 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAVE: Detecting and Explaining Commonsense Anomalies in Visual Environments
Oct 29, 2025Humans can naturally identify, reason about, and explain anomalies in their environment. In computer vision, this long-standing challenge remains limited to industrial defects or unrealistic, synthetically generated anomalies, failing to capture the richness and unpredictability of real-world anomalies. In this work, we introduce CAVE, the first benchmark of real-world visual anomalies. CAVE supports three open-ended tasks: anomaly description, explanation, and justification; with fine-grained annotations for visual grounding and categorizing anomalies based on their visual manifestations, their complexity, severity, and commonness. These annotations draw inspiration from cognitive science research on how humans identify and resolve anomalies, providing a comprehensive framework for evaluating Vision-Language Models (VLMs) in detecting and understanding anomalies. We show that state-of-the-art VLMs struggle with visual anomaly perception and commonsense reasoning, even with advanced prompting strategies. By offering a realistic and cognitively grounded benchmark, CAVE serves as a valuable resource for advancing research in anomaly detection and commonsense reasoning in VLMs.
Towards Adversarially Robust Vision-Language Models: Insights from Design Choices and Prompt Formatting Techniques
Jul 15, 2024Vision-Language Models (VLMs) have witnessed a surge in both research and real-world applications. However, as they are becoming increasingly prevalent, ensuring their robustness against adversarial attacks is paramount. This work systematically investigates the impact of model design choices on the adversarial robustness of VLMs against image-based attacks. Additionally, we introduce novel, cost-effective approaches to enhance robustness through prompt formatting. By rephrasing questions and suggesting potential adversarial perturbations, we demonstrate substantial improvements in model robustness against strong image-based attacks such as Auto-PGD. Our findings provide important guidelines for developing more robust VLMs, particularly for deployment in safety-critical environments.
Enhancing Context Through Contrast
Jan 06, 2024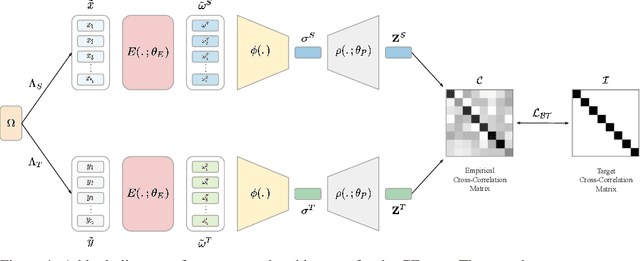
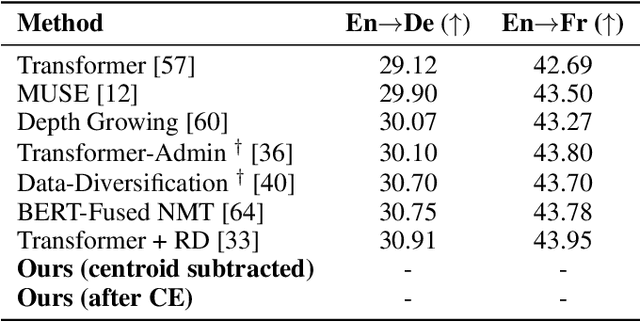
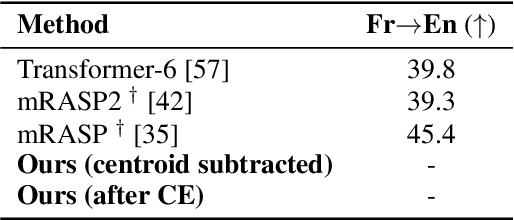
Neural machine translation benefits from semantically rich representations. Considerable progress in learning such representations has been achieved by language modelling and mutual information maximization objectives using contrastive learning. The language-dependent nature of language modelling introduces a trade-off between the universality of the learned representations and the model's performance on the language modelling tasks. Although contrastive learning improves performance, its success cannot be attributed to mutual information alone. We propose a novel Context Enhancement step to improve performance on neural machine translation by maximizing mutual information using the Barlow Twins loss. Unlike other approaches, we do not explicitly augment the data but view languages as implicit augmentations, eradicating the risk of disrupting semantic information. Further, our method does not learn embeddings from scratch and can be generalised to any set of pre-trained embeddings. Finally, we evaluate the language-agnosticism of our embeddings through language classification and use them for neural machine translation to compare with state-of-the-art approaches.
Lag-Llama: Towards Foundation Models for Time Series Forecasting
Oct 12, 2023
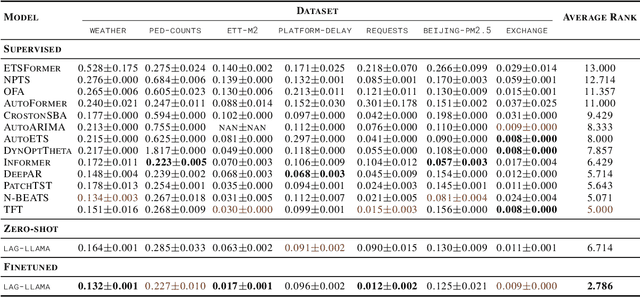

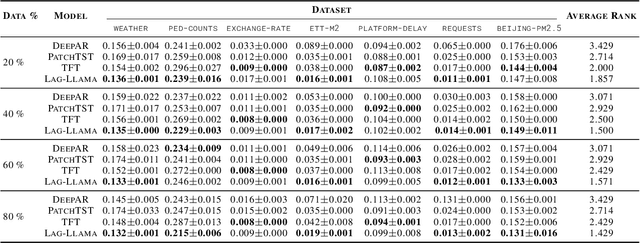
Aiming to build foundation models for time-series forecasting and study their scaling behavior, we present here our work-in-progress on Lag-Llama, a general-purpose univariate probabilistic time-series forecasting model trained on a large collection of time-series data. The model shows good zero-shot prediction capabilities on unseen "out-of-distribution" time-series datasets, outperforming supervised baselines. We use smoothly broken power-laws to fit and predict model scaling behavior. The open source code is made available at https://github.com/kashif/pytorch-transformer-ts.