 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLESS: Large Language Model Enhanced Semi-Supervised Learning for Speech Foundational Models
Jun 05, 2025We introduce LESS (Large Language Model Enhanced Semi-supervised Learning), a versatile framework that leverages Large Language Models (LLMs) to correct pseudo labels generated from in-the-wild data. Within the LESS framework, pseudo-labeled text from Automatic Speech Recognition (ASR) or Automatic Speech Translation (AST) of the unsupervised data is refined by an LLM, and augmented by a data filtering strategy to optimize LLM knowledge transfer efficiency. Experiments on both Mandarin ASR and Spanish-to-English AST tasks show that LESS achieves a notable absolute WER reduction of 3.77% on the Wenet Speech test set, as well as BLEU scores of 34.0 and 64.7 on Callhome and Fisher test sets respectively. These results validate the adaptability of LESS across different languages, tasks, and domains. Ablation studies conducted with various LLMs and prompt configurations provide novel insights into leveraging LLM-derived knowledge for speech processing applications.
CTLformer: A Hybrid Denoising Model Combining Convolutional Layers and Self-Attention for Enhanced CT Image Reconstruction
May 18, 2025Low-dose CT (LDCT) images are often accompanied by significant noise, which negatively impacts image quality and subsequent diagnostic accuracy. To address the challenges of multi-scale feature fusion and diverse noise distribution patterns in LDCT denoising, this paper introduces an innovative model, CTLformer, which combines convolutional structures with transformer architecture. Two key innovations are proposed: a multi-scale attention mechanism and a dynamic attention control mechanism. The multi-scale attention mechanism, implemented through the Token2Token mechanism and self-attention interaction modules, effectively captures both fine details and global structures at different scales, enhancing relevant features and suppressing noise. The dynamic attention control mechanism adapts the attention distribution based on the noise characteristics of the input image, focusing on high-noise regions while preserving details in low-noise areas, thereby enhancing robustness and improving denoising performance. Furthermore, CTLformer integrates convolutional layers for efficient feature extraction and uses overlapping inference to mitigate boundary artifacts, further strengthening its denoising capability. Experimental results on the 2016 National Institutes of Health AAPM Mayo Clinic LDCT Challenge dataset demonstrate that CTLformer significantly outperforms existing methods in both denoising performance and model efficiency, greatly improving the quality of LDCT images. The proposed CTLformer not only provides an efficient solution for LDCT denoising but also shows broad potential in medical image analysis, especially for clinical applications dealing with complex noise patterns.
NTC-KWS: Noise-aware CTC for Robust Keyword Spotting
Dec 17, 2024In recent years, there has been a growing interest in designing small-footprint yet effective Connectionist Temporal Classification based keyword spotting (CTC-KWS) systems. They are typically deployed on low-resource computing platforms, where limitations on model size and computational capacity create bottlenecks under complicated acoustic scenarios. Such constraints often result in overfitting and confusion between keywords and background noise, leading to high false alarms. To address these issues, we propose a noise-aware CTC-based KWS (NTC-KWS) framework designed to enhance model robustness in noisy environments, particularly under extremely low signal-to-noise ratios. Our approach introduces two additional noise-modeling wildcard arcs into the training and decoding processes based on weighted finite state transducer (WFST) graphs: self-loop arcs to address noise insertion errors and bypass arcs to handle masking and interference caused by excessive noise. Experiments on clean and noisy Hey Snips show that NTC-KWS outperforms state-of-the-art (SOTA) end-to-end systems and CTC-KWS baselines across various acoustic conditions, with particularly strong performance in low SNR scenarios.
Romanization Encoding For Multilingual ASR
Jul 05, 2024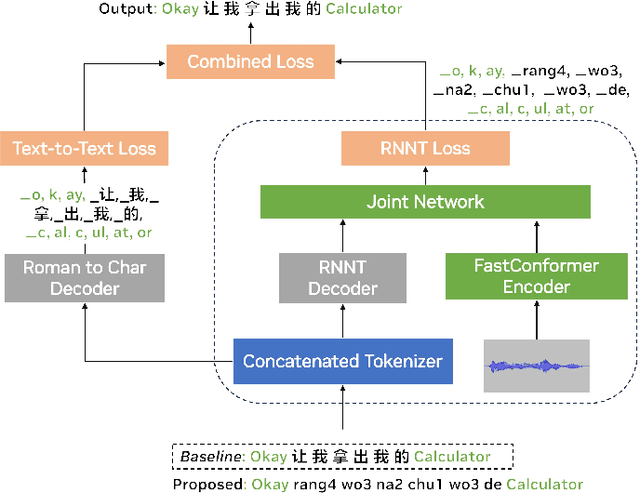


We introduce romanization encoding for script-heavy languages to optimize multilingual and code-switching Automatic Speech Recognition (ASR) systems. By adopting romanization encoding alongside a balanced concatenated tokenizer within a FastConformer-RNNT framework equipped with a Roman2Char module, we significantly reduce vocabulary and output dimensions, enabling larger training batches and reduced memory consumption. Our method decouples acoustic modeling and language modeling, enhancing the flexibility and adaptability of the system. In our study, applying this method to Mandarin-English ASR resulted in a remarkable 63.51% vocabulary reduction and notable performance gains of 13.72% and 15.03% on SEAME code-switching benchmarks. Ablation studies on Mandarin-Korean and Mandarin-Japanese highlight our method's strong capability to address the complexities of other script-heavy languages, paving the way for more versatile and effective multilingual ASR systems.
Semi-supervised Learning for Code-Switching ASR with Large Language Model Filter
Jul 05, 2024
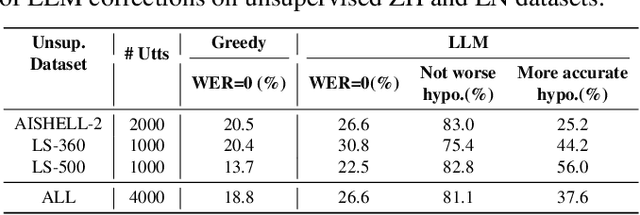


Code-switching (CS) phenomenon occurs when words or phrases from different languages are alternated in a single sentence. Due to data scarcity, building an effective CS Automatic Speech Recognition (ASR) system remains challenging. In this paper, we propose to enhance CS-ASR systems by utilizing rich unsupervised monolingual speech data within a semi-supervised learning framework, particularly when access to CS data is limited. To achieve this, we establish a general paradigm for applying noisy student training (NST) to the CS-ASR task. Specifically, we introduce the LLM-Filter, which leverages well-designed prompt templates to activate the correction capability of large language models (LLMs) for monolingual data selection and pseudo-labels refinement during NST. Our experiments on the supervised ASRU-CS and unsupervised AISHELL-2 and LibriSpeech datasets show that our method not only achieves significant improvements over supervised and semi-supervised learning baselines for the CS task, but also attains better performance compared with the fully-supervised oracle upper-bound on the CS English part. Additionally, we further investigate the influence of accent on AESRC dataset and demonstrate that our method can get achieve additional benefits when the monolingual data contains relevant linguistic characteristic.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024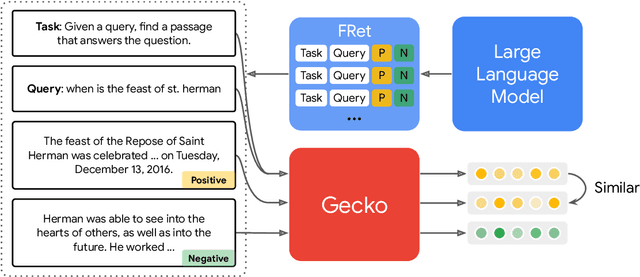
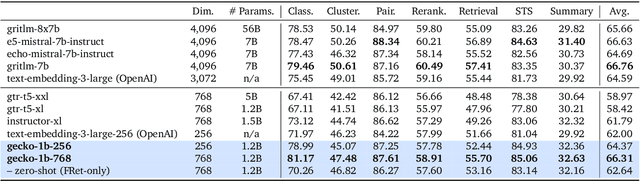

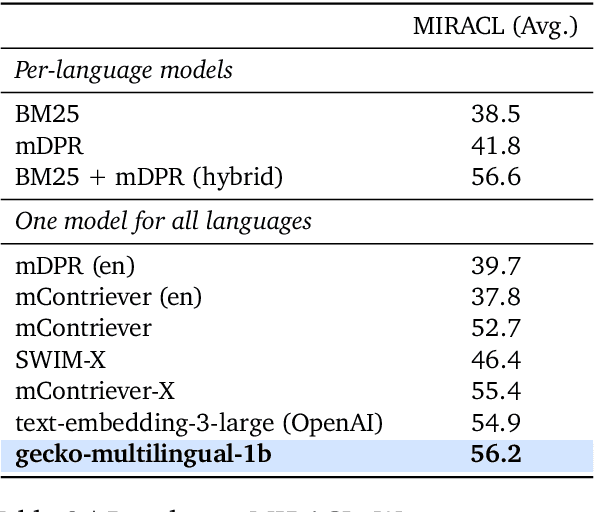
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Wespeaker baselines for VoxSRC2023
Jun 28, 2023



This report showcases the results achieved using the wespeaker toolkit for the VoxSRC2023 Challenge. Our aim is to provide participants, especially those with limited experience, with clear and straightforward guidelines to develop their initial systems. Via well-structured recipes and strong results, we hope to offer an accessible and good enough start point for all interested individuals. In this report, we describe the results achieved on the VoxSRC2023 dev set using the pretrained models, you can check the CodaLab evaluation server for the results on the evaluation set.
Improving Noisy Student Training on Non-target Domain Data for Automatic Speech Recognition
Nov 09, 2022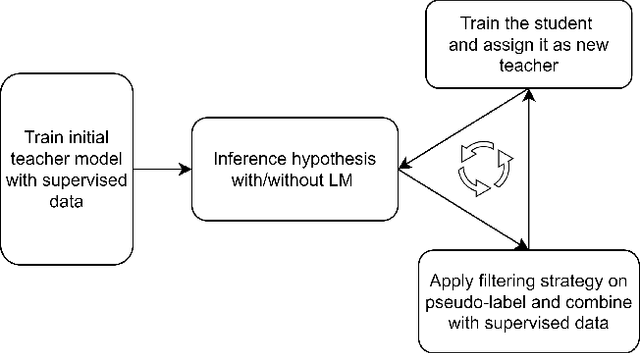


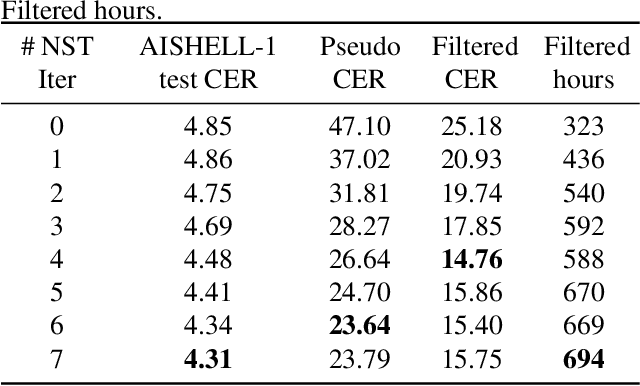
Noisy Student Training (NST) has recently demonstrated extremely strong performance in Automatic Speech Recognition (ASR). In this paper, we propose a data selection strategy named LM Filter to improve the performances of NST on non-target domain data in ASR tasks. Hypothesis with and without Language Model are generated and CER differences between them are utilized as a filter threshold. Results reveal that significant improvements of 10.4% compared with no data filtering baselines. We can achieve 3.31% CER in AISHELL-1 test set, which is best result from our knowledge without any other supervised data. We also perform evaluations on supervised 1000 hour AISHELL-2 dataset and competitive results of 4.72% CER can be achieved.