 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsyDraw: A Multi-Agent Multimodal System for Mental Health Screening in Left-Behind Children
Dec 19, 2024



Left-behind children (LBCs), numbering over 66 million in China, face severe mental health challenges due to parental migration for work. Early screening and identification of at-risk LBCs is crucial, yet challenging due to the severe shortage of mental health professionals, especially in rural areas. While the House-Tree-Person (HTP) test shows higher child participation rates, its requirement for expert interpretation limits its application in resource-scarce regions. To address this challenge, we propose PsyDraw, a multi-agent system based on Multimodal Large Language Models that assists mental health professionals in analyzing HTP drawings. The system employs specialized agents for feature extraction and psychological interpretation, operating in two stages: comprehensive feature analysis and professional report generation. Evaluation of HTP drawings from 290 primary school students reveals that 71.03% of the analyzes achieved High Consistency with professional evaluations, 26.21% Moderate Consistency and only 2.41% Low Consistency. The system identified 31.03% of cases requiring professional attention, demonstrating its effectiveness as a preliminary screening tool. Currently deployed in pilot schools, \method shows promise in supporting mental health professionals, particularly in resource-limited areas, while maintaining high professional standards in psychological assessment.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


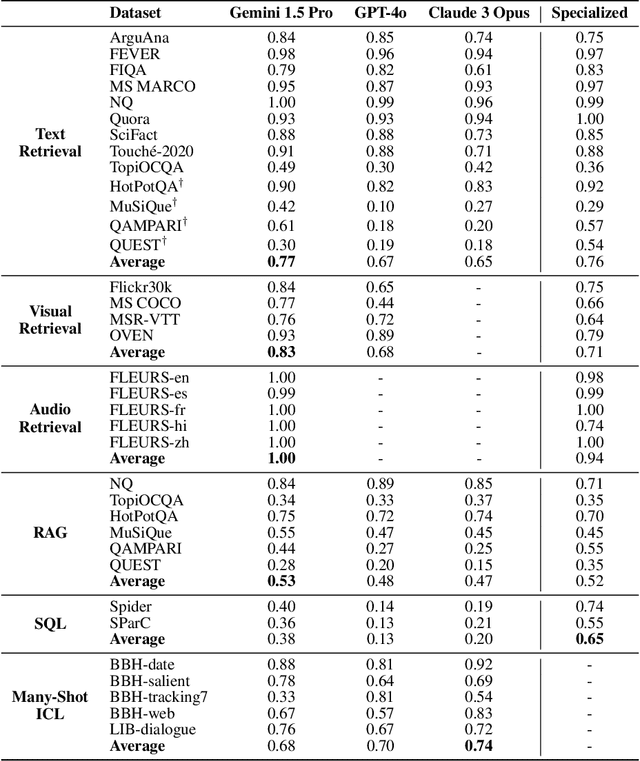
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024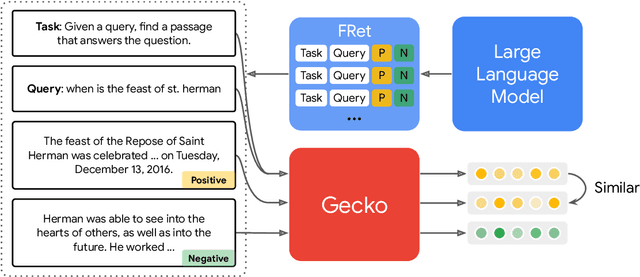
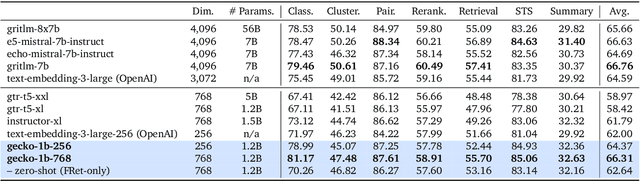

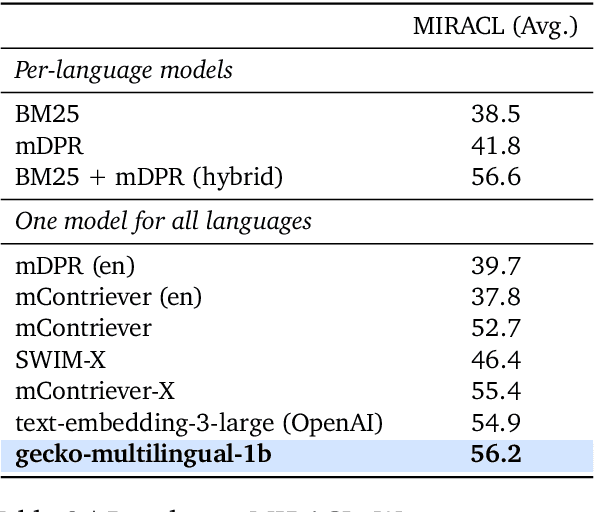
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
Mar 28, 2024



Image retrieval, i.e., finding desired images given a reference image, inherently encompasses rich, multi-faceted search intents that are difficult to capture solely using image-based measures. Recent work leverages text instructions to allow users to more freely express their search intents. However, existing work primarily focuses on image pairs that are visually similar and/or can be characterized by a small set of pre-defined relations. The core thesis of this paper is that text instructions can enable retrieving images with richer relations beyond visual similarity. To show this, we introduce MagicLens, a series of self-supervised image retrieval models that support open-ended instructions. MagicLens is built on a key novel insight: image pairs that naturally occur on the same web pages contain a wide range of implicit relations (e.g., inside view of), and we can bring those implicit relations explicit by synthesizing instructions via large multimodal models (LMMs) and large language models (LLMs). Trained on 36.7M (query image, instruction, target image) triplets with rich semantic relations mined from the web, MagicLens achieves comparable or better results on eight benchmarks of various image retrieval tasks than prior state-of-the-art (SOTA) methods. Remarkably, it outperforms previous SOTA but with a 50X smaller model size on multiple benchmarks. Additional human analyses on a 1.4M-image unseen corpus further demonstrate the diversity of search intents supported by MagicLens.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Instruction-Following Evaluation for Large Language Models
Nov 14, 2023
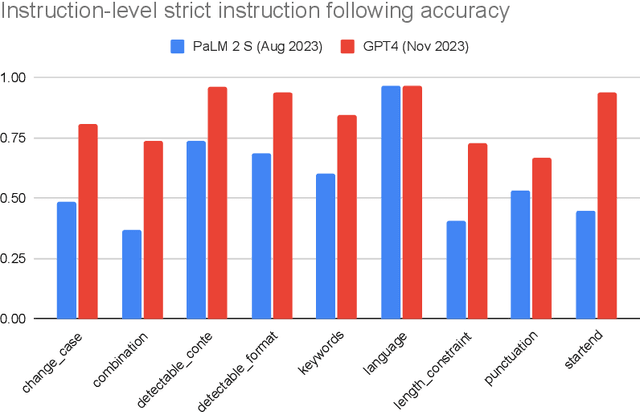

One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 24, 2023

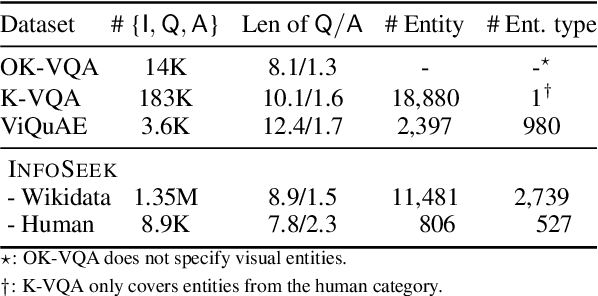

Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023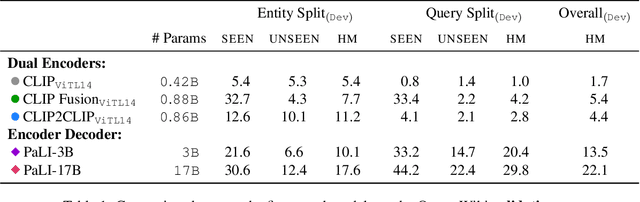
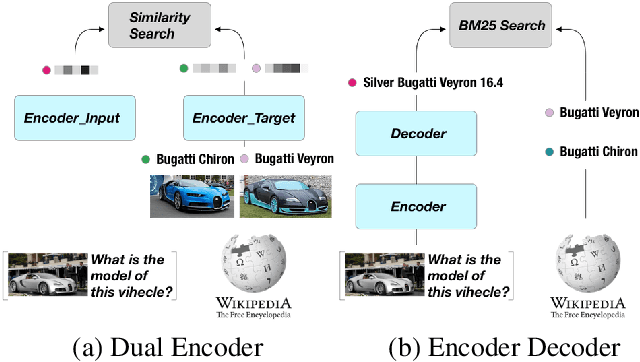
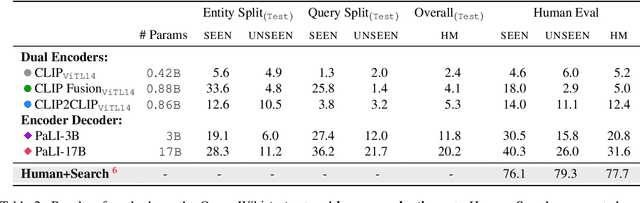

Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
Promptagator: Few-shot Dense Retrieval From 8 Examples
Sep 23, 2022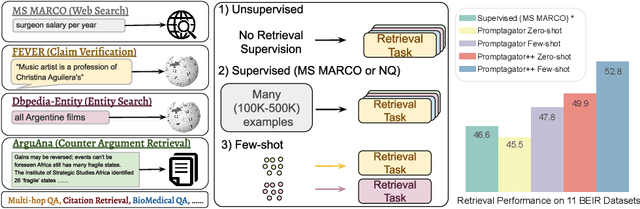
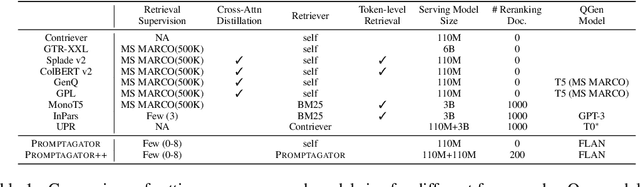
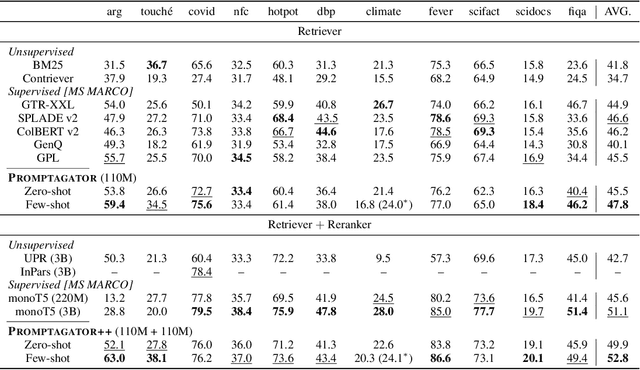
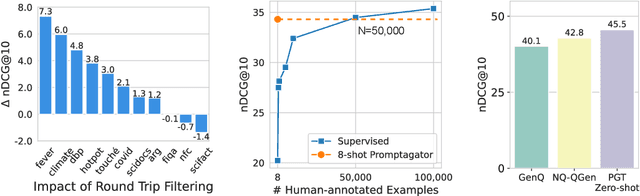
Much recent research on information retrieval has focused on how to transfer from one task (typically with abundant supervised data) to various other tasks where supervision is limited, with the implicit assumption that it is possible to generalize from one task to all the rest. However, this overlooks the fact that there are many diverse and unique retrieval tasks, each targeting different search intents, queries, and search domains. In this paper, we suggest to work on Few-shot Dense Retrieval, a setting where each task comes with a short description and a few examples. To amplify the power of a few examples, we propose Prompt-base Query Generation for Retriever (Promptagator), which leverages large language models (LLM) as a few-shot query generator, and creates task-specific retrievers based on the generated data. Powered by LLM's generalization ability, Promptagator makes it possible to create task-specific end-to-end retrievers solely based on a few examples {without} using Natural Questions or MS MARCO to train %question generators or dual encoders. Surprisingly, LLM prompting with no more than 8 examples allows dual encoders to outperform heavily engineered models trained on MS MARCO like ColBERT v2 by more than 1.2 nDCG on average on 11 retrieval sets. Further training standard-size re-rankers using the same generated data yields another 5.0 point nDCG improvement. Our studies determine that query generation can be far more effective than previously observed, especially when a small amount of task-specific knowledge is given.
ASQA: Factoid Questions Meet Long-Form Answers
Apr 12, 2022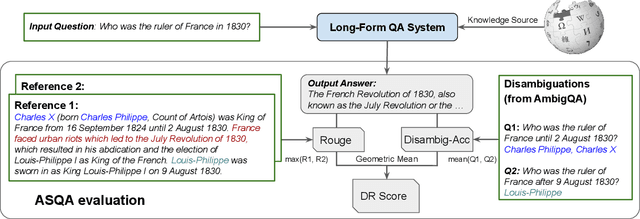

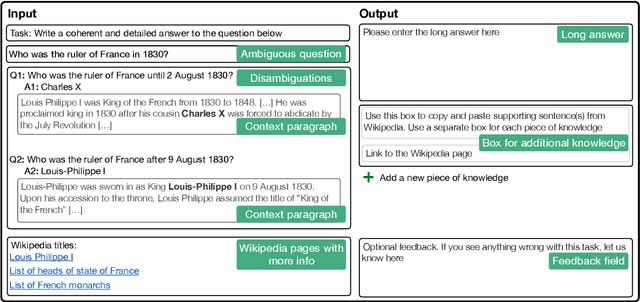
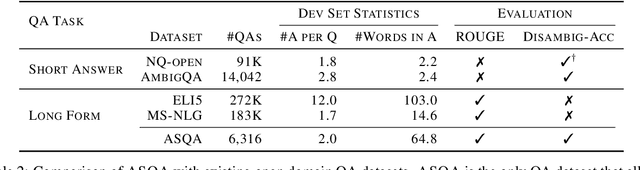
An abundance of datasets and availability of reliable evaluation metrics have resulted in strong progress in factoid question answering (QA). This progress, however, does not easily transfer to the task of long-form QA, where the goal is to answer questions that require in-depth explanations. The hurdles include (i) a lack of high-quality data, and (ii) the absence of a well-defined notion of the answer's quality. In this work, we address these problems by (i) releasing a novel dataset and a task that we call ASQA (Answer Summaries for Questions which are Ambiguous); and (ii) proposing a reliable metric for measuring performance on ASQA. Our task focuses on factoid questions that are ambiguous, that is, have different correct answers depending on interpretation. Answers to ambiguous questions should synthesize factual information from multiple sources into a long-form summary that resolves the ambiguity. In contrast to existing long-form QA tasks (such as ELI5), ASQA admits a clear notion of correctness: a user faced with a good summary should be able to answer different interpretations of the original ambiguous question. We use this notion of correctness to define an automated metric of performance for ASQA. Our analysis demonstrates an agreement between this metric and human judgments, and reveals a considerable gap between human performance and strong baselines.