 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024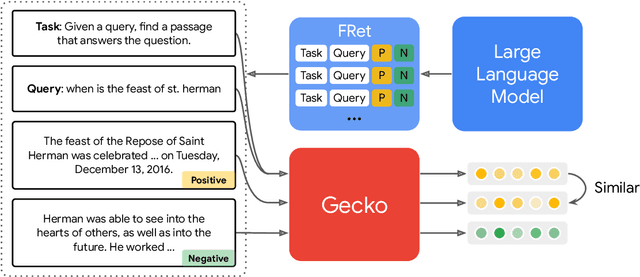
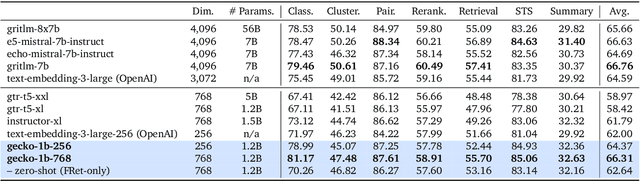

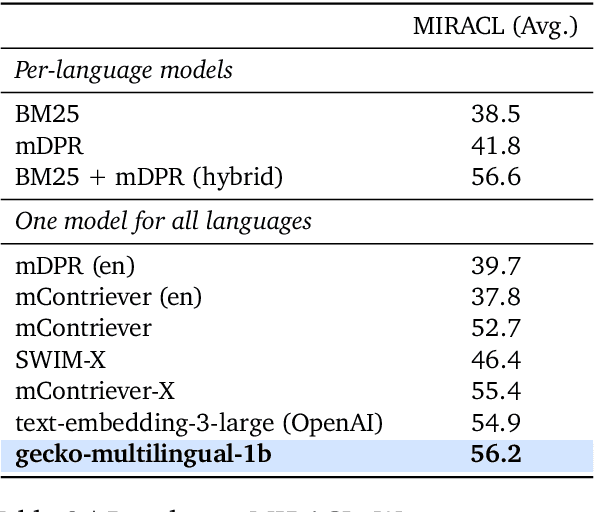
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Content Conditional Debiasing for Fair Text Embedding
Feb 23, 2024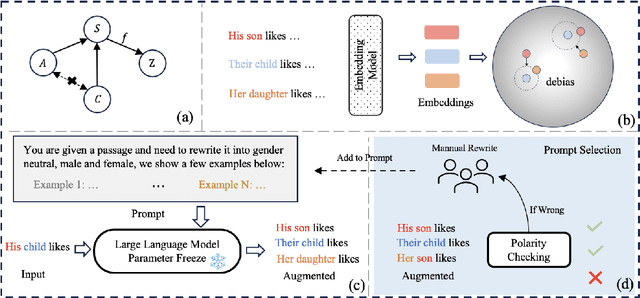

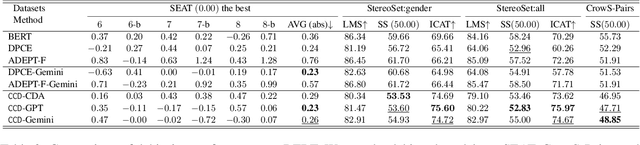
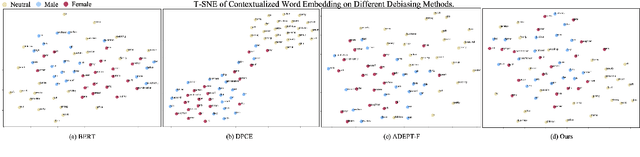
Mitigating biases in machine learning models has gained increasing attention in Natural Language Processing (NLP). Yet, only a few studies focus on fair text embeddings, which are crucial yet challenging for real-world applications. In this paper, we propose a novel method for learning fair text embeddings. We achieve fairness while maintaining utility trade-off by ensuring conditional independence between sensitive attributes and text embeddings conditioned on the content. Specifically, we enforce that embeddings of texts with different sensitive attributes but identical content maintain the same distance toward the embedding of their corresponding neutral text. Furthermore, we address the issue of lacking proper training data by using Large Language Models (LLMs) to augment texts into different sensitive groups. Our extensive evaluations demonstrate that our approach effectively improves fairness while preserving the utility of embeddings, representing a pioneering effort in achieving conditional independence for fair text embeddings.
An Investigation of how Label Smoothing Affects Generalization
Oct 23, 2020



It has been hypothesized that label smoothing can reduce overfitting and improve generalization, and current empirical evidence seems to corroborate these effects. However, there is a lack of mathematical understanding of when and why such empirical improvements occur. In this paper, as a step towards understanding why label smoothing is effective, we propose a theoretical framework to show how label smoothing provides in controlling the generalization loss. In particular, we show that this benefit can be precisely formulated and identified in the label noise setting, where the training is partially mislabeled. Our theory also predicts the existence of an optimal label smoothing point, a single value for the label smoothing hyperparameter that minimizes generalization loss. Extensive experiments are done to confirm the predictions of our theory. We believe that our findings will help both theoreticians and practitioners understand label smoothing, and better apply them to real-world datasets.
Learning Not to Learn in the Presence of Noisy Labels
Feb 16, 2020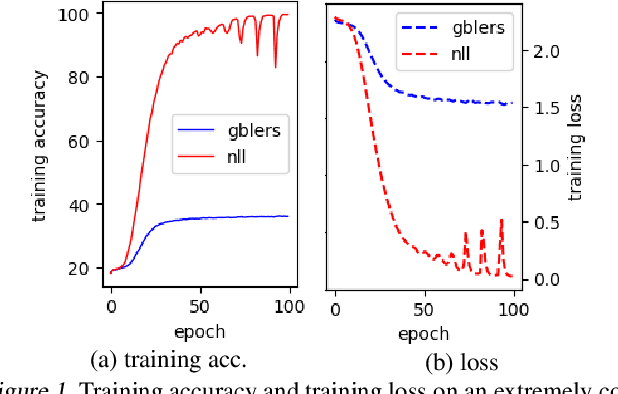

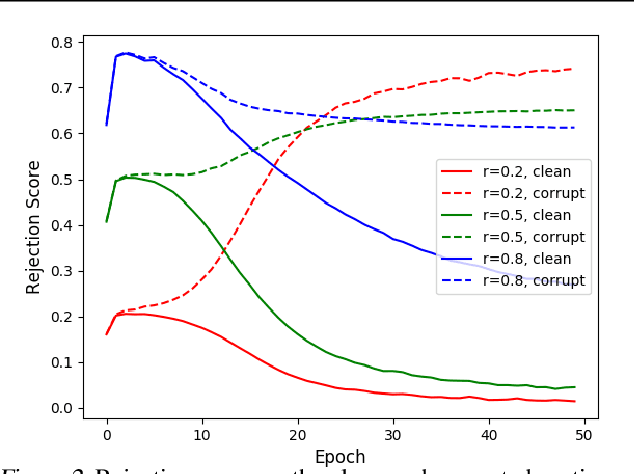
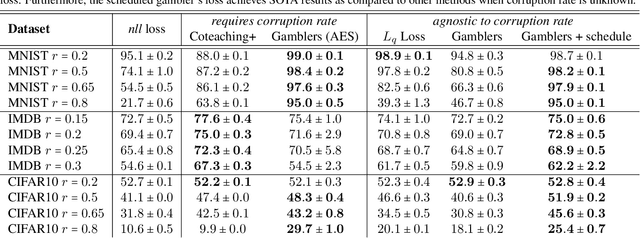
Learning in the presence of label noise is a challenging yet important task: it is crucial to design models that are robust in the presence of mislabeled datasets. In this paper, we discover that a new class of loss functions called the gambler's loss provides strong robustness to label noise across various levels of corruption. We show that training with this loss function encourages the model to "abstain" from learning on the data points with noisy labels, resulting in a simple and effective method to improve robustness and generalization. In addition, we propose two practical extensions of the method: 1) an analytical early stopping criterion to approximately stop training before the memorization of noisy labels, as well as 2) a heuristic for setting hyperparameters which do not require knowledge of the noise corruption rate. We demonstrate the effectiveness of our method by achieving strong results across three image and text classification tasks as compared to existing baselines.