contrastive objectives with optional weak supervision. On the K-EmoCon dataset, under leave-one-out cross-validation evaluation, CTAF yields higher cosine margins for matched pairs and better cross-modal token retrieval within one second, and it is competitive with the baseline on three-bin accuracy and macro-F1 while using few labels. Our contributions are a time-aware fusion mechanism that directly models correspondence, an alignment-driven self-supervised objective tailored to EEG and physiology, and an evaluation protocol that measures alignment quality itself. Our approach accounts for the coupling between the central and autonomic nervous systems in psychophysiological time series. These results indicate that CTAF is a strong step toward label-efficient, generalizable EEG-peripheral fusion under temporal asynchrony.
Beyond the Loss Curve: Scaling Laws, Active Learning, and the Limits of Learning from Exact Posteriors
Jan 30, 2026How close are neural networks to the best they could possibly do? Standard benchmarks cannot answer this because they lack access to the true posterior p(y|x). We use class-conditional normalizing flows as oracles that make exact posteriors tractable on realistic images (AFHQ, ImageNet). This enables five lines of investigation. Scaling laws: Prediction error decomposes into irreducible aleatoric uncertainty and reducible epistemic error; the epistemic component follows a power law in dataset size, continuing to shrink even when total loss plateaus. Limits of learning: The aleatoric floor is exactly measurable, and architectures differ markedly in how they approach it: ResNets exhibit clean power-law scaling while Vision Transformers stall in low-data regimes. Soft labels: Oracle posteriors contain learnable structure beyond class labels: training with exact posteriors outperforms hard labels and yields near-perfect calibration. Distribution shift: The oracle computes exact KL divergence of controlled perturbations, revealing that shift type matters more than shift magnitude: class imbalance barely affects accuracy at divergence values where input noise causes catastrophic degradation. Active learning: Exact epistemic uncertainty distinguishes genuinely informative samples from inherently ambiguous ones, improving sample efficiency. Our framework reveals that standard metrics hide ongoing learning, mask architectural differences, and cannot diagnose the nature of distribution shift.
Lag-Llama: Towards Foundation Models for Time Series Forecasting
Oct 12, 2023
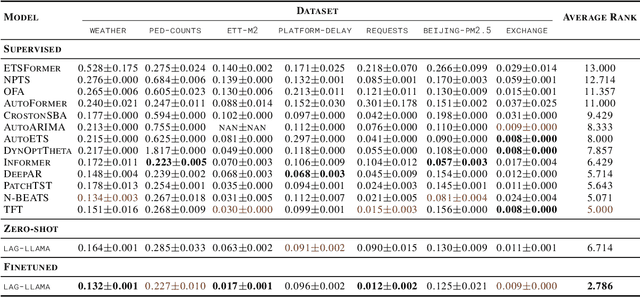

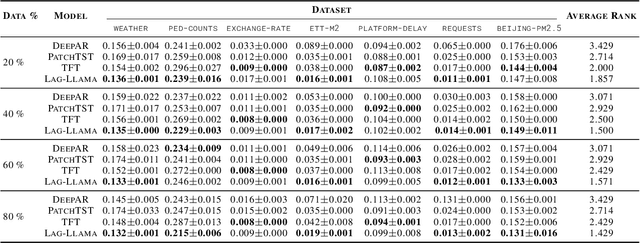
Aiming to build foundation models for time-series forecasting and study their scaling behavior, we present here our work-in-progress on Lag-Llama, a general-purpose univariate probabilistic time-series forecasting model trained on a large collection of time-series data. The model shows good zero-shot prediction capabilities on unseen "out-of-distribution" time-series datasets, outperforming supervised baselines. We use smoothly broken power-laws to fit and predict model scaling behavior. The open source code is made available at https://github.com/kashif/pytorch-transformer-ts.