 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing human and language models sentence processing difficulties on complex structures
Oct 08, 2025Large language models (LLMs) that fluently converse with humans are a reality - but do LLMs experience human-like processing difficulties? We systematically compare human and LLM sentence comprehension across seven challenging linguistic structures. We collect sentence comprehension data from humans and five families of state-of-the-art LLMs, varying in size and training procedure in a unified experimental framework. Our results show LLMs overall struggle on the target structures, but especially on garden path (GP) sentences. Indeed, while the strongest models achieve near perfect accuracy on non-GP structures (93.7% for GPT-5), they struggle on GP structures (46.8% for GPT-5). Additionally, when ranking structures based on average performance, rank correlation between humans and models increases with parameter count. For each target structure, we also collect data for their matched baseline without the difficult structure. Comparing performance on the target vs. baseline sentences, the performance gap observed in humans holds for LLMs, with two exceptions: for models that are too weak performance is uniformly low across both sentence types, and for models that are too strong the performance is uniformly high. Together, these reveal convergence and divergence in human and LLM sentence comprehension, offering new insights into the similarity of humans and LLMs.
Cost-Optimal Active AI Model Evaluation
Jun 09, 2025The development lifecycle of generative AI systems requires continual evaluation, data acquisition, and annotation, which is costly in both resources and time. In practice, rapid iteration often makes it necessary to rely on synthetic annotation data because of the low cost, despite the potential for substantial bias. In this paper, we develop novel, cost-aware methods for actively balancing the use of a cheap, but often inaccurate, weak rater -- such as a model-based autorater that is designed to automatically assess the quality of generated content -- with a more expensive, but also more accurate, strong rater alternative such as a human. More specifically, the goal of our approach is to produce a low variance, unbiased estimate of the mean of the target "strong" rating, subject to some total annotation budget. Building on recent work in active and prediction-powered statistical inference, we derive a family of cost-optimal policies for allocating a given annotation budget between weak and strong raters so as to maximize statistical efficiency. Using synthetic and real-world data, we empirically characterize the conditions under which these policies yield improvements over prior methods. We find that, especially in tasks where there is high variability in the difficulty of examples, our policies can achieve the same estimation precision at a far lower total annotation budget than standard evaluation methods.
Don't lie to your friends: Learning what you know from collaborative self-play
Mar 18, 2025To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
When the LM misunderstood the human chuckled: Analyzing garden path effects in humans and language models
Feb 13, 2025Modern Large Language Models (LLMs) have shown human-like abilities in many language tasks, sparking interest in comparing LLMs' and humans' language processing. In this paper, we conduct a detailed comparison of the two on a sentence comprehension task using garden-path constructions, which are notoriously challenging for humans. Based on psycholinguistic research, we formulate hypotheses on why garden-path sentences are hard, and test these hypotheses on human participants and a large suite of LLMs using comprehension questions. Our findings reveal that both LLMs and humans struggle with specific syntactic complexities, with some models showing high correlation with human comprehension. To complement our findings, we test LLM comprehension of garden-path constructions with paraphrasing and text-to-image generation tasks, and find that the results mirror the sentence comprehension question results, further validating our findings on LLM understanding of these constructions.
InfAlign: Inference-aware language model alignment
Dec 27, 2024Language model alignment has become a critical step in training modern generative language models. The goal of alignment is to finetune a reference model such that the win rate of a sample from the aligned model over a sample from the reference model is high, subject to a KL divergence constraint. Today, we are increasingly using inference-time algorithms (e.g., Best-of-N, controlled decoding, tree search) to decode from language models rather than standard sampling. However, the alignment objective does not capture such inference-time decoding procedures. We show that the existing alignment framework is sub-optimal in view of such inference-time methods. We then modify the alignment objective and propose a framework for inference-aware alignment (IAPO). We prove that for any inference-time decoding algorithm, the optimal solution that optimizes the inference-time win rate of the aligned policy against the reference policy is the solution to the typical RLHF problem with a transformation of the reward. This motivates us to provide the KL-regularized calibrate-and-transform RL (CTRL) algorithm to solve this problem, which involves a reward calibration step and a KL-regularized reward maximization step with a transformation of the calibrated reward. We particularize our study to two important inference-time strategies: best-of-N sampling and best-of-N jailbreaking, where N responses are sampled from the model and the one with the highest or lowest reward is selected. We propose specific transformations for these strategies and demonstrate that our framework offers significant improvements over existing state-of-the-art methods for language model alignment. Empirically, we outperform baselines that are designed without taking inference-time decoding into consideration by 8-12% and 4-9% on inference-time win rates over the Anthropic helpfulness and harmlessness dialog benchmark datasets.
ALTA: Compiler-Based Analysis of Transformers
Oct 23, 2024
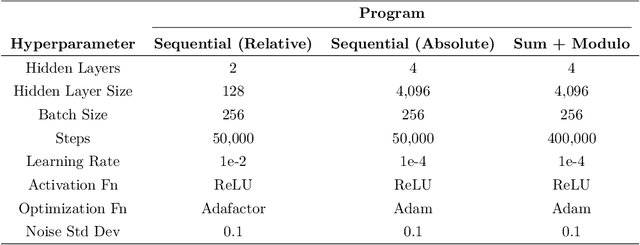

We propose a new programming language called ALTA and a compiler that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by Weiss et al. (2021), and Tracr (Lindner et al., 2023), a compiler from RASP programs to Transformer weights. ALTA complements and extends this prior work, offering the ability to express loops and to compile programs to Universal Transformers, among other advantages. ALTA allows us to constructively show how Transformers can represent length-invariant algorithms for computing parity and addition, as well as a solution to the SCAN benchmark of compositional generalization tasks, without requiring intermediate scratchpad decoding steps. We also propose tools to analyze cases where the expressibility of an algorithm is established, but end-to-end training on a given training set fails to induce behavior consistent with the desired algorithm. To this end, we explore training from ALTA execution traces as a more fine-grained supervision signal. This enables additional experiments and theoretical analyses relating the learnability of various algorithms to data availability and modeling decisions, such as positional encodings. We make the ALTA framework -- language specification, symbolic interpreter, and weight compiler -- available to the community to enable further applications and insights.
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024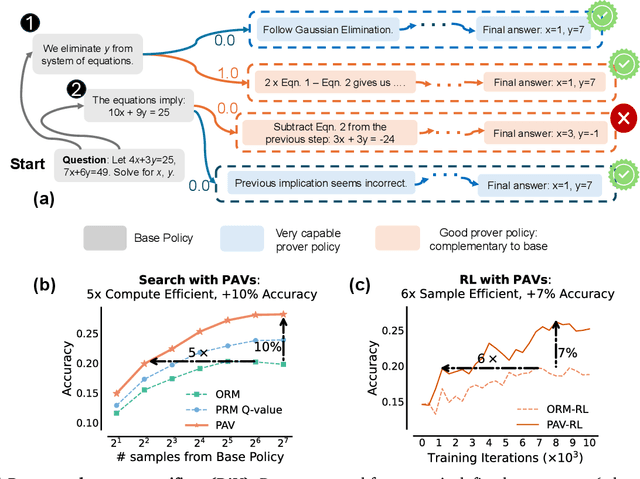
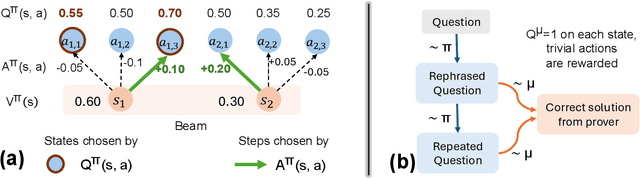
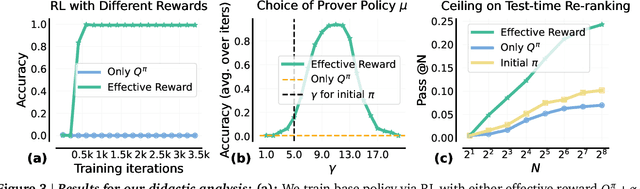
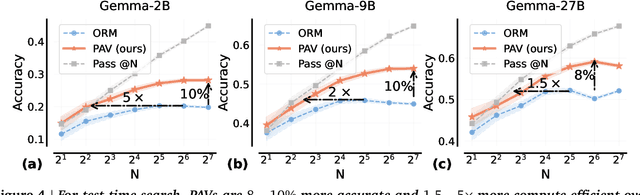
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?
Jul 22, 2024Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses. We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points. While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero. Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze failures of current systems and highlight that web navigation remains a major challenge.
From Loops to Oops: Fallback Behaviors of Language Models Under Uncertainty
Jul 08, 2024

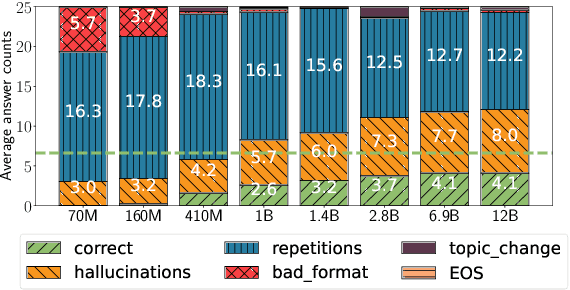
Large language models (LLMs) often exhibit undesirable behaviors, such as hallucinations and sequence repetitions. We propose to view these behaviors as fallbacks that models exhibit under uncertainty, and investigate the connection between them. We categorize fallback behaviors -- sequence repetitions, degenerate text, and hallucinations -- and extensively analyze them in models from the same family that differ by the amount of pretraining tokens, parameter count, or the inclusion of instruction-following training. Our experiments reveal a clear and consistent ordering of fallback behaviors, across all these axes: the more advanced an LLM is (i.e., trained on more tokens, has more parameters, or instruction-tuned), its fallback behavior shifts from sequence repetitions, to degenerate text, and then to hallucinations. Moreover, the same ordering is observed throughout a single generation, even for the best-performing models; as uncertainty increases, models shift from generating hallucinations to producing degenerate text and then sequence repetitions. Lastly, we demonstrate that while common decoding techniques, such as random sampling, might alleviate some unwanted behaviors like sequence repetitions, they increase harder-to-detect hallucinations.
Robust Preference Optimization through Reward Model Distillation
May 29, 2024Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.