 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
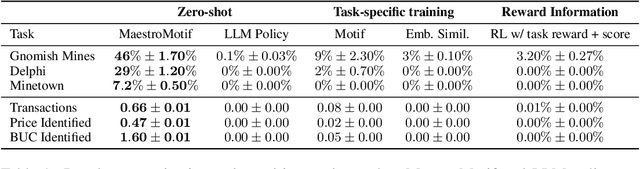

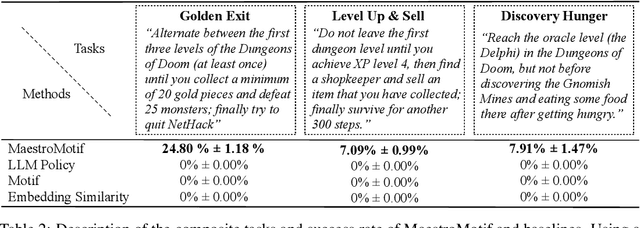
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
The Pitfalls of Memorization: When Memorization Hurts Generalization
Dec 10, 2024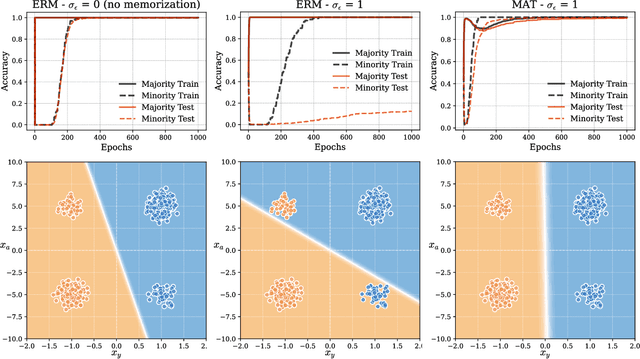

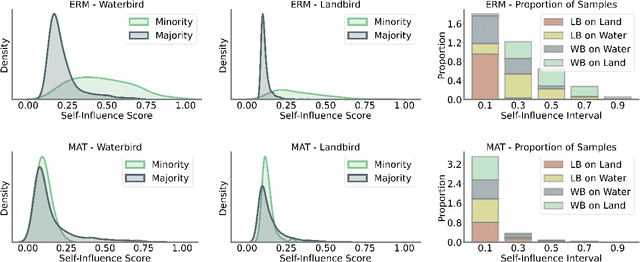

Neural networks often learn simple explanations that fit the majority of the data while memorizing exceptions that deviate from these explanations.This behavior leads to poor generalization when the learned explanations rely on spurious correlations. In this work, we formalize the interplay between memorization and generalization, showing that spurious correlations would particularly lead to poor generalization when are combined with memorization. Memorization can reduce training loss to zero, leaving no incentive to learn robust, generalizable patterns. To address this, we propose memorization-aware training (MAT), which uses held-out predictions as a signal of memorization to shift a model's logits. MAT encourages learning robust patterns invariant across distributions, improving generalization under distribution shifts.
Compositional Risk Minimization
Oct 08, 2024



In this work, we tackle a challenging and extreme form of subpopulation shift, which is termed compositional shift. Under compositional shifts, some combinations of attributes are totally absent from the training distribution but present in the test distribution. We model the data with flexible additive energy distributions, where each energy term represents an attribute, and derive a simple alternative to empirical risk minimization termed compositional risk minimization (CRM). We first train an additive energy classifier to predict the multiple attributes and then adjust this classifier to tackle compositional shifts. We provide an extensive theoretical analysis of CRM, where we show that our proposal extrapolates to special affine hulls of seen attribute combinations. Empirical evaluations on benchmark datasets confirms the improved robustness of CRM compared to other methods from the literature designed to tackle various forms of subpopulation shifts.
WorldSense: A Synthetic Benchmark for Grounded Reasoning in Large Language Models
Nov 27, 2023We propose WorldSense, a benchmark designed to assess the extent to which LLMs are consistently able to sustain tacit world models, by testing how they draw simple inferences from descriptions of simple arrangements of entities. Worldsense is a synthetic benchmark with three problem types, each with their own trivial control, which explicitly avoids bias by decorrelating the abstract structure of problems from the vocabulary and expressions, and by decorrelating all problem subparts with the correct response. We run our benchmark on three state-of-the-art chat-LLMs (GPT3.5, GPT4 and Llama2-chat) and show that these models make errors even with as few as three objects. Furthermore, they have quite heavy response biases, preferring certain responses irrespective of the question. Errors persist even with chain-of-thought prompting and in-context learning. Lastly, we show that while finetuning on similar problems does result in substantial improvements -- within- and out-of-distribution -- the finetuned models do not generalise beyond a constraint problem space.
Self-Supervised Disentanglement by Leveraging Structure in Data Augmentations
Nov 15, 2023

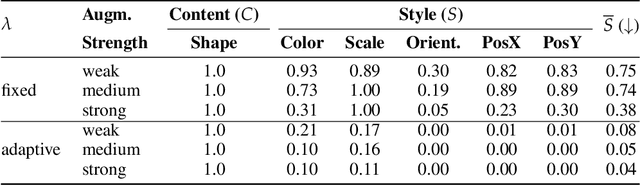

Self-supervised representation learning often uses data augmentations to induce some invariance to "style" attributes of the data. However, with downstream tasks generally unknown at training time, it is difficult to deduce a priori which attributes of the data are indeed "style" and can be safely discarded. To address this, we introduce a more principled approach that seeks to disentangle style features rather than discard them. The key idea is to add multiple style embedding spaces where: (i) each is invariant to all-but-one augmentation; and (ii) joint entropy is maximized. We formalize our structured data-augmentation procedure from a causal latent-variable-model perspective, and prove identifiability of both content and (multiple blocks of) style variables. We empirically demonstrate the benefits of our approach on synthetic datasets and then present promising but limited results on ImageNet.
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
Sep 29, 2023



Exploring rich environments and evaluating one's actions without prior knowledge is immensely challenging. In this paper, we propose Motif, a general method to interface such prior knowledge from a Large Language Model (LLM) with an agent. Motif is based on the idea of grounding LLMs for decision-making without requiring them to interact with the environment: it elicits preferences from an LLM over pairs of captions to construct an intrinsic reward, which is then used to train agents with reinforcement learning. We evaluate Motif's performance and behavior on the challenging, open-ended and procedurally-generated NetHack game. Surprisingly, by only learning to maximize its intrinsic reward, Motif achieves a higher game score than an algorithm directly trained to maximize the score itself. When combining Motif's intrinsic reward with the environment reward, our method significantly outperforms existing approaches and makes progress on tasks where no advancements have ever been made without demonstrations. Finally, we show that Motif mostly generates intuitive human-aligned behaviors which can be steered easily through prompt modifications, while scaling well with the LLM size and the amount of information given in the prompt.
Discovering environments with XRM
Sep 28, 2023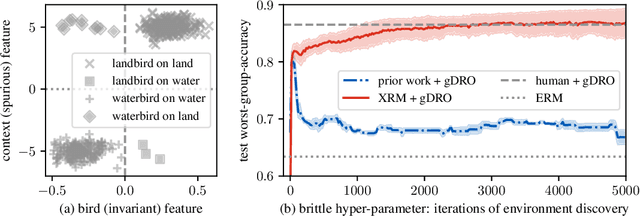
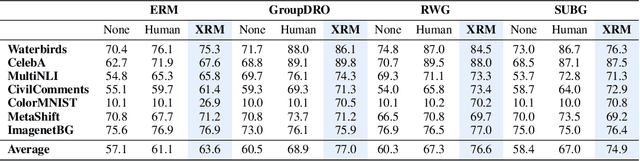
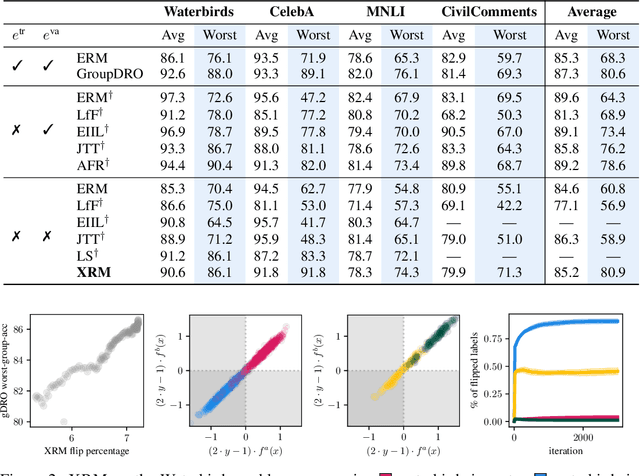

Successful out-of-distribution generalization requires environment annotations. Unfortunately, these are resource-intensive to obtain, and their relevance to model performance is limited by the expectations and perceptual biases of human annotators. Therefore, to enable robust AI systems across applications, we must develop algorithms to automatically discover environments inducing broad generalization. Current proposals, which divide examples based on their training error, suffer from one fundamental problem. These methods add hyper-parameters and early-stopping criteria that are impossible to tune without a validation set with human-annotated environments, the very information subject to discovery. In this paper, we propose Cross-Risk-Minimization (XRM) to address this issue. XRM trains two twin networks, each learning from one random half of the training data, while imitating confident held-out mistakes made by its sibling. XRM provides a recipe for hyper-parameter tuning, does not require early-stopping, and can discover environments for all training and validation data. Domain generalization algorithms built on top of XRM environments achieve oracle worst-group-accuracy, solving a long-standing problem in out-of-distribution generalization.
PUG: Photorealistic and Semantically Controllable Synthetic Data for Representation Learning
Aug 08, 2023



Synthetic image datasets offer unmatched advantages for designing and evaluating deep neural networks: they make it possible to (i) render as many data samples as needed, (ii) precisely control each scene and yield granular ground truth labels (and captions), (iii) precisely control distribution shifts between training and testing to isolate variables of interest for sound experimentation. Despite such promise, the use of synthetic image data is still limited -- and often played down -- mainly due to their lack of realism. Most works therefore rely on datasets of real images, which have often been scraped from public images on the internet, and may have issues with regards to privacy, bias, and copyright, while offering little control over how objects precisely appear. In this work, we present a path to democratize the use of photorealistic synthetic data: we develop a new generation of interactive environments for representation learning research, that offer both controllability and realism. We use the Unreal Engine, a powerful game engine well known in the entertainment industry, to produce PUG (Photorealistic Unreal Graphics) environments and datasets for representation learning. In this paper, we demonstrate the potential of PUG to enable more rigorous evaluations of vision models.
Predicting masked tokens in stochastic locations improves masked image modeling
Jul 31, 2023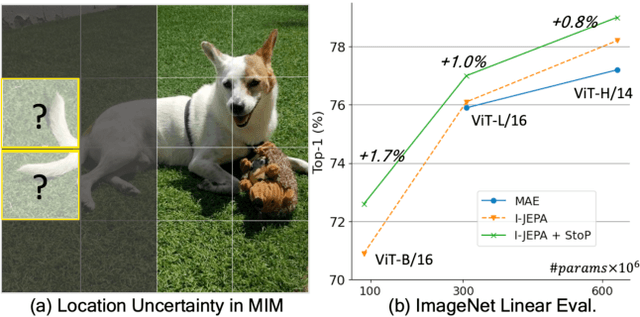
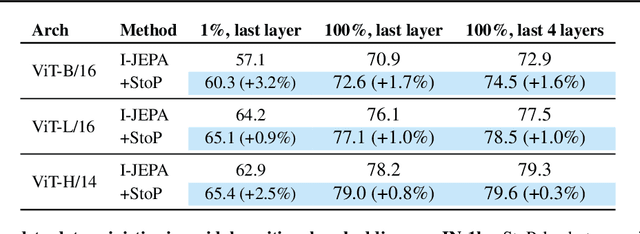
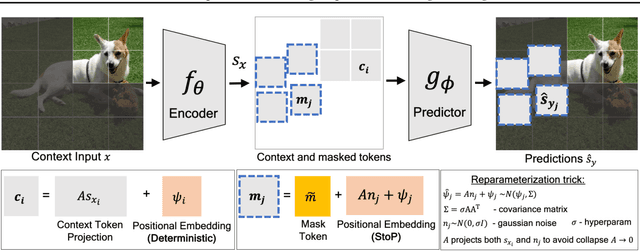
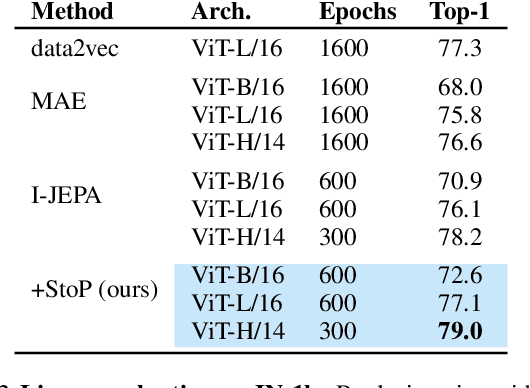
Self-supervised learning is a promising paradigm in deep learning that enables learning from unlabeled data by constructing pretext tasks that require learning useful representations. In natural language processing, the dominant pretext task has been masked language modeling (MLM), while in computer vision there exists an equivalent called Masked Image Modeling (MIM). However, MIM is challenging because it requires predicting semantic content in accurate locations. E.g, given an incomplete picture of a dog, we can guess that there is a tail, but we cannot determine its exact location. In this work, we propose FlexPredict, a stochastic model that addresses this challenge by incorporating location uncertainty into the model. Specifically, we condition the model on stochastic masked token positions to guide the model toward learning features that are more robust to location uncertainties. Our approach improves downstream performance on a range of tasks, e.g, compared to MIM baselines, FlexPredict boosts ImageNet linear probing by 1.6% with ViT-B and by 2.5% for semi-supervised video segmentation using ViT-L.
Identifiability of Discretized Latent Coordinate Systems via Density Landmarks Detection
Jun 28, 2023Disentanglement aims to recover meaningful latent ground-truth factors from only the observed distribution. Identifiability provides the theoretical grounding for disentanglement to be well-founded. Unfortunately, unsupervised identifiability of independent latent factors is a theoretically proven impossibility in the i.i.d. setting under a general nonlinear smooth map from factors to observations. In this work, we show that, remarkably, it is possible to recover discretized latent coordinates under a highly generic nonlinear smooth mapping (a diffeomorphism) without any additional inductive bias on the mapping. This is, assuming that latent density has axis-aligned discontinuity landmarks, but without making the unrealistic assumption of statistical independence of the factors. We introduce this novel form of identifiability, termed quantized coordinate identifiability, and provide a comprehensive proof of the recovery of discretized coordinates.