 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
WorldSense: A Synthetic Benchmark for Grounded Reasoning in Large Language Models
Nov 27, 2023We propose WorldSense, a benchmark designed to assess the extent to which LLMs are consistently able to sustain tacit world models, by testing how they draw simple inferences from descriptions of simple arrangements of entities. Worldsense is a synthetic benchmark with three problem types, each with their own trivial control, which explicitly avoids bias by decorrelating the abstract structure of problems from the vocabulary and expressions, and by decorrelating all problem subparts with the correct response. We run our benchmark on three state-of-the-art chat-LLMs (GPT3.5, GPT4 and Llama2-chat) and show that these models make errors even with as few as three objects. Furthermore, they have quite heavy response biases, preferring certain responses irrespective of the question. Errors persist even with chain-of-thought prompting and in-context learning. Lastly, we show that while finetuning on similar problems does result in substantial improvements -- within- and out-of-distribution -- the finetuned models do not generalise beyond a constraint problem space.
GAIA: a benchmark for General AI Assistants
Nov 21, 2023



We introduce GAIA, a benchmark for General AI Assistants that, if solved, would represent a milestone in AI research. GAIA proposes real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency. GAIA questions are conceptually simple for humans yet challenging for most advanced AIs: we show that human respondents obtain 92\% vs. 15\% for GPT-4 equipped with plugins. This notable performance disparity contrasts with the recent trend of LLMs outperforming humans on tasks requiring professional skills in e.g. law or chemistry. GAIA's philosophy departs from the current trend in AI benchmarks suggesting to target tasks that are ever more difficult for humans. We posit that the advent of Artificial General Intelligence (AGI) hinges on a system's capability to exhibit similar robustness as the average human does on such questions. Using GAIA's methodology, we devise 466 questions and their answer. We release our questions while retaining answers to 300 of them to power a leader-board available at https://huggingface.co/gaia-benchmark.
Self-Supervised Learning with Lie Symmetries for Partial Differential Equations
Jul 11, 2023Machine learning for differential equations paves the way for computationally efficient alternatives to numerical solvers, with potentially broad impacts in science and engineering. Though current algorithms typically require simulated training data tailored to a given setting, one may instead wish to learn useful information from heterogeneous sources, or from real dynamical systems observations that are messy or incomplete. In this work, we learn general-purpose representations of PDEs from heterogeneous data by implementing joint embedding methods for self-supervised learning (SSL), a framework for unsupervised representation learning that has had notable success in computer vision. Our representation outperforms baseline approaches to invariant tasks, such as regressing the coefficients of a PDE, while also improving the time-stepping performance of neural solvers. We hope that our proposed methodology will prove useful in the eventual development of general-purpose foundation models for PDEs.
On Inductive Biases for Machine Learning in Data Constrained Settings
Feb 21, 2023Learning with limited data is one of the biggest problems of machine learning. Current approaches to this issue consist in learning general representations from huge amounts of data before fine-tuning the model on a small dataset of interest. While such technique, coined transfer learning, is very effective in domains such as computer vision or natural langage processing, it does not yet solve common problems of deep learning such as model interpretability or the overall need for data. This thesis explores a different answer to the problem of learning expressive models in data constrained settings: instead of relying on big datasets to learn neural networks, we will replace some modules by known functions reflecting the structure of the data. Very often, these functions will be drawn from the rich literature of kernel methods. Indeed, many kernels can reflect the underlying structure of the data, thus sparing learning parameters to some extent. Our approach falls under the hood of "inductive biases", which can be defined as hypothesis on the data at hand restricting the space of models to explore during learning. We demonstrate the effectiveness of this approach in the context of sequences, such as sentences in natural language or protein sequences, and graphs, such as molecules. We also highlight the relationship between our work and recent advances in deep learning. Additionally, we study convex machine learning models. Here, rather than proposing new models, we wonder which proportion of the samples in a dataset is really needed to learn a "good" model. More precisely, we study the problem of safe sample screening, i.e, executing simple tests to discard uninformative samples from a dataset even before fitting a machine learning model, without affecting the optimal model. Such techniques can be used to prune datasets or mine for rare samples.
Augmented Language Models: a Survey
Feb 15, 2023



This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability, consistency, and scalability issues.
Variance Covariance Regularization Enforces Pairwise Independence in Self-Supervised Representations
Sep 29, 2022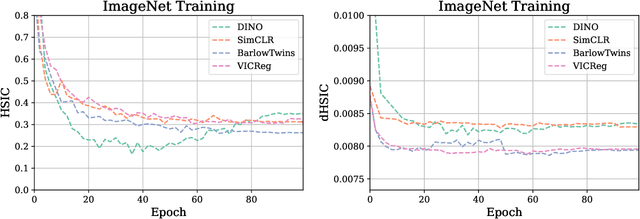
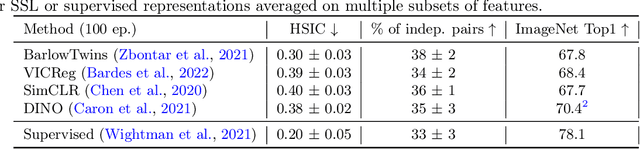
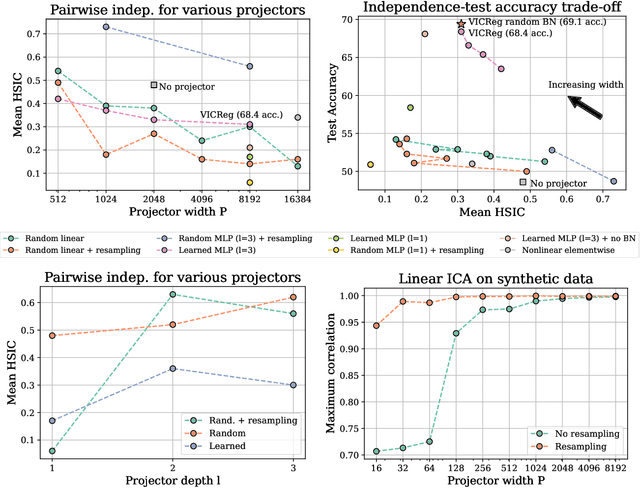

Self-Supervised Learning (SSL) methods such as VICReg, Barlow Twins or W-MSE avoid collapse of their joint embedding architectures by constraining or regularizing the covariance matrix of their projector's output. This study highlights important properties of such strategy, which we coin Variance-Covariance regularization (VCReg). More precisely, we show that VCReg enforces pairwise independence between the features of the learned representation. This result emerges by bridging VCReg applied on the projector's output to kernel independence criteria applied on the projector's input. This provides the first theoretical motivations and explanations of VCReg. We empirically validate our findings where (i) we observe that SSL methods employing VCReg learn visual representations with greater pairwise independence than other methods, (i) we put in evidence which projector's characteristics favor pairwise independence, and show it to emerge independently from learning the projector, (ii) we use these findings to obtain nontrivial performance gains for VICReg, (iii) we demonstrate that the scope of VCReg goes beyond SSL by using it to solve Independent Component Analysis. We hope that our findings will support the adoption of VCReg in SSL and beyond.
GraphiT: Encoding Graph Structure in Transformers
Jun 10, 2021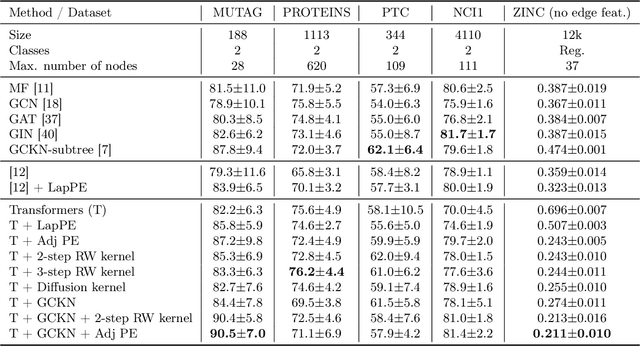
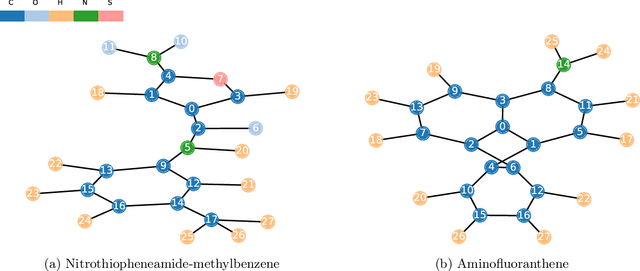
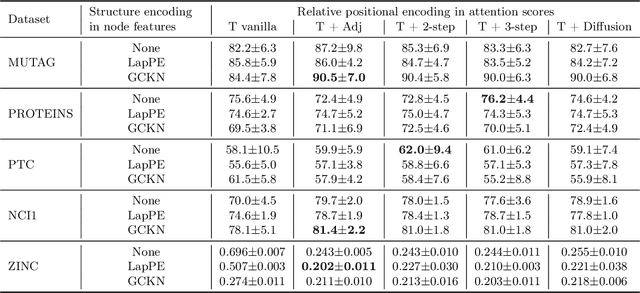
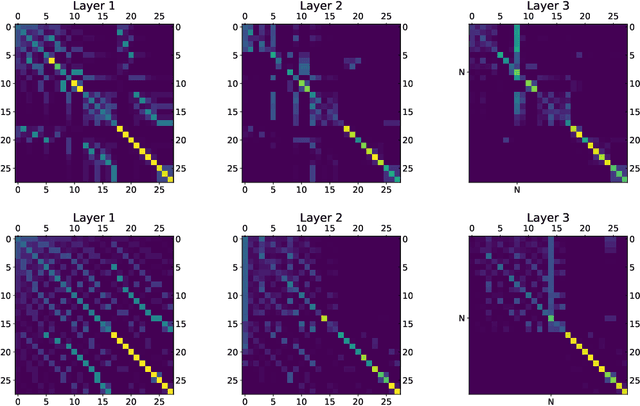
We show that viewing graphs as sets of node features and incorporating structural and positional information into a transformer architecture is able to outperform representations learned with classical graph neural networks (GNNs). Our model, GraphiT, encodes such information by (i) leveraging relative positional encoding strategies in self-attention scores based on positive definite kernels on graphs, and (ii) enumerating and encoding local sub-structures such as paths of short length. We thoroughly evaluate these two ideas on many classification and regression tasks, demonstrating the effectiveness of each of them independently, as well as their combination. In addition to performing well on standard benchmarks, our model also admits natural visualization mechanisms for interpreting graph motifs explaining the predictions, making it a potentially strong candidate for scientific applications where interpretation is important. Code available at https://github.com/inria-thoth/GraphiT.
An Optimal Transport Kernel for Feature Aggregation and its Relationship to Attention
Jun 23, 2020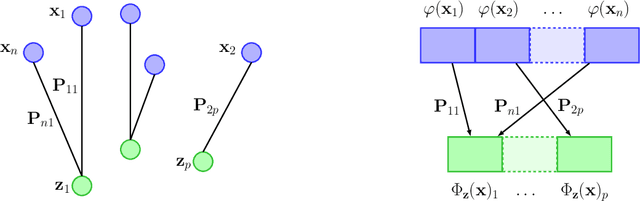
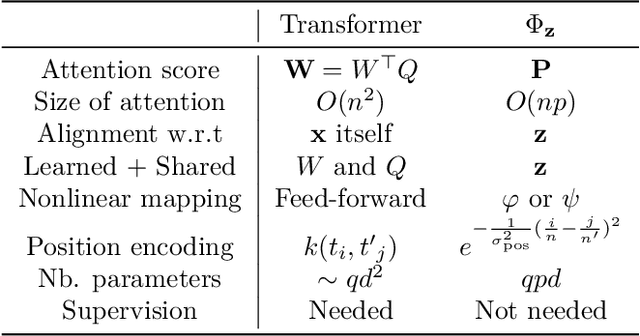

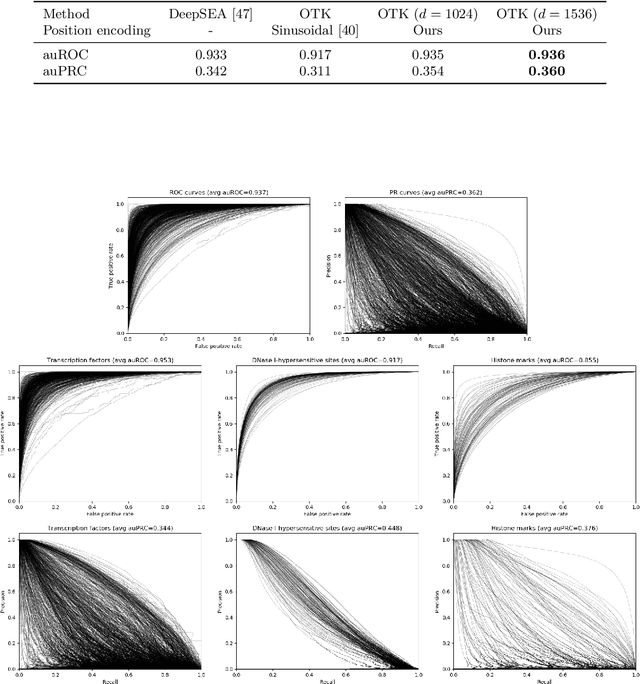
We introduce a kernel for sets of features based on an optimal transport distance, along with an explicit embedding function. Our approach addresses the problem of feature aggregation, or pooling, for sets that exhibit long-range dependencies between their members. More precisely, our embedding aggregates the features of a given set according to the transport plan between the set and a reference shared across the data set. Unlike traditional hand-crafted kernels, our embedding can be optimized for a specific task or data set. It also has a natural connection to attention mechanisms in neural networks, which are commonly used to deal with sets, yet requires less data. Our embedding is particularly suited for biological sequence classification tasks and shows promising results for natural language sequences. We provide an implementation of our embedding that can be used alone or as a module in larger learning models. Our code is freely available at https://github.com/claying/OTK.