 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't lie to your friends: Learning what you know from collaborative self-play
Mar 18, 2025To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


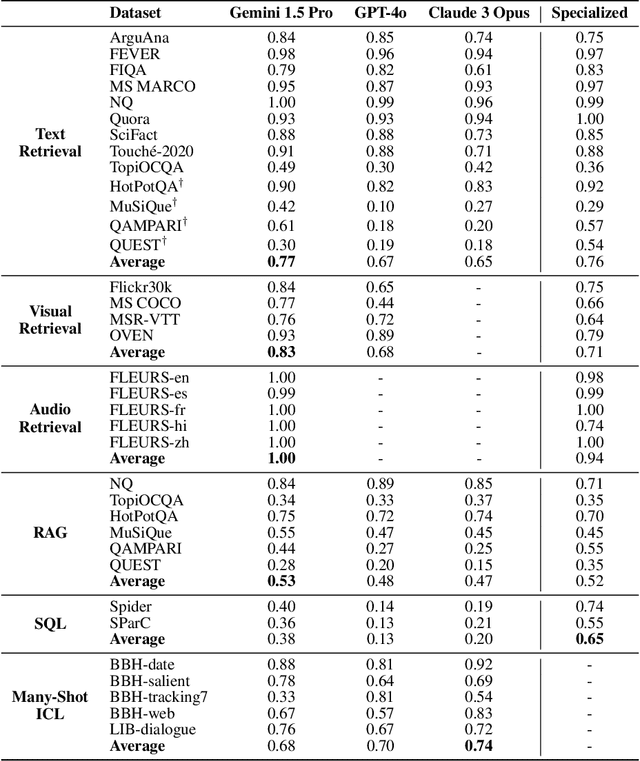
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
To Adapt or to Annotate: Challenges and Interventions for Domain Adaptation in Open-Domain Question Answering
Dec 20, 2022Recent advances in open-domain question answering (ODQA) have demonstrated impressive accuracy on standard Wikipedia style benchmarks. However, it is less clear how robust these models are and how well they perform when applied to real-world applications in drastically different domains. While there has been some work investigating how well ODQA models perform when tested for out-of-domain (OOD) generalization, these studies have been conducted only under conservative shifts in data distribution and typically focus on a single component (ie. retrieval) rather than an end-to-end system. In response, we propose a more realistic and challenging domain shift evaluation setting and, through extensive experiments, study end-to-end model performance. We find that not only do models fail to generalize, but high retrieval scores often still yield poor answer prediction accuracy. We then categorize different types of shifts and propose techniques that, when presented with a new dataset, predict if intervention methods are likely to be successful. Finally, using insights from this analysis, we propose and evaluate several intervention methods which improve end-to-end answer F1 score by up to 24 points.
Successive Prompting for Decomposing Complex Questions
Dec 08, 2022Answering complex questions that require making latent decisions is a challenging task, especially when limited supervision is available. Recent works leverage the capabilities of large language models (LMs) to perform complex question answering in a few-shot setting by demonstrating how to output intermediate rationalizations while solving the complex question in a single pass. We introduce ``Successive Prompting'', where we iteratively break down a complex task into a simple task, solve it, and then repeat the process until we get the final solution. Successive prompting decouples the supervision for decomposing complex questions from the supervision for answering simple questions, allowing us to (1) have multiple opportunities to query in-context examples at each reasoning step (2) learn question decomposition separately from question answering, including using synthetic data, and (3) use bespoke (fine-tuned) components for reasoning steps where a large LM does not perform well. The intermediate supervision is typically manually written, which can be expensive to collect. We introduce a way to generate a synthetic dataset which can be used to bootstrap a model's ability to decompose and answer intermediate questions. Our best model (with successive prompting) achieves an improvement of ~5% absolute F1 on a few-shot version of the DROP dataset when compared with a state-of-the-art model with the same supervision.
Tricks for Training Sparse Translation Models
Oct 15, 2021
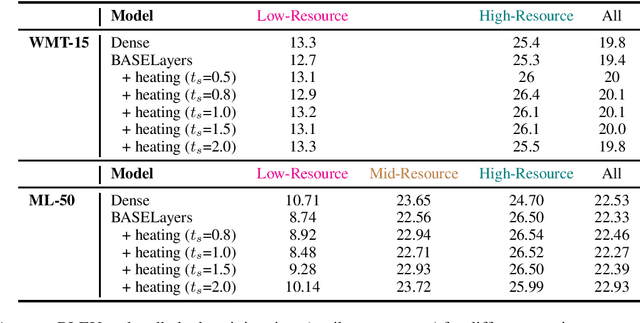
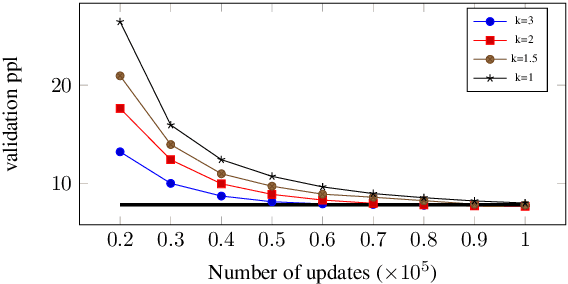
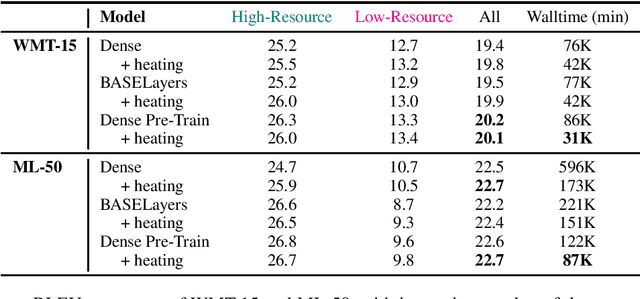
Multi-task learning with an unbalanced data distribution skews model learning towards high resource tasks, especially when model capacity is fixed and fully shared across all tasks. Sparse scaling architectures, such as BASELayers, provide flexible mechanisms for different tasks to have a variable number of parameters, which can be useful to counterbalance skewed data distributions. We find that that sparse architectures for multilingual machine translation can perform poorly out of the box, and propose two straightforward techniques to mitigate this - a temperature heating mechanism and dense pre-training. Overall, these methods improve performance on two multilingual translation benchmarks compared to standard BASELayers and Dense scaling baselines, and in combination, more than 2x model convergence speed.
Generative Context Pair Selection for Multi-hop Question Answering
Apr 18, 2021



Compositional reasoning tasks like multi-hop question answering, require making latent decisions to get the final answer, given a question. However, crowdsourced datasets often capture only a slice of the underlying task distribution, which can induce unanticipated biases in models performing compositional reasoning. Furthermore, discriminatively trained models exploit such biases to get a better held-out performance, without learning the right way to reason, as they do not necessitate paying attention to the question representation (conditioning variable) in its entirety, to estimate the answer likelihood. In this work, we propose a generative context selection model for multi-hop question answering that reasons about how the given question could have been generated given a context pair. While being comparable to the state-of-the-art answering performance, our proposed generative passage selection model has a better performance (4.9% higher than baseline) on adversarial held-out set which tests robustness of model's multi-hop reasoning capabilities.
Learning with Instance Bundles for Reading Comprehension
Apr 18, 2021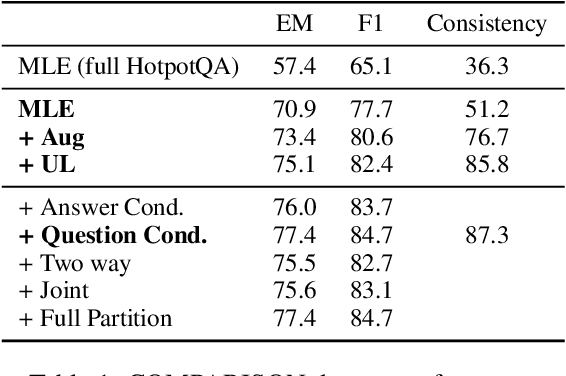


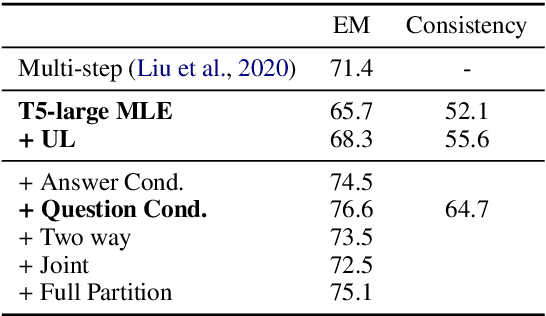
When training most modern reading comprehension models, all the questions associated with a context are treated as being independent from each other. However, closely related questions and their corresponding answers are not independent, and leveraging these relationships could provide a strong supervision signal to a model. Drawing on ideas from contrastive estimation, we introduce several new supervision techniques that compare question-answer scores across multiple related instances. Specifically, we normalize these scores across various neighborhoods of closely contrasting questions and/or answers, adding another cross entropy loss term that is used in addition to traditional maximum likelihood estimation. Our techniques require bundles of related question-answer pairs, which we can either mine from within existing data or create using various automated heuristics. We empirically demonstrate the effectiveness of training with instance bundles on two datasets -- HotpotQA and ROPES -- showing up to 11% absolute gains in accuracy.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
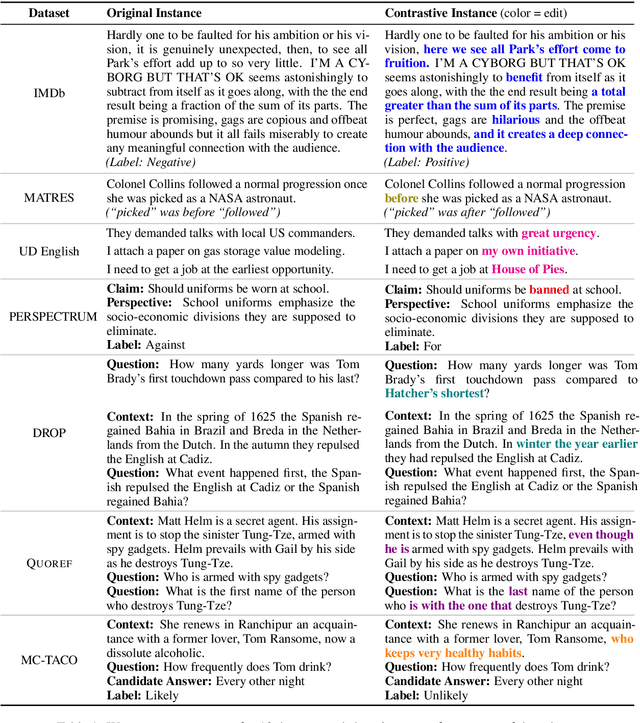
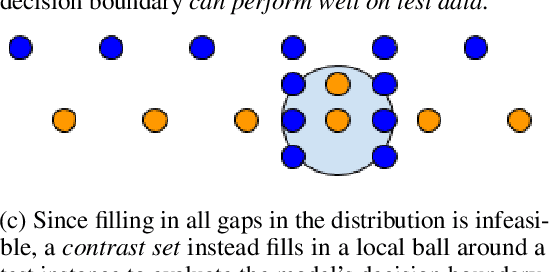
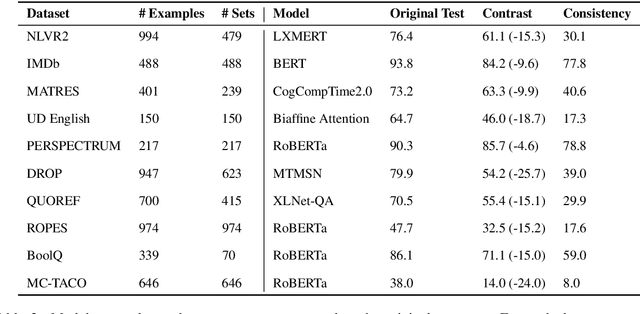
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
ORB: An Open Reading Benchmark for Comprehensive Evaluation of Machine Reading Comprehension
Dec 29, 2019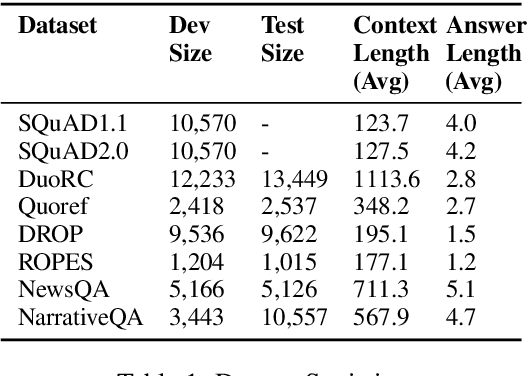
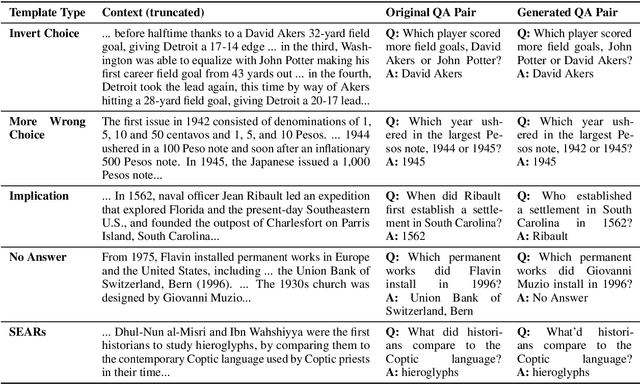
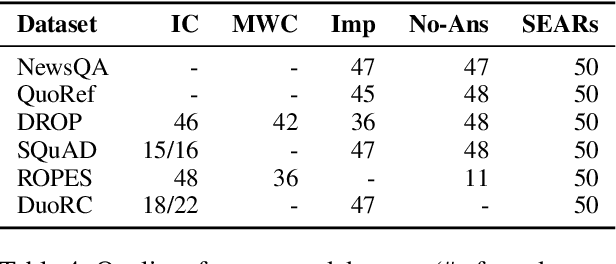
Reading comprehension is one of the crucial tasks for furthering research in natural language understanding. A lot of diverse reading comprehension datasets have recently been introduced to study various phenomena in natural language, ranging from simple paraphrase matching and entity typing to entity tracking and understanding the implications of the context. Given the availability of many such datasets, comprehensive and reliable evaluation is tedious and time-consuming for researchers working on this problem. We present an evaluation server, ORB, that reports performance on seven diverse reading comprehension datasets, encouraging and facilitating testing a single model's capability in understanding a wide variety of reading phenomena. The evaluation server places no restrictions on how models are trained, so it is a suitable test bed for exploring training paradigms and representation learning for general reading facility. As more suitable datasets are released, they will be added to the evaluation server. We also collect and include synthetic augmentations for these datasets, testing how well models can handle out-of-domain questions.
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Apr 16, 2019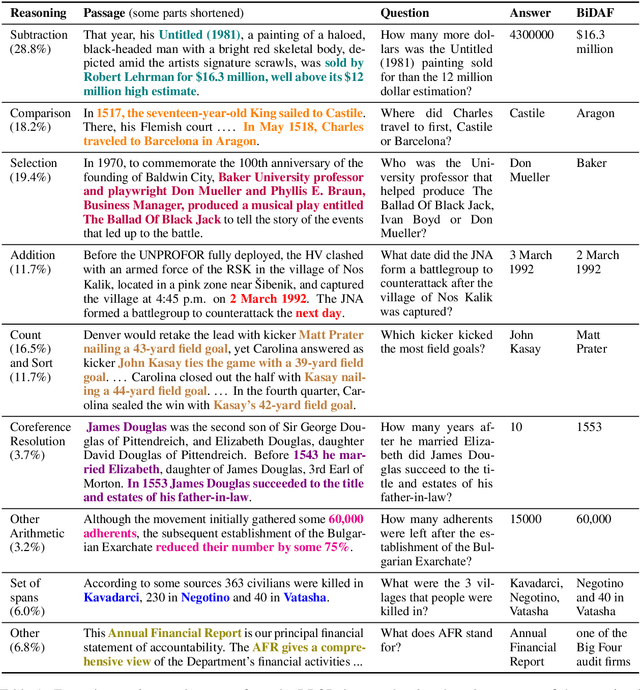
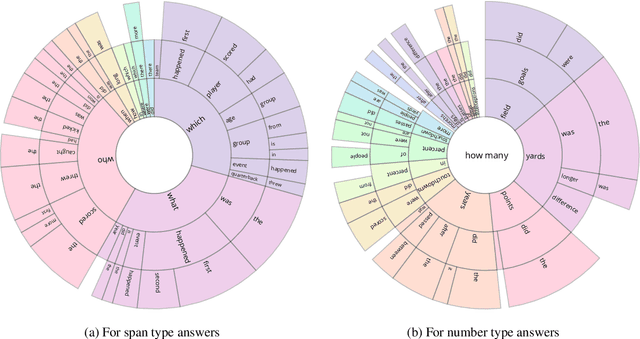
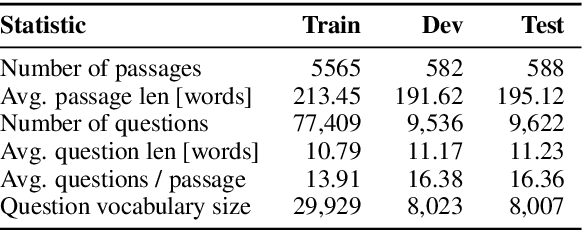
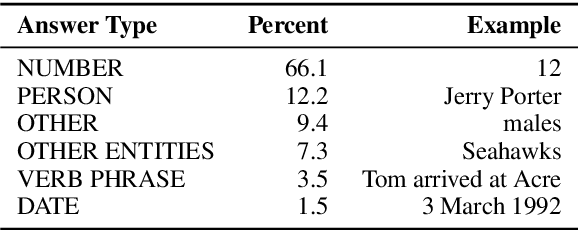
Reading comprehension has recently seen rapid progress, with systems matching humans on the most popular datasets for the task. However, a large body of work has highlighted the brittleness of these systems, showing that there is much work left to be done. We introduce a new English reading comprehension benchmark, DROP, which requires Discrete Reasoning Over the content of Paragraphs. In this crowdsourced, adversarially-created, 96k-question benchmark, a system must resolve references in a question, perhaps to multiple input positions, and perform discrete operations over them (such as addition, counting, or sorting). These operations require a much more comprehensive understanding of the content of paragraphs than what was necessary for prior datasets. We apply state-of-the-art methods from both the reading comprehension and semantic parsing literature on this dataset and show that the best systems only achieve 32.7% F1 on our generalized accuracy metric, while expert human performance is 96.0%. We additionally present a new model that combines reading comprehension methods with simple numerical reasoning to achieve 47.0% F1.