 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Control in Early Exiting to Deploy Large Models at the Same Cost of Smaller Ones
Dec 26, 2024Early Exiting (EE) is a promising technique for speeding up inference by adaptively allocating compute resources to data points based on their difficulty. The approach enables predictions to exit at earlier layers for simpler samples while reserving more computation for challenging ones. In this study, we first present a novel perspective on the EE approach, showing that larger models deployed with EE can achieve higher performance than smaller models while maintaining similar computational costs. As existing EE approaches rely on confidence estimation at each exit point, we further study the impact of overconfidence on the controllability of the compute-performance trade-off. We introduce Performance Control Early Exiting (PCEE), a method that enables accuracy thresholding by basing decisions not on a data point's confidence but on the average accuracy of samples with similar confidence levels from a held-out validation set. In our experiments, we show that PCEE offers a simple yet computationally efficient approach that provides better control over performance than standard confidence-based approaches, and allows us to scale up model sizes to yield performance gain while reducing the computational cost.
The Pitfalls of Memorization: When Memorization Hurts Generalization
Dec 10, 2024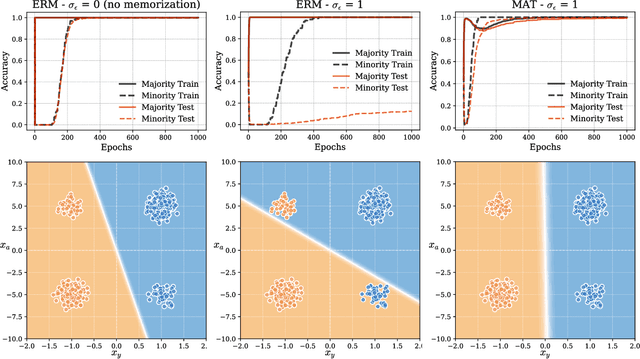

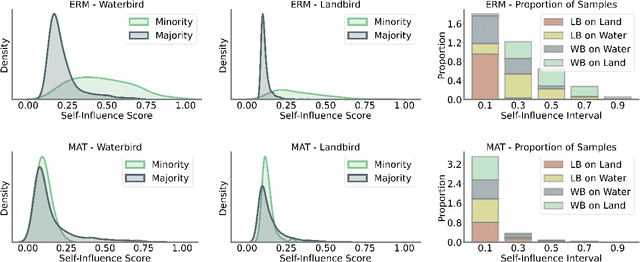

Neural networks often learn simple explanations that fit the majority of the data while memorizing exceptions that deviate from these explanations.This behavior leads to poor generalization when the learned explanations rely on spurious correlations. In this work, we formalize the interplay between memorization and generalization, showing that spurious correlations would particularly lead to poor generalization when are combined with memorization. Memorization can reduce training loss to zero, leaving no incentive to learn robust, generalizable patterns. To address this, we propose memorization-aware training (MAT), which uses held-out predictions as a signal of memorization to shift a model's logits. MAT encourages learning robust patterns invariant across distributions, improving generalization under distribution shifts.
Towards Adversarially Robust Vision-Language Models: Insights from Design Choices and Prompt Formatting Techniques
Jul 15, 2024Vision-Language Models (VLMs) have witnessed a surge in both research and real-world applications. However, as they are becoming increasingly prevalent, ensuring their robustness against adversarial attacks is paramount. This work systematically investigates the impact of model design choices on the adversarial robustness of VLMs against image-based attacks. Additionally, we introduce novel, cost-effective approaches to enhance robustness through prompt formatting. By rephrasing questions and suggesting potential adversarial perturbations, we demonstrate substantial improvements in model robustness against strong image-based attacks such as Auto-PGD. Our findings provide important guidelines for developing more robust VLMs, particularly for deployment in safety-critical environments.