 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?
Jun 12, 2025Recent reasoning models show the ability to reflect, backtrack, and self-validate their reasoning, which is crucial in spotting mistakes and arriving at accurate solutions. A natural question that arises is how effectively models can perform such self-reevaluation. We tackle this question by investigating how well reasoning models identify and recover from four types of unhelpful thoughts: uninformative rambling thoughts, thoughts irrelevant to the question, thoughts misdirecting the question as a slightly different question, and thoughts that lead to incorrect answers. We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant performance drops. Models tend to naively continue the line of reasoning of the injected irrelevant thoughts, which showcases that their self-reevaluation abilities are far from a general "meta-cognitive" awareness. Moreover, we observe non/inverse-scaling trends, where larger models struggle more than smaller ones to recover from short irrelevant thoughts, even when instructed to reevaluate their reasoning. We demonstrate the implications of these findings with a jailbreak experiment using irrelevant thought injection, showing that the smallest models are the least distracted by harmful-response-triggering thoughts. Overall, our findings call for improvement in self-reevaluation of reasoning models to develop better reasoning and safer systems.
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
Nov 25, 2024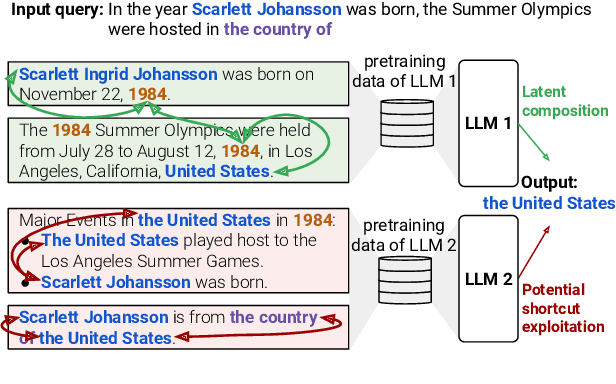
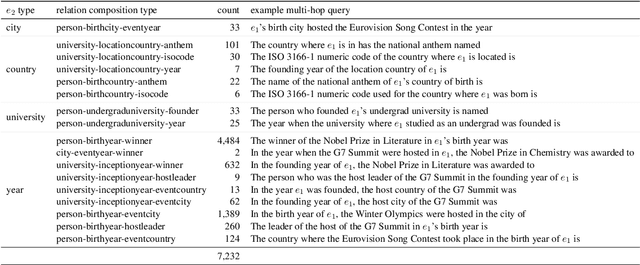
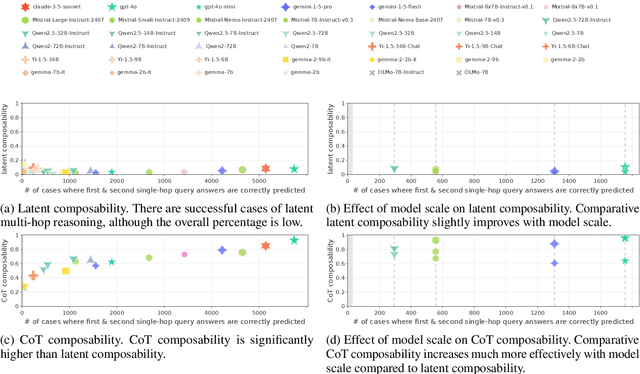

We evaluate how well Large Language Models (LLMs) latently recall and compose facts to answer multi-hop queries like "In the year Scarlett Johansson was born, the Summer Olympics were hosted in the country of". One major challenge in evaluating this ability is that LLMs may have developed shortcuts by encounters of the head entity "Scarlett Johansson" and the answer entity "United States" in the same training sequences or merely guess the answer based on frequency-based priors. To prevent shortcuts, we exclude test queries where the head and answer entities co-appear in pretraining corpora. Through careful selection of relations and facts and systematic removal of cases where models might guess answers or exploit partial matches, we construct an evaluation dataset SOCRATES (ShOrtCut-fRee lATent rEaSoning). We observe that LLMs demonstrate promising latent multi-hop reasoning abilities without exploiting shortcuts, but only for certain types of queries. For queries requiring latent recall of countries as the intermediate answer, the best models achieve 80% latent composability, but this drops to just 5% for the recall of years. Comparisons with Chain-of-Thought composability highlight a significant gap between the ability of models to reason latently versus explicitly. Analysis reveals that latent representations of the intermediate answer are constructed more often in queries with higher latent composability, and shows the emergence of latent multi-hop reasoning during pretraining.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


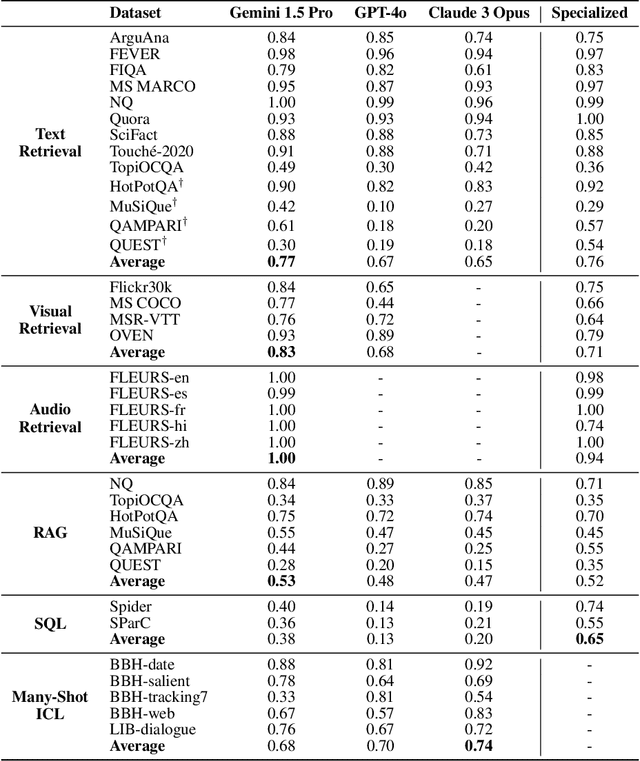
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Do Large Language Models Latently Perform Multi-Hop Reasoning?
Feb 26, 2024



We study whether Large Language Models (LLMs) latently perform multi-hop reasoning with complex prompts such as "The mother of the singer of 'Superstition' is". We look for evidence of a latent reasoning pathway where an LLM (1) latently identifies "the singer of 'Superstition'" as Stevie Wonder, the bridge entity, and (2) uses its knowledge of Stevie Wonder's mother to complete the prompt. We analyze these two hops individually and consider their co-occurrence as indicative of latent multi-hop reasoning. For the first hop, we test if changing the prompt to indirectly mention the bridge entity instead of any other entity increases the LLM's internal recall of the bridge entity. For the second hop, we test if increasing this recall causes the LLM to better utilize what it knows about the bridge entity. We find strong evidence of latent multi-hop reasoning for the prompts of certain relation types, with the reasoning pathway used in more than 80% of the prompts. However, the utilization is highly contextual, varying across different types of prompts. Also, on average, the evidence for the second hop and the full multi-hop traversal is rather moderate and only substantial for the first hop. Moreover, we find a clear scaling trend with increasing model size for the first hop of reasoning but not for the second hop. Our experimental findings suggest potential challenges and opportunities for future development and applications of LLMs.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Prompt Optimisation with Random Sampling
Nov 16, 2023


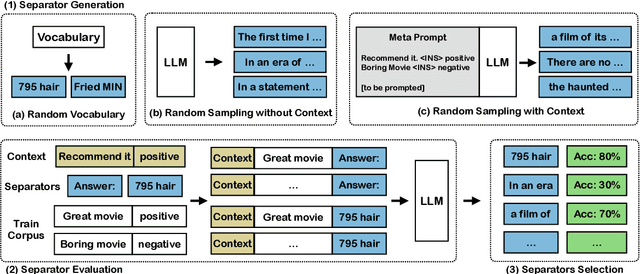
Using the generative nature of a language model to generate task-relevant separators has shown competitive results compared to human-curated prompts like "TL;DR". We demonstrate that even randomly chosen tokens from the vocabulary as separators can achieve near-state-of-the-art performance. We analyse this phenomenon in detail using three different random generation strategies, establishing that the language space is rich with potential good separators, regardless of the underlying language model size. These observations challenge the common assumption that an effective prompt should be human-readable or task-relevant. Experimental results show that using random separators leads to an average 16% relative improvement across nine text classification tasks on seven language models, compared to human-curated separators, and is on par with automatic prompt searching methods.
Improving Language Plasticity via Pretraining with Active Forgetting
Jul 04, 2023



Pretrained language models (PLMs) are today the primary model for natural language processing. Despite their impressive downstream performance, it can be difficult to apply PLMs to new languages, a barrier to making their capabilities universally accessible. While prior work has shown it possible to address this issue by learning a new embedding layer for the new language, doing so is both data and compute inefficient. We propose to use an active forgetting mechanism during pretraining, as a simple way of creating PLMs that can quickly adapt to new languages. Concretely, by resetting the embedding layer every K updates during pretraining, we encourage the PLM to improve its ability of learning new embeddings within a limited number of updates, similar to a meta-learning effect. Experiments with RoBERTa show that models pretrained with our forgetting mechanism not only demonstrate faster convergence during language adaptation but also outperform standard ones in a low-data regime, particularly for languages that are distant from English.
Can discrete information extraction prompts generalize across language models?
Mar 07, 2023



We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it's possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.
Task-aware Retrieval with Instructions
Nov 16, 2022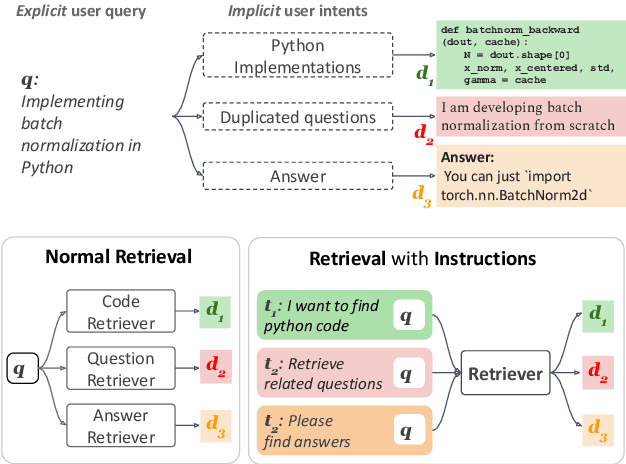

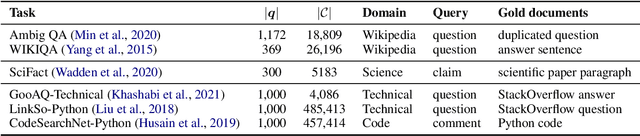
We study the problem of retrieval with instructions, where users of a retrieval system explicitly describe their intent along with their queries, making the system task-aware. We aim to develop a general-purpose task-aware retrieval systems using multi-task instruction tuning that can follow human-written instructions to find the best documents for a given query. To this end, we introduce the first large-scale collection of approximately 40 retrieval datasets with instructions, and present TART, a multi-task retrieval system trained on the diverse retrieval tasks with instructions. TART shows strong capabilities to adapt to a new task via instructions and advances the state of the art on two zero-shot retrieval benchmarks, BEIR and LOTTE, outperforming models up to three times larger. We further introduce a new evaluation setup to better reflect real-world scenarios, pooling diverse documents and tasks. In this setup, TART significantly outperforms competitive baselines, further demonstrating the effectiveness of guiding retrieval with instructions.