 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging In-Context Learning for Language Model Agents
Jun 16, 2025In-context learning (ICL) with dynamically selected demonstrations combines the flexibility of prompting large language models (LLMs) with the ability to leverage training data to improve performance. While ICL has been highly successful for prediction and generation tasks, leveraging it for agentic tasks that require sequential decision making is challenging -- one must think not only about how to annotate long trajectories at scale and how to select demonstrations, but also what constitutes demonstrations, and when and where to show them. To address this, we first propose an algorithm that leverages an LLM with retries along with demonstrations to automatically and efficiently annotate agentic tasks with solution trajectories. We then show that set-selection of trajectories of similar tasks as demonstrations significantly improves performance, reliability, robustness, and efficiency of LLM agents. However, trajectory demonstrations have a large inference cost overhead. We show that this can be mitigated by using small trajectory snippets at every step instead of an additional trajectory. We find that demonstrations obtained from larger models (in the annotation phase) also improve smaller models, and that ICL agents can even rival costlier trained agents. Thus, our results reveal that ICL, with careful use, can be very powerful for agentic tasks as well.
LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions
May 27, 2025Pretrained Large Language Models (LLMs) achieve strong performance across a wide range of tasks, yet exhibit substantial variability in the various layers' training quality with respect to specific downstream applications, limiting their downstream performance.It is therefore critical to estimate layer-wise training quality in a manner that accounts for both model architecture and training data. However, existing approaches predominantly rely on model-centric heuristics (such as spectral statistics, outlier detection, or uniform allocation) while overlooking the influence of data. To address these limitations, we propose LayerIF, a data-driven framework that leverages Influence Functions to quantify the training quality of individual layers in a principled and task-sensitive manner. By isolating each layer's gradients and measuring the sensitivity of the validation loss to training examples by computing layer-wise influences, we derive data-driven estimates of layer importance. Notably, our method produces task-specific layer importance estimates for the same LLM, revealing how layers specialize for different test-time evaluation tasks. We demonstrate the utility of our scores by leveraging them for two downstream applications: (a) expert allocation in LoRA-MoE architectures and (b) layer-wise sparsity distribution for LLM pruning. Experiments across multiple LLM architectures demonstrate that our model-agnostic, influence-guided allocation leads to consistent gains in task performance.
Unraveling Indirect In-Context Learning Using Influence Functions
Jan 01, 2025



This work introduces a novel paradigm for generalized In-Context Learning (ICL), termed Indirect In-Context Learning. In Indirect ICL, we explore demonstration selection strategies tailored for two distinct real-world scenarios: Mixture of Tasks and Noisy Demonstrations. We systematically evaluate the effectiveness of Influence Functions (IFs) as a selection tool for these settings, highlighting the potential for IFs to better capture the informativeness of examples within the demonstration pool. For the Mixture of Tasks setting, demonstrations are drawn from 28 diverse tasks, including MMLU, BigBench, StrategyQA, and CommonsenseQA. We demonstrate that combining BertScore-Recall (BSR) with an IF surrogate model can significantly improve performance, leading to average absolute accuracy gains of 0.37\% and 1.45\% for 3-shot and 5-shot setups when compared to traditional ICL metrics. In the Noisy Demonstrations setting, we examine scenarios where demonstrations might be mislabeled. Our experiments show that reweighting traditional ICL selectors (BSR and Cosine Similarity) with IF-based selectors boosts accuracy by an average of 2.90\% for Cosine Similarity and 2.94\% for BSR on noisy GLUE benchmarks. In sum, we propose a robust framework for demonstration selection that generalizes beyond traditional ICL, offering valuable insights into the role of IFs for Indirect ICL.
Leveraging Code to Improve In-context Learning for Semantic Parsing
Nov 16, 2023

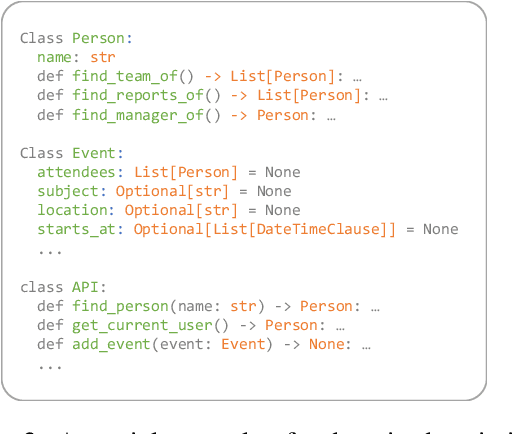

In-context learning (ICL) is an appealing approach for semantic parsing due to its few-shot nature and improved generalization. However, learning to parse to rare domain-specific languages (DSLs) from just a few demonstrations is challenging, limiting the performance of even the most capable LLMs. In this work, we improve the effectiveness of ICL for semantic parsing by (1) using general-purpose programming languages such as Python instead of DSLs, and (2) augmenting prompts with a structured domain description that includes, e.g., the available classes and functions. We show that both these changes significantly improve accuracy across three popular datasets. Combined, they lead to dramatic improvements (e.g. 7.9% to 66.5% on SMCalFlow compositional split), nearly closing the performance gap between easier i.i.d.\ and harder compositional splits when used with a strong model, and reducing the need for a large number of demonstrations. We find that the resemblance of the target parse language to general-purpose code is a more important factor than the language's popularity in pre-training corpora. Our findings provide an improved methodology for building semantic parsers in the modern context of ICL with LLMs.
GistScore: Learning Better Representations for In-Context Example Selection with Gist Bottlenecks
Nov 16, 2023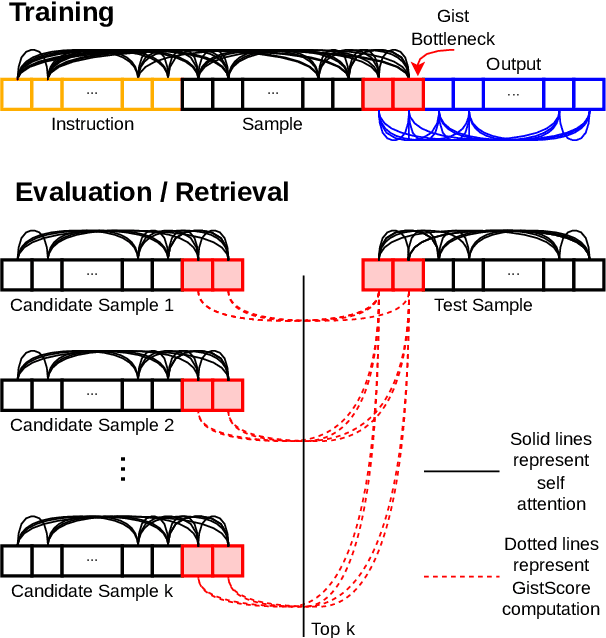
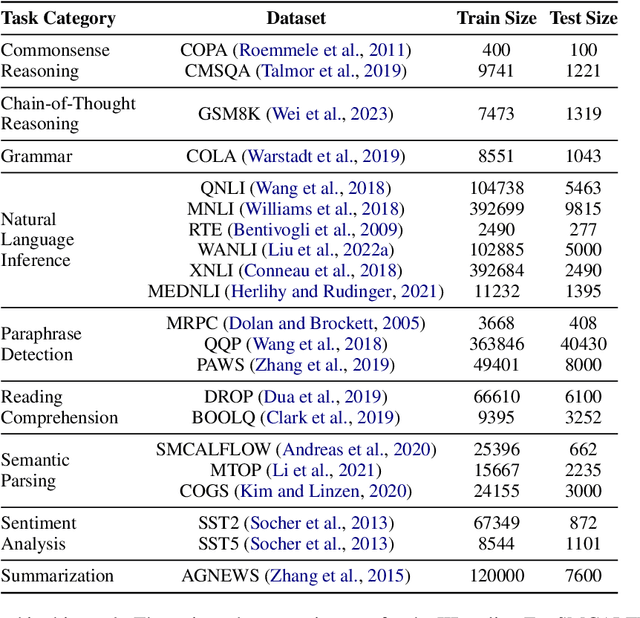
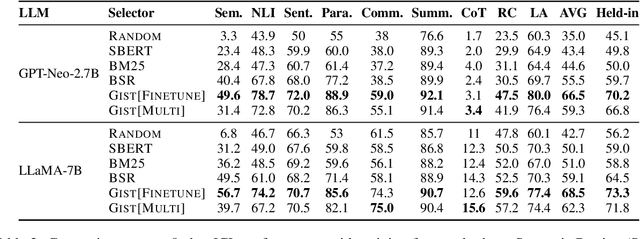
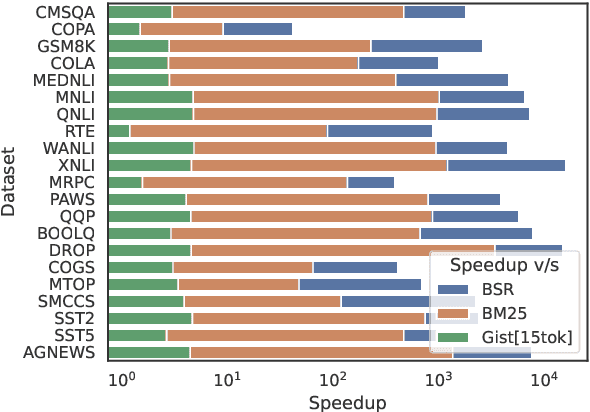
Large language models (LLMs) have the ability to perform in-context learning (ICL) of new tasks by conditioning on prompts comprising a few task examples. This work studies the problem of selecting the best examples given a candidate pool to improve ICL performance on given a test input. Existing approaches either require training with feedback from a much larger LLM or are computationally expensive. We propose a novel metric, GistScore, based on Example Gisting, a novel approach for training example retrievers for ICL using an attention bottleneck via Gisting, a recent technique for compressing task instructions. To tradeoff performance with ease of use, we experiment with both fine-tuning gist models on each dataset and multi-task training a single model on a large collection of datasets. On 21 diverse datasets spanning 9 tasks, we show that our fine-tuned models get state-of-the-art ICL performance with 20% absolute average gain over off-the-shelf retrievers and 7% over the best prior methods. Our multi-task model generalizes well out-of-the-box to new task categories, datasets, and prompt templates with retrieval speeds that are consistently thousands of times faster than the best prior training-free method.
Cross-Lingual Knowledge Distillation for Answer Sentence Selection in Low-Resource Languages
May 25, 2023



While impressive performance has been achieved on the task of Answer Sentence Selection (AS2) for English, the same does not hold for languages that lack large labeled datasets. In this work, we propose Cross-Lingual Knowledge Distillation (CLKD) from a strong English AS2 teacher as a method to train AS2 models for low-resource languages in the tasks without the need of labeled data for the target language. To evaluate our method, we introduce 1) Xtr-WikiQA, a translation-based WikiQA dataset for 9 additional languages, and 2) TyDi-AS2, a multilingual AS2 dataset with over 70K questions spanning 8 typologically diverse languages. We conduct extensive experiments on Xtr-WikiQA and TyDi-AS2 with multiple teachers, diverse monolingual and multilingual pretrained language models (PLMs) as students, and both monolingual and multilingual training. The results demonstrate that CLKD either outperforms or rivals even supervised fine-tuning with the same amount of labeled data and a combination of machine translation and the teacher model. Our method can potentially enable stronger AS2 models for low-resource languages, while TyDi-AS2 can serve as the largest multilingual AS2 dataset for further studies in the research community.
Coverage-based Example Selection for In-Context Learning
May 24, 2023In-context learning (ICL), the ability of large language models to perform novel tasks by conditioning on a prompt with a few task examples, requires demonstrations that are informative about the test instance. The standard approach of independently selecting the most similar examples selects redundant demonstrations while overlooking important information. This work proposes a framework for assessing the informativeness of demonstrations based on their coverage of salient aspects (e.g., reasoning patterns) of the test input. Using this framework, we show that contextual token embeddings effectively capture these salient aspects, and their recall measured using BERTScore-Recall (BSR) yields a reliable measure of informativeness. Further, we extend recall metrics like BSR to propose their set versions to find maximally informative sets of demonstrations. On 6 complex compositional generation tasks and 7 diverse LLMs, we show that Set-BSR outperforms the standard similarity-based approach by up to 16% on average and, despite being learning-free, often surpasses methods that leverage task or LLM-specific training.
Successive Prompting for Decomposing Complex Questions
Dec 08, 2022Answering complex questions that require making latent decisions is a challenging task, especially when limited supervision is available. Recent works leverage the capabilities of large language models (LMs) to perform complex question answering in a few-shot setting by demonstrating how to output intermediate rationalizations while solving the complex question in a single pass. We introduce ``Successive Prompting'', where we iteratively break down a complex task into a simple task, solve it, and then repeat the process until we get the final solution. Successive prompting decouples the supervision for decomposing complex questions from the supervision for answering simple questions, allowing us to (1) have multiple opportunities to query in-context examples at each reasoning step (2) learn question decomposition separately from question answering, including using synthetic data, and (3) use bespoke (fine-tuned) components for reasoning steps where a large LM does not perform well. The intermediate supervision is typically manually written, which can be expensive to collect. We introduce a way to generate a synthetic dataset which can be used to bootstrap a model's ability to decompose and answer intermediate questions. Our best model (with successive prompting) achieves an improvement of ~5% absolute F1 on a few-shot version of the DROP dataset when compared with a state-of-the-art model with the same supervision.
Structurally Diverse Sampling Reduces Spurious Correlations in Semantic Parsing Datasets
Mar 16, 2022
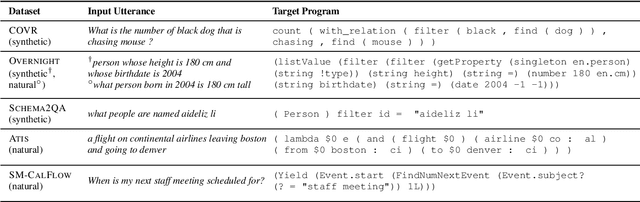
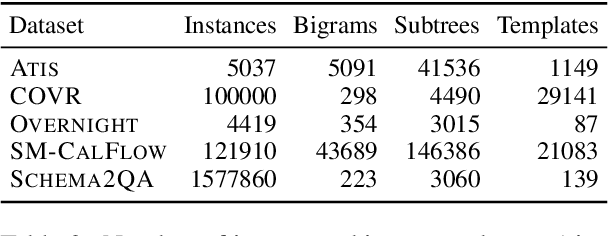

A rapidly growing body of research has demonstrated the inability of NLP models to generalize compositionally and has tried to alleviate it through specialized architectures, training schemes, and data augmentation, among other approaches. In this work, we study a different relatively under-explored approach: sampling diverse train sets that encourage compositional generalization. We propose a novel algorithm for sampling a structurally diverse set of instances from a labeled instance pool with structured outputs. Evaluating on 5 semantic parsing datasets of varying complexity, we show that our algorithm performs competitively with or better than prior algorithms in not only compositional template splits but also traditional IID splits of all but the least structurally diverse datasets. In general, we find that diverse train sets lead to better generalization than random training sets of the same size in 9 out of 10 dataset-split pairs, with over 10% absolute improvement in 5, providing further evidence to their sample efficiency. Moreover, we show that structural diversity also makes for more comprehensive test sets that require diverse training to succeed on. Finally, we use information theory to show that reduction in spurious correlations between substructures may be one reason why diverse training sets improve generalization.
Unobserved Local Structures Make Compositional Generalization Hard
Jan 15, 2022



While recent work has convincingly showed that sequence-to-sequence models struggle to generalize to new compositions (termed compositional generalization), little is known on what makes compositional generalization hard on a particular test instance. In this work, we investigate what are the factors that make generalization to certain test instances challenging. We first substantiate that indeed some examples are more difficult than others by showing that different models consistently fail or succeed on the same test instances. Then, we propose a criterion for the difficulty of an example: a test instance is hard if it contains a local structure that was not observed at training time. We formulate a simple decision rule based on this criterion and empirically show it predicts instance-level generalization well across 5 different semantic parsing datasets, substantially better than alternative decision rules. Last, we show local structures can be leveraged for creating difficult adversarial compositional splits and also to improve compositional generalization under limited training budgets by strategically selecting examples for the training set.