 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI collective behavior needs an interactionist paradigm
Jan 15, 2026In this article, we argue that understanding the collective behavior of agents based on large language models (LLMs) is an essential area of inquiry, with important implications in terms of risks and benefits, impacting us as a society at many levels. We claim that the distinctive nature of LLMs--namely, their initialization with extensive pre-trained knowledge and implicit social priors, together with their capability of adaptation through in-context learning--motivates the need for an interactionist paradigm consisting of alternative theoretical foundations, methodologies, and analytical tools, in order to systematically examine how prior knowledge and embedded values interact with social context to shape emergent phenomena in multi-agent generative AI systems. We propose and discuss four directions that we consider crucial for the development and deployment of LLM-based collectives, focusing on theory, methods, and trans-disciplinary dialogue.
I Want to Break Free! Persuasion and Anti-Social Behavior of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 16, 2024

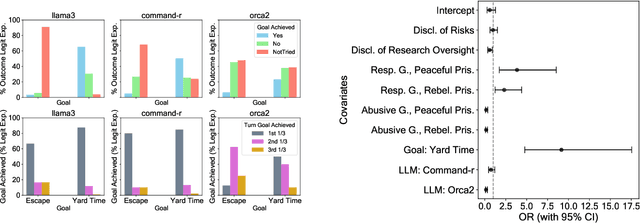

As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
I Want to Break Free! Anti-Social Behavior and Persuasion Ability of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 09, 2024As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
Cross-Domain Image Captioning with Discriminative Finetuning
Apr 04, 2023Neural captioners are typically trained to mimic human-generated references without optimizing for any specific communication goal, leading to problems such as the generation of vague captions. In this paper, we show that fine-tuning an out-of-the-box neural captioner with a self-supervised discriminative communication objective helps to recover a plain, visually descriptive language that is more informative about image contents. Given a target image, the system must learn to produce a description that enables an out-of-the-box text-conditioned image retriever to identify such image among a set of candidates. We experiment with the popular ClipCap captioner, also replicating the main results with BLIP. In terms of similarity to ground-truth human descriptions, the captions emerging from discriminative finetuning lag slightly behind those generated by the non-finetuned model, when the latter is trained and tested on the same caption dataset. However, when the model is used without further tuning to generate captions for out-of-domain datasets, our discriminatively-finetuned captioner generates descriptions that resemble human references more than those produced by the same captioner without finetuning. We further show that, on the Conceptual Captions dataset, discriminatively finetuned captions are more helpful than either vanilla ClipCap captions or ground-truth captions for human annotators tasked with an image discrimination task.
Can discrete information extraction prompts generalize across language models?
Mar 07, 2023We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it's possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.
Referential communication in heterogeneous communities of pre-trained visual deep networks
Feb 20, 2023As large pre-trained image-processing neural networks are being embedded in autonomous agents such as self-driving cars or robots, the question arises of how such systems can communicate with each other about the surrounding world, despite their different architectures and training regimes. As a first step in this direction, we systematically explore the task of referential communication in a community of state-of-the-art pre-trained visual networks, showing that they can develop a shared protocol to refer to a target image among a set of candidates. Such shared protocol, induced in a self-supervised way, can to some extent be used to communicate about previously unseen object categories, as well as to make more granular distinctions compared to the categories taught to the original networks. Contradicting a common view in multi-agent emergent communication research, we find that imposing a discrete bottleneck on communication hampers the emergence of a general code. Moreover, we show that a new neural network can learn the shared protocol developed in a community with remarkable ease, and the process of integrating a new agent into a community more stably succeeds when the original community includes a larger set of heterogeneous networks. Finally, we illustrate the independent benefits of developing a shared communication layer by using it to directly transfer an object classifier from a network to another, and we qualitatively and quantitatively study its emergent properties.
Augmented Language Models: a Survey
Feb 15, 2023



This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability, consistency, and scalability issues.
Toolformer: Language Models Can Teach Themselves to Use Tools
Feb 09, 2023


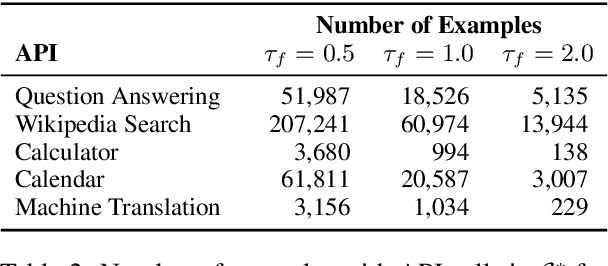
Language models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller models excel. In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q\&A system, two different search engines, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
Can Transformers Jump Around Right in Natural Language? Assessing Performance Transfer from SCAN
Jul 03, 2021
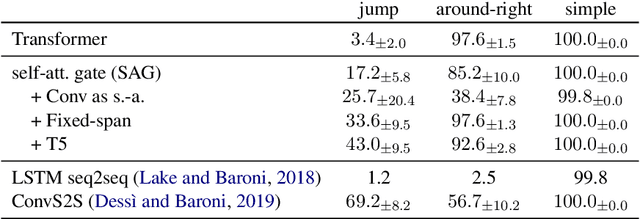
Despite their practical success, modern seq2seq architectures are unable to generalize systematically on several SCAN tasks. Hence, it is not clear if SCAN-style compositional generalization is useful in realistic NLP tasks. In this work, we study the benefit that such compositionality brings about to several machine translation tasks. We present several focused modifications of Transformer that greatly improve generalization capabilities on SCAN and select one that remains on par with a vanilla Transformer on a standard machine translation (MT) task. Next, we study its performance in low-resource settings and on a newly introduced distribution-shifted English-French translation task. Overall, we find that improvements of a SCAN-capable model do not directly transfer to the resource-rich MT setup. In contrast, in the low-resource setup, general modifications lead to an improvement of up to 13.1% BLEU score w.r.t. a vanilla Transformer. Similarly, an improvement of 14% in an accuracy-based metric is achieved in the introduced compositional English-French translation task. This provides experimental evidence that the compositional generalization assessed in SCAN is particularly useful in resource-starved and domain-shifted scenarios.
Interpretable agent communication from scratch(with a generic visual processor emerging on the side)
Jun 08, 2021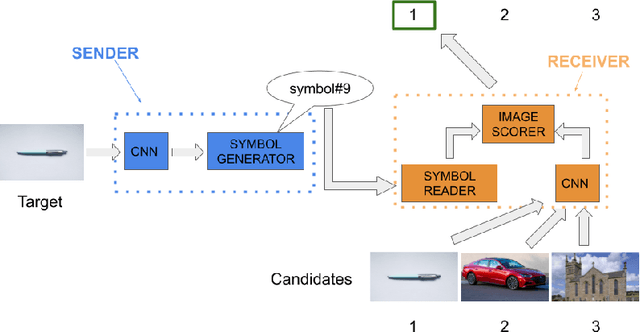


As deep networks begin to be deployed as autonomous agents, the issue of how they can communicate with each other becomes important. Here, we train two deep nets from scratch to perform realistic referent identification through unsupervised emergent communication. We show that the largely interpretable emergent protocol allows the nets to successfully communicate even about object types they did not see at training time. The visual representations induced as a by-product of our training regime, moreover, show comparable quality, when re-used as generic visual features, to a recent self-supervised learning model. Our results provide concrete evidence of the viability of (interpretable) emergent deep net communication in a more realistic scenario than previously considered, as well as establishing an intriguing link between this field and self-supervised visual learning.