 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage-based Example Selection for In-Context Learning
May 24, 2023In-context learning (ICL), the ability of large language models to perform novel tasks by conditioning on a prompt with a few task examples, requires demonstrations that are informative about the test instance. The standard approach of independently selecting the most similar examples selects redundant demonstrations while overlooking important information. This work proposes a framework for assessing the informativeness of demonstrations based on their coverage of salient aspects (e.g., reasoning patterns) of the test input. Using this framework, we show that contextual token embeddings effectively capture these salient aspects, and their recall measured using BERTScore-Recall (BSR) yields a reliable measure of informativeness. Further, we extend recall metrics like BSR to propose their set versions to find maximally informative sets of demonstrations. On 6 complex compositional generation tasks and 7 diverse LLMs, we show that Set-BSR outperforms the standard similarity-based approach by up to 16% on average and, despite being learning-free, often surpasses methods that leverage task or LLM-specific training.
Successive Prompting for Decomposing Complex Questions
Dec 08, 2022Answering complex questions that require making latent decisions is a challenging task, especially when limited supervision is available. Recent works leverage the capabilities of large language models (LMs) to perform complex question answering in a few-shot setting by demonstrating how to output intermediate rationalizations while solving the complex question in a single pass. We introduce ``Successive Prompting'', where we iteratively break down a complex task into a simple task, solve it, and then repeat the process until we get the final solution. Successive prompting decouples the supervision for decomposing complex questions from the supervision for answering simple questions, allowing us to (1) have multiple opportunities to query in-context examples at each reasoning step (2) learn question decomposition separately from question answering, including using synthetic data, and (3) use bespoke (fine-tuned) components for reasoning steps where a large LM does not perform well. The intermediate supervision is typically manually written, which can be expensive to collect. We introduce a way to generate a synthetic dataset which can be used to bootstrap a model's ability to decompose and answer intermediate questions. Our best model (with successive prompting) achieves an improvement of ~5% absolute F1 on a few-shot version of the DROP dataset when compared with a state-of-the-art model with the same supervision.
CONDAQA: A Contrastive Reading Comprehension Dataset for Reasoning about Negation
Nov 01, 2022



The full power of human language-based communication cannot be realized without negation. All human languages have some form of negation. Despite this, negation remains a challenging phenomenon for current natural language understanding systems. To facilitate the future development of models that can process negation effectively, we present CONDAQA, the first English reading comprehension dataset which requires reasoning about the implications of negated statements in paragraphs. We collect paragraphs with diverse negation cues, then have crowdworkers ask questions about the implications of the negated statement in the passage. We also have workers make three kinds of edits to the passage -- paraphrasing the negated statement, changing the scope of the negation, and reversing the negation -- resulting in clusters of question-answer pairs that are difficult for models to answer with spurious shortcuts. CONDAQA features 14,182 question-answer pairs with over 200 unique negation cues and is challenging for current state-of-the-art models. The best performing model on CONDAQA (UnifiedQA-v2-3b) achieves only 42% on our consistency metric, well below human performance which is 81%. We release our dataset, along with fully-finetuned, few-shot, and zero-shot evaluations, to facilitate the development of future NLP methods that work on negated language.
When to Use Multi-Task Learning vs Intermediate Fine-Tuning for Pre-Trained Encoder Transfer Learning
May 17, 2022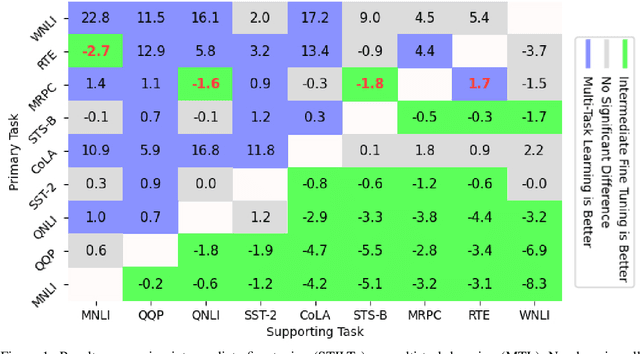
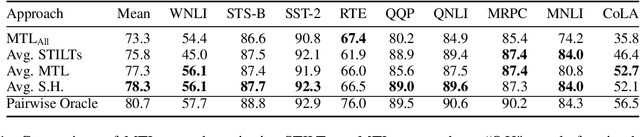
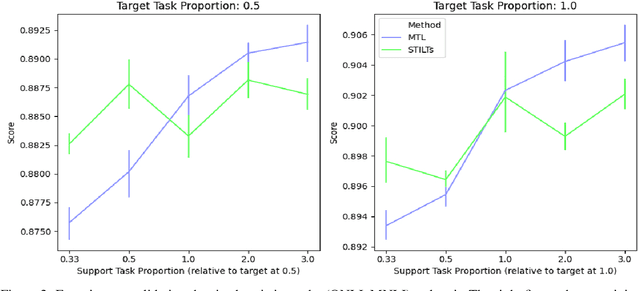
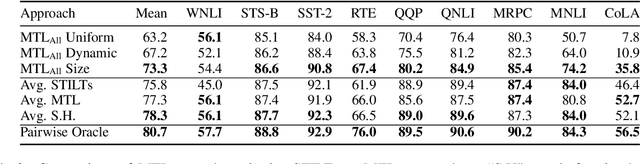
Transfer learning (TL) in natural language processing (NLP) has seen a surge of interest in recent years, as pre-trained models have shown an impressive ability to transfer to novel tasks. Three main strategies have emerged for making use of multiple supervised datasets during fine-tuning: training on an intermediate task before training on the target task (STILTs), using multi-task learning (MTL) to train jointly on a supplementary task and the target task (pairwise MTL), or simply using MTL to train jointly on all available datasets (MTL-ALL). In this work, we compare all three TL methods in a comprehensive analysis on the GLUE dataset suite. We find that there is a simple heuristic for when to use one of these techniques over the other: pairwise MTL is better than STILTs when the target task has fewer instances than the supporting task and vice versa. We show that this holds true in more than 92% of applicable cases on the GLUE dataset and validate this hypothesis with experiments varying dataset size. The simplicity and effectiveness of this heuristic is surprising and warrants additional exploration by the TL community. Furthermore, we find that MTL-ALL is worse than the pairwise methods in almost every case. We hope this study will aid others as they choose between TL methods for NLP tasks.
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
Apr 12, 2022
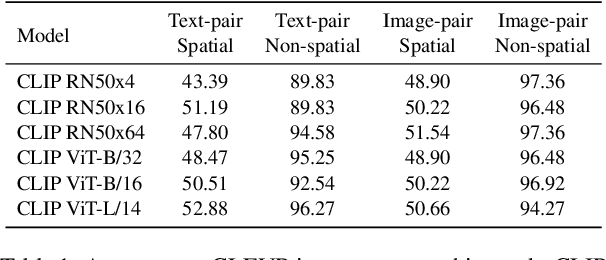

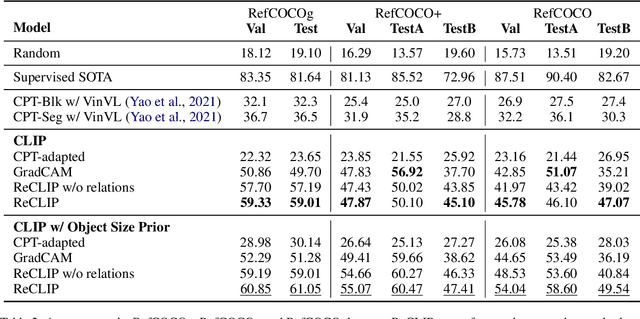
Training a referring expression comprehension (ReC) model for a new visual domain requires collecting referring expressions, and potentially corresponding bounding boxes, for images in the domain. While large-scale pre-trained models are useful for image classification across domains, it remains unclear if they can be applied in a zero-shot manner to more complex tasks like ReC. We present ReCLIP, a simple but strong zero-shot baseline that repurposes CLIP, a state-of-the-art large-scale model, for ReC. Motivated by the close connection between ReC and CLIP's contrastive pre-training objective, the first component of ReCLIP is a region-scoring method that isolates object proposals via cropping and blurring, and passes them to CLIP. However, through controlled experiments on a synthetic dataset, we find that CLIP is largely incapable of performing spatial reasoning off-the-shelf. Thus, the second component of ReCLIP is a spatial relation resolver that handles several types of spatial relations. We reduce the gap between zero-shot baselines from prior work and supervised models by as much as 29% on RefCOCOg, and on RefGTA (video game imagery), ReCLIP's relative improvement over supervised ReC models trained on real images is 8%.
Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
Mar 24, 2022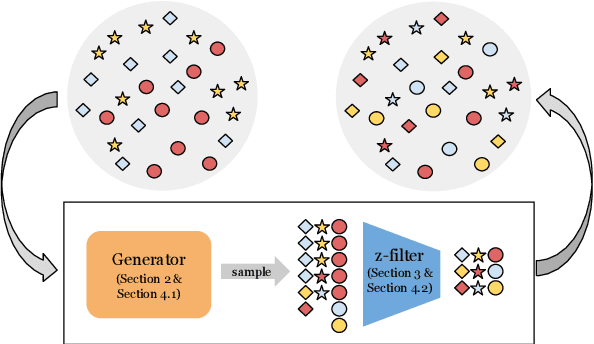
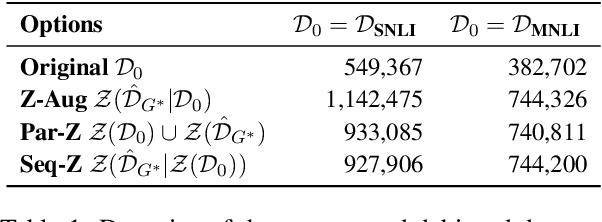

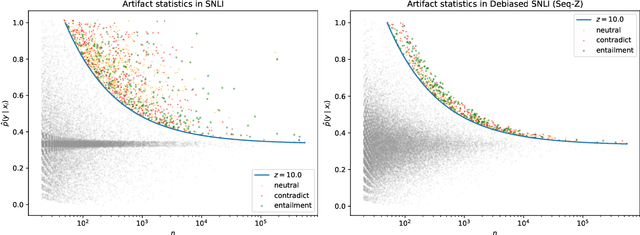
Natural language processing models often exploit spurious correlations between task-independent features and labels in datasets to perform well only within the distributions they are trained on, while not generalising to different task distributions. We propose to tackle this problem by generating a debiased version of a dataset, which can then be used to train a debiased, off-the-shelf model, by simply replacing its training data. Our approach consists of 1) a method for training data generators to generate high-quality, label-consistent data samples; and 2) a filtering mechanism for removing data points that contribute to spurious correlations, measured in terms of z-statistics. We generate debiased versions of the SNLI and MNLI datasets, and we evaluate on a large suite of debiased, out-of-distribution, and adversarial test sets. Results show that models trained on our debiased datasets generalise better than those trained on the original datasets in all settings. On the majority of the datasets, our method outperforms or performs comparably to previous state-of-the-art debiasing strategies, and when combined with an orthogonal technique, product-of-experts, it improves further and outperforms previous best results of SNLI-hard and MNLI-hard.
Structurally Diverse Sampling Reduces Spurious Correlations in Semantic Parsing Datasets
Mar 16, 2022
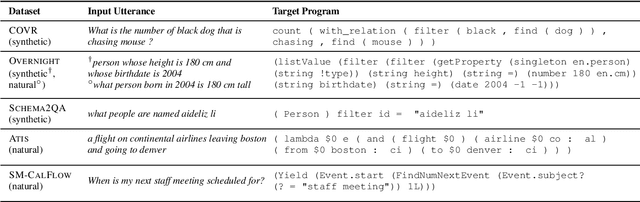
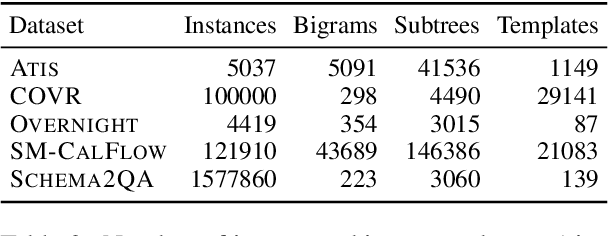

A rapidly growing body of research has demonstrated the inability of NLP models to generalize compositionally and has tried to alleviate it through specialized architectures, training schemes, and data augmentation, among other approaches. In this work, we study a different relatively under-explored approach: sampling diverse train sets that encourage compositional generalization. We propose a novel algorithm for sampling a structurally diverse set of instances from a labeled instance pool with structured outputs. Evaluating on 5 semantic parsing datasets of varying complexity, we show that our algorithm performs competitively with or better than prior algorithms in not only compositional template splits but also traditional IID splits of all but the least structurally diverse datasets. In general, we find that diverse train sets lead to better generalization than random training sets of the same size in 9 out of 10 dataset-split pairs, with over 10% absolute improvement in 5, providing further evidence to their sample efficiency. Moreover, we show that structural diversity also makes for more comprehensive test sets that require diverse training to succeed on. Finally, we use information theory to show that reduction in spurious correlations between substructures may be one reason why diverse training sets improve generalization.
Impact of Pretraining Term Frequencies on Few-Shot Reasoning
Feb 15, 2022



Pretrained Language Models (LMs) have demonstrated ability to perform numerical reasoning by extrapolating from a few examples in few-shot settings. However, the extent to which this extrapolation relies on robust reasoning is unclear. In this paper, we investigate how well these models reason with terms that are less frequent in the pretraining data. In particular, we examine the correlations between the model performance on test instances and the frequency of terms from those instances in the pretraining data. We measure the strength of this correlation for a number of GPT-based language models (pretrained on the Pile dataset) on various numerical deduction tasks (e.g., arithmetic and unit conversion). Our results consistently demonstrate that models are more accurate on instances whose terms are more prevalent, in some cases above $70\%$ (absolute) more accurate on the top 10\% frequent terms in comparison to the bottom 10\%. Overall, although LMs exhibit strong performance at few-shot numerical reasoning tasks, our results raise the question of how much models actually generalize beyond pretraining data, and we encourage researchers to take the pretraining data into account when interpreting evaluation results.
Evidentiality-guided Generation for Knowledge-Intensive NLP Tasks
Dec 16, 2021
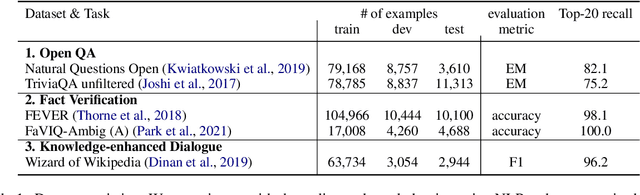
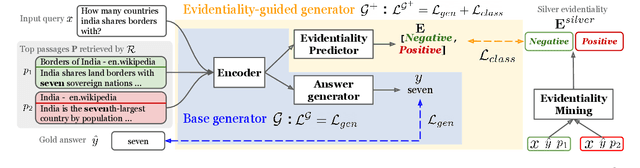
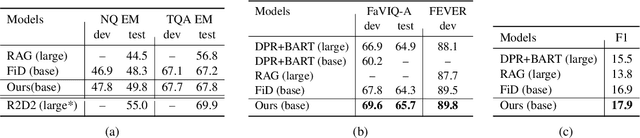
Retrieval-augmented generation models have shown state-of-the-art performance across many knowledge-intensive NLP tasks such as open question answering and fact verification. These models are trained to generate the final output given the retrieved passages, which can be irrelevant to the original query, leading to learning spurious cues or answer memorization. This work introduces a method to incorporate evidentiality of passages -- whether a passage contains correct evidence to support the output -- into training the generator. We introduce a multi-task learning framework to jointly generate the final output and predict the evidentiality of each passage, leveraging a new task-agnostic method to obtain {\it silver} evidentiality labels for supervision. Our experiments on five datasets across three knowledge-intensive tasks show that our new evidentiality-guided generator significantly outperforms its direct counterpart with the same-size model and advances the state of the art on FaVIQ-Ambig. We attribute these improvements to both the auxiliary multi-task learning and silver evidentiality mining techniques.
COVR: A test-bed for Visually Grounded Compositional Generalization with real images
Sep 22, 2021


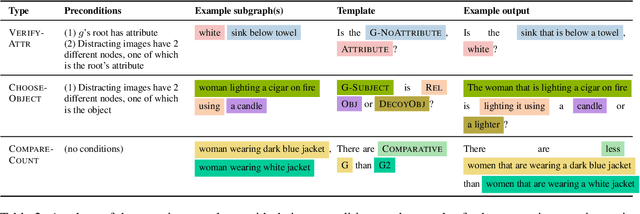
While interest in models that generalize at test time to new compositions has risen in recent years, benchmarks in the visually-grounded domain have thus far been restricted to synthetic images. In this work, we propose COVR, a new test-bed for visually-grounded compositional generalization with real images. To create COVR, we use real images annotated with scene graphs, and propose an almost fully automatic procedure for generating question-answer pairs along with a set of context images. COVR focuses on questions that require complex reasoning, including higher-order operations such as quantification and aggregation. Due to the automatic generation process, COVR facilitates the creation of compositional splits, where models at test time need to generalize to new concepts and compositions in a zero- or few-shot setting. We construct compositional splits using COVR and demonstrate a myriad of cases where state-of-the-art pre-trained language-and-vision models struggle to compositionally generalize.