 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Theoretical Limitations of Embedding-Based Retrieval
Aug 28, 2025Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings to work for any query and any notion of relevance that could be given. While prior works have pointed out theoretical limitations of vector embeddings, there is a common assumption that these difficulties are exclusively due to unrealistic queries, and those that are not can be overcome with better training data and larger models. In this work, we demonstrate that we may encounter these theoretical limitations in realistic settings with extremely simple queries. We connect known results in learning theory, showing that the number of top-k subsets of documents capable of being returned as the result of some query is limited by the dimension of the embedding. We empirically show that this holds true even if we restrict to k=2, and directly optimize on the test set with free parameterized embeddings. We then create a realistic dataset called LIMIT that stress tests models based on these theoretical results, and observe that even state-of-the-art models fail on this dataset despite the simple nature of the task. Our work shows the limits of embedding models under the existing single vector paradigm and calls for future research to develop methods that can resolve this fundamental limitation.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


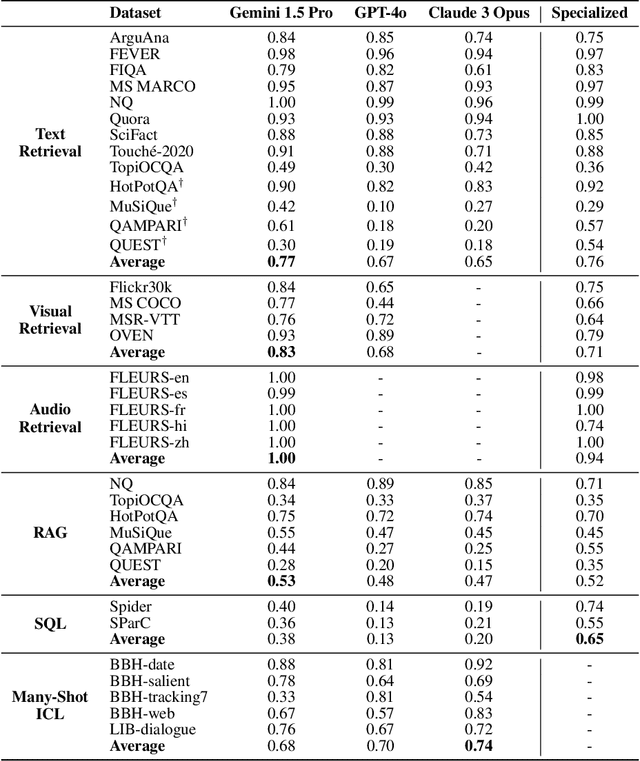
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Mar 29, 2024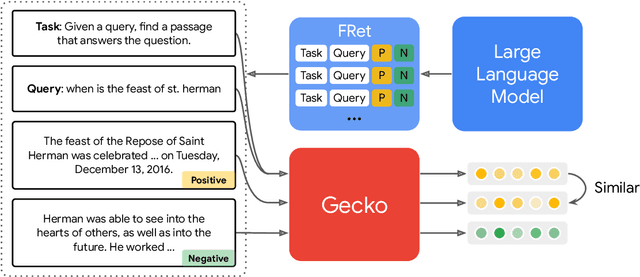
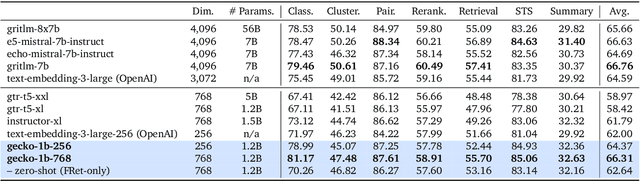

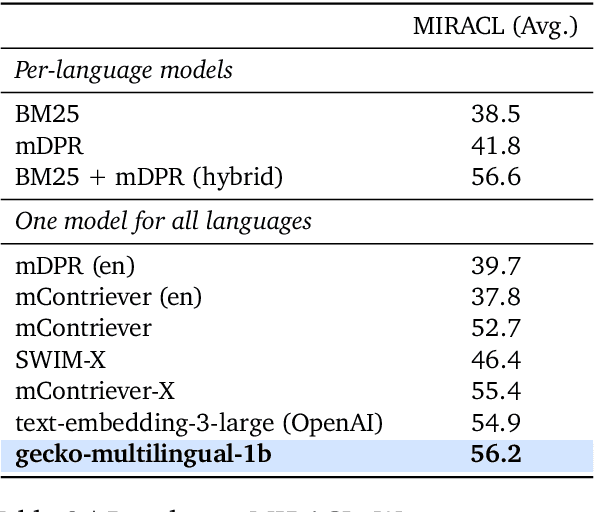
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
Rethinking the Role of Token Retrieval in Multi-Vector Retrieval
Apr 04, 2023Multi-vector retrieval models such as ColBERT [Khattab and Zaharia, 2020] allow token-level interactions between queries and documents, and hence achieve state of the art on many information retrieval benchmarks. However, their non-linear scoring function cannot be scaled to millions of documents, necessitating a three-stage process for inference: retrieving initial candidates via token retrieval, accessing all token vectors, and scoring the initial candidate documents. The non-linear scoring function is applied over all token vectors of each candidate document, making the inference process complicated and slow. In this paper, we aim to simplify the multi-vector retrieval by rethinking the role of token retrieval. We present XTR, ConteXtualized Token Retriever, which introduces a simple, yet novel, objective function that encourages the model to retrieve the most important document tokens first. The improvement to token retrieval allows XTR to rank candidates only using the retrieved tokens rather than all tokens in the document, and enables a newly designed scoring stage that is two-to-three orders of magnitude cheaper than that of ColBERT. On the popular BEIR benchmark, XTR advances the state-of-the-art by 2.8 nDCG@10 without any distillation. Detailed analysis confirms our decision to revisit the token retrieval stage, as XTR demonstrates much better recall of the token retrieval stage compared to ColBERT.
TextMI: Textualize Multimodal Information for Integrating Non-verbal Cues in Pre-trained Language Models
Mar 29, 2023Pre-trained large language models have recently achieved ground-breaking performance in a wide variety of language understanding tasks. However, the same model can not be applied to multimodal behavior understanding tasks (e.g., video sentiment/humor detection) unless non-verbal features (e.g., acoustic and visual) can be integrated with language. Jointly modeling multiple modalities significantly increases the model complexity, and makes the training process data-hungry. While an enormous amount of text data is available via the web, collecting large-scale multimodal behavioral video datasets is extremely expensive, both in terms of time and money. In this paper, we investigate whether large language models alone can successfully incorporate non-verbal information when they are presented in textual form. We present a way to convert the acoustic and visual information into corresponding textual descriptions and concatenate them with the spoken text. We feed this augmented input to a pre-trained BERT model and fine-tune it on three downstream multimodal tasks: sentiment, humor, and sarcasm detection. Our approach, TextMI, significantly reduces model complexity, adds interpretability to the model's decision, and can be applied for a diverse set of tasks while achieving superior (multimodal sarcasm detection) or near SOTA (multimodal sentiment analysis and multimodal humor detection) performance. We propose TextMI as a general, competitive baseline for multimodal behavioral analysis tasks, particularly in a low-resource setting.
How Does Beam Search improve Span-Level Confidence Estimation in Generative Sequence Labeling?
Dec 21, 2022



Text-to-text generation models have increasingly become the go-to solution for a wide variety of sequence labeling tasks (e.g., entity extraction and dialog slot filling). While most research has focused on the labeling accuracy, a key aspect -- of vital practical importance -- has slipped through the cracks: understanding model confidence. More specifically, we lack a principled understanding of how to reliably gauge the confidence of a model in its predictions for each labeled span. This paper aims to provide some empirical insights on estimating model confidence for generative sequence labeling. Most notably, we find that simply using the decoder's output probabilities is not the best in realizing well-calibrated confidence estimates. As verified over six public datasets of different tasks, we show that our proposed approach -- which leverages statistics from top-$k$ predictions by a beam search -- significantly reduces calibration errors of the predictions of a generative sequence labeling model.
Multi-Vector Retrieval as Sparse Alignment
Nov 02, 2022



Multi-vector retrieval models improve over single-vector dual encoders on many information retrieval tasks. In this paper, we cast the multi-vector retrieval problem as sparse alignment between query and document tokens. We propose AligneR, a novel multi-vector retrieval model that learns sparsified pairwise alignments between query and document tokens (e.g. `dog' vs. `puppy') and per-token unary saliences reflecting their relative importance for retrieval. We show that controlling the sparsity of pairwise token alignments often brings significant performance gains. While most factoid questions focusing on a specific part of a document require a smaller number of alignments, others requiring a broader understanding of a document favor a larger number of alignments. Unary saliences, on the other hand, decide whether a token ever needs to be aligned with others for retrieval (e.g. `kind' from `kind of currency is used in new zealand}'). With sparsified unary saliences, we are able to prune a large number of query and document token vectors and improve the efficiency of multi-vector retrieval. We learn the sparse unary saliences with entropy-regularized linear programming, which outperforms other methods to achieve sparsity. In a zero-shot setting, AligneR scores 51.1 points nDCG@10, achieving a new retriever-only state-of-the-art on 13 tasks in the BEIR benchmark. In addition, adapting pairwise alignments with a few examples (<= 8) further improves the performance up to 15.7 points nDCG@10 for argument retrieval tasks. The unary saliences of AligneR helps us to keep only 20% of the document token representations with minimal performance loss. We further show that our model often produces interpretable alignments and significantly improves its performance when initialized from larger language models.
Transforming Sequence Tagging Into A Seq2Seq Task
Mar 16, 2022

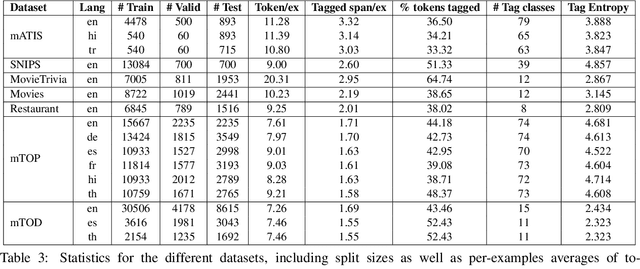
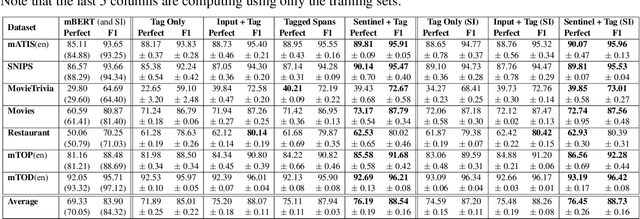
Pretrained, large, generative language models (LMs) have had great success in a wide range of sequence tagging and structured prediction tasks. Casting a sequence tagging task as a Seq2Seq one requires deciding the formats of the input and output sequences. However, we lack a principled understanding of the trade-offs associated with these formats (such as the effect on model accuracy, sequence length, multilingual generalization, hallucination). In this paper, we rigorously study different formats one could use for casting input text sentences and their output labels into the input and target (i.e., output) of a Seq2Seq model. Along the way, we introduce a new format, which we show to not only be simpler but also more effective. Additionally the new format demonstrates significant gains in the multilingual settings -- both zero-shot transfer learning and joint training. Lastly, we find that the new format is more robust and almost completely devoid of hallucination -- an issue we find common in existing formats. With well over a 1000 experiments studying 14 different formats, over 7 diverse public benchmarks -- including 3 multilingual datasets spanning 7 languages -- we believe our findings provide a strong empirical basis in understanding how we should tackle sequence tagging tasks.
Feature-based Decipherment for Large Vocabulary Machine Translation
Aug 10, 2015



Orthographic similarities across languages provide a strong signal for probabilistic decipherment, especially for closely related language pairs. The existing decipherment models, however, are not well-suited for exploiting these orthographic similarities. We propose a log-linear model with latent variables that incorporates orthographic similarity features. Maximum likelihood training is computationally expensive for the proposed log-linear model. To address this challenge, we perform approximate inference via MCMC sampling and contrastive divergence. Our results show that the proposed log-linear model with contrastive divergence scales to large vocabularies and outperforms the existing generative decipherment models by exploiting the orthographic features.